Prometheus and Grafana
تفاصيل العمل

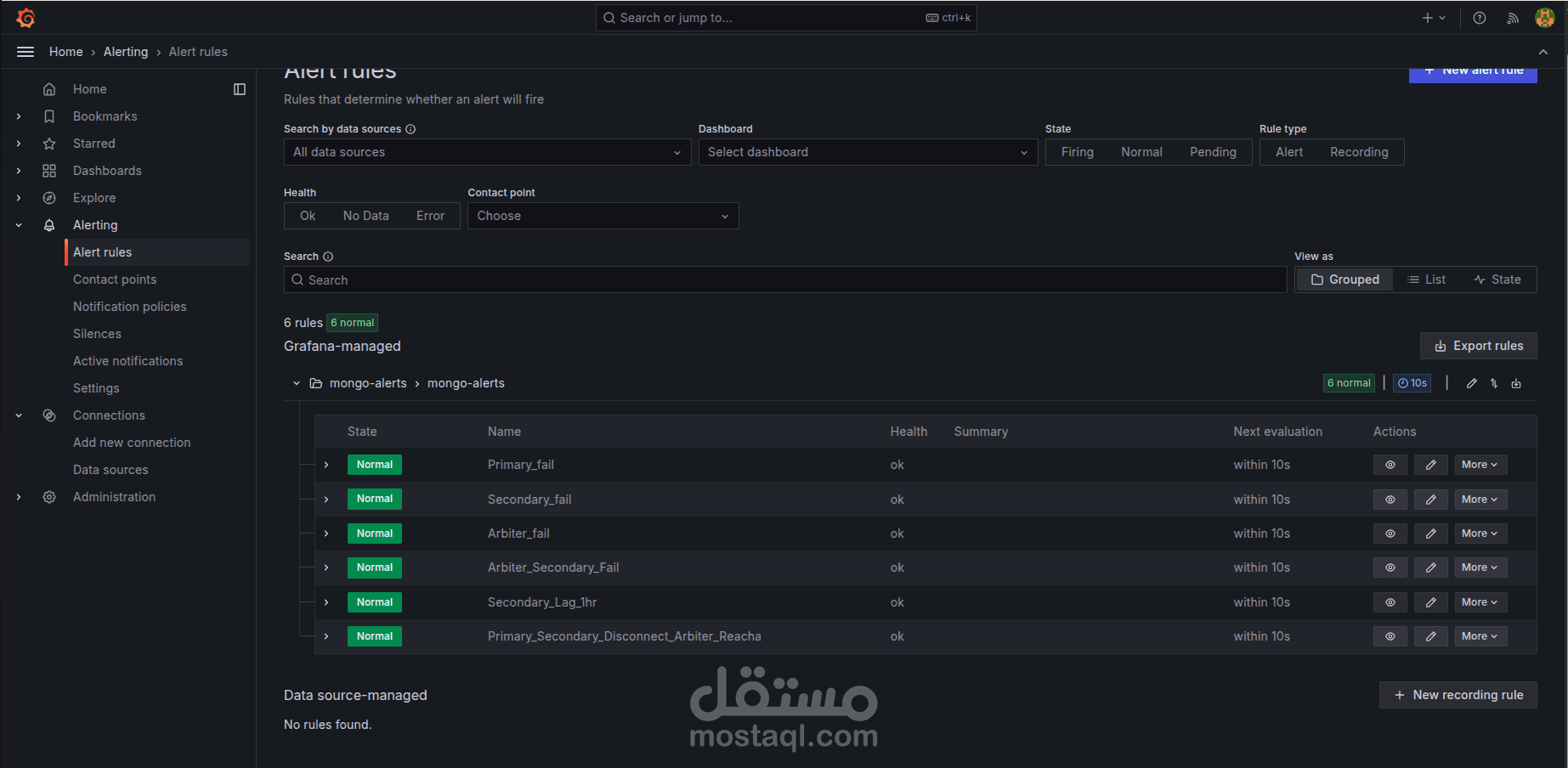
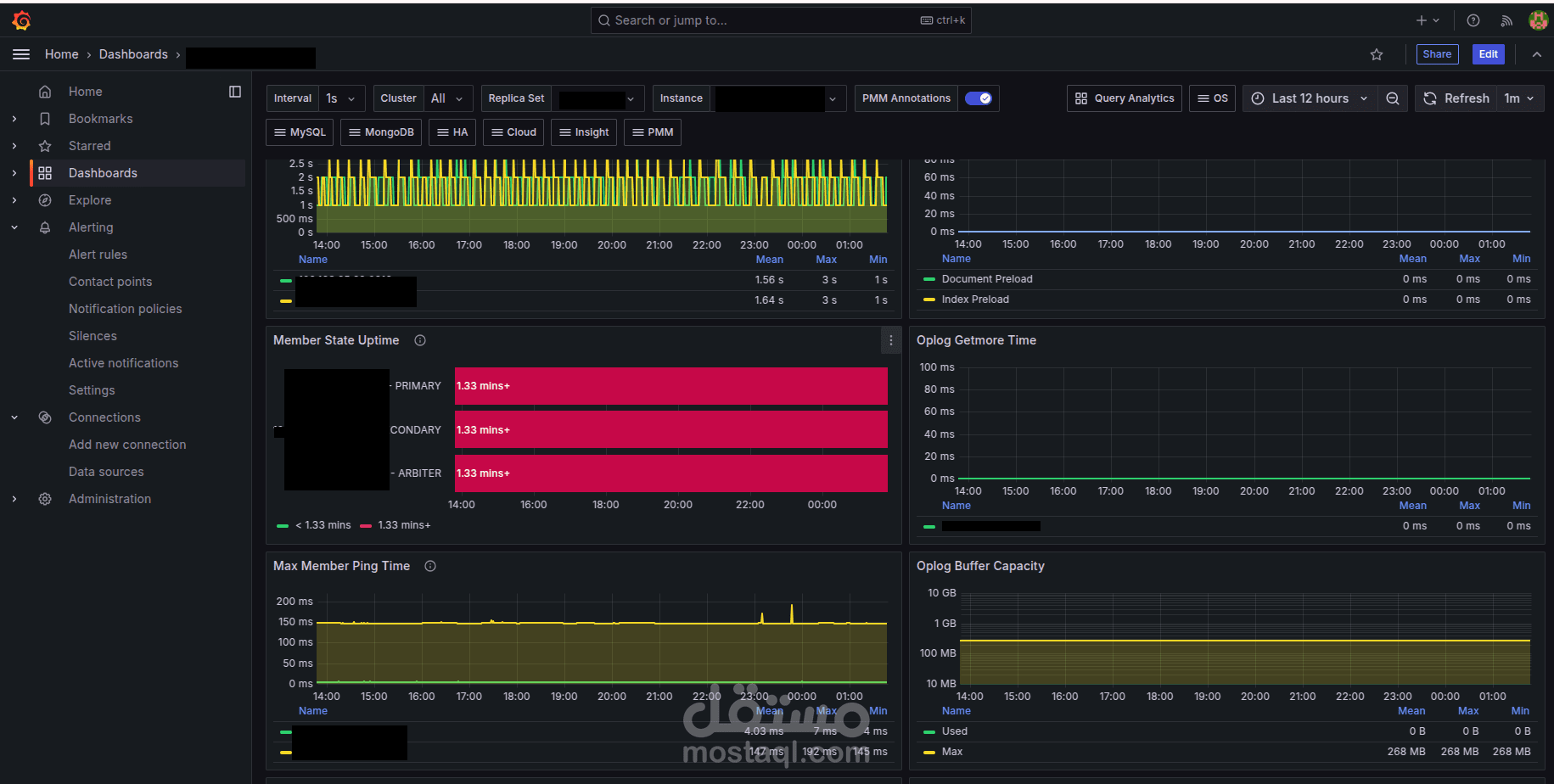
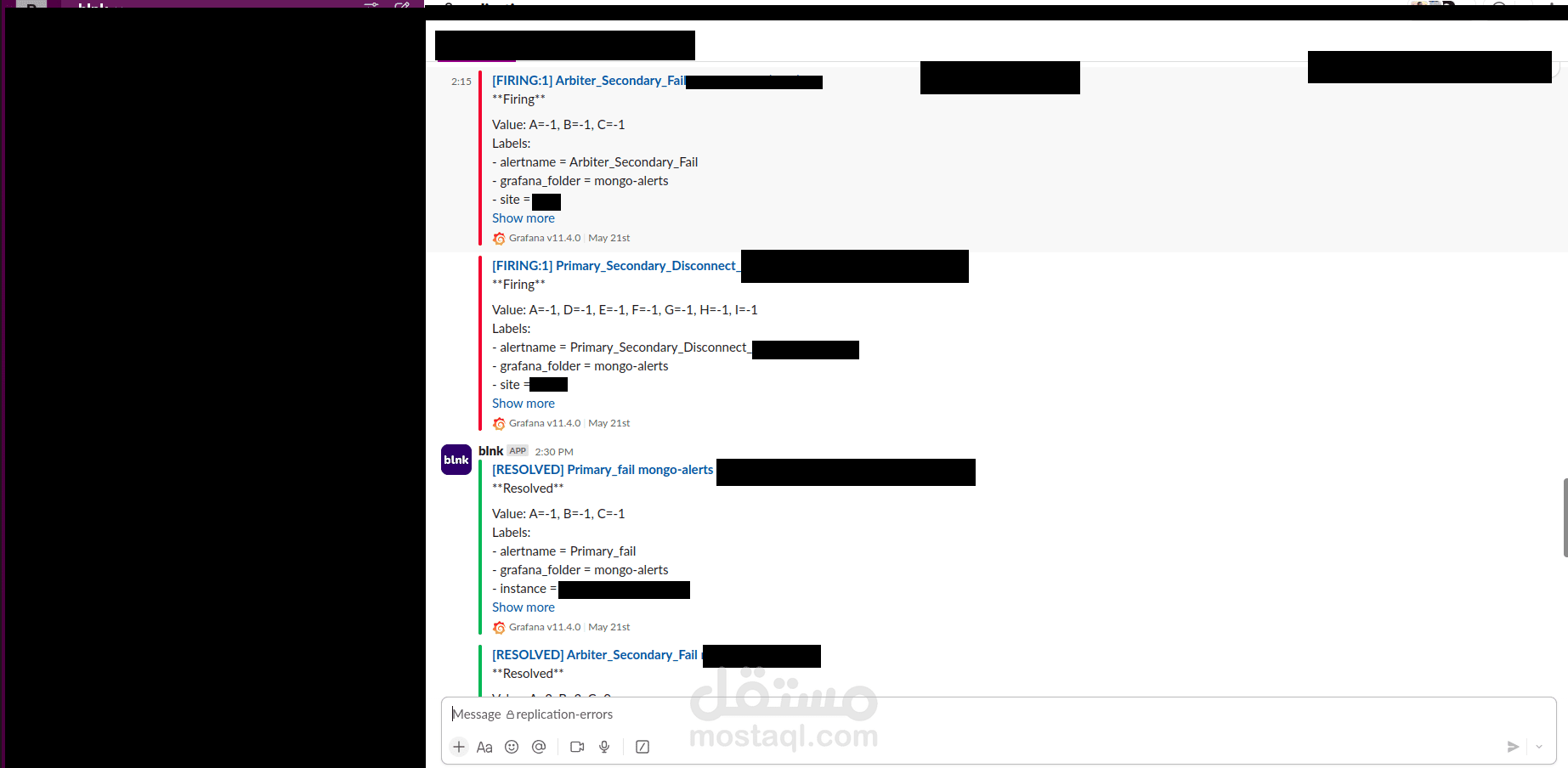
في هذا المشروع قمت بتنصيب وإعداد منصة مراقبة باستخدام Prometheus وGrafana لمتابعة قاعدة بيانات MongoDB التي تم إعدادها بنظام Replication، مع تهيئة نظام تنبيهات يتم إرساله مباشرة إلى قناة Slack لمتابعة الأعطال أو المشاكل.
1- إعداد قاعدة البيانات MongoDB:
a- إنشاء Cluster من MongoDB بنظام Replication لضمان التوافرية (High Availability) وحماية البيانات.
b- ضبط Primary وSecondary Nodes للتأكد من تكرار البيانات بشكل متزامن.
c- اختبار عملية الـ Failover للتأكد من جاهزية النظام عند سقوط أحد الـ Nodes.
2- إعداد Prometheus:
a- تنصيب Prometheus على خادم مخصص لمراقبة قاعدة البيانات.
b- ربط Prometheus مع MongoDB Exporter للحصول على مؤشرات الأداء (Metrics) الخاصة بالـ Cluster.
c- جمع بيانات مثل (حالة الـ Replication، زمن الاستجابة، حجم البيانات، استهلاك الذاكرة والمعالج).
d- كتابة قواعد (Alerting Rules) لمراقبة الحالات الحرجة مثل توقف الـ Replication أو ارتفاع الاستهلاك.
3- إعداد Grafana:
a- تنصيب Grafana وربطه مع Prometheus كمصدر بيانات (Data Source).
b- إنشاء Dashboards تفاعلية لمراقبة حالة الـ MongoDB Cluster.
c- تصميم لوحات لعرض مؤشرات رئيسية (Replication Lag، Primary/Secondary Status، Query Performance).
d- تمكين نظام التنبيهات من خلال Grafana وربطه بقناة Slack.
4- إعداد التنبيهات (Alerts):
a- ربط Prometheus Alertmanager مع Slack عبر Webhook.
b- إعداد قنوات تنبيه لإرسال إشعارات في حال حدوث أعطال أو بطء في الأداء.
c- اختبار إرسال التنبيهات إلى Slack للتأكد من وصولها بشكل لحظي.