تصنيف بيانات Iris باستخدام خوارزمية Decision Tree في Python
تفاصيل العمل

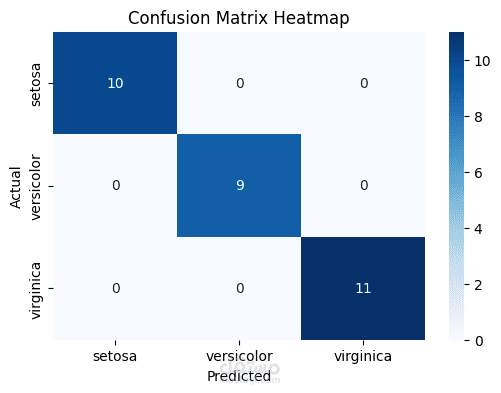
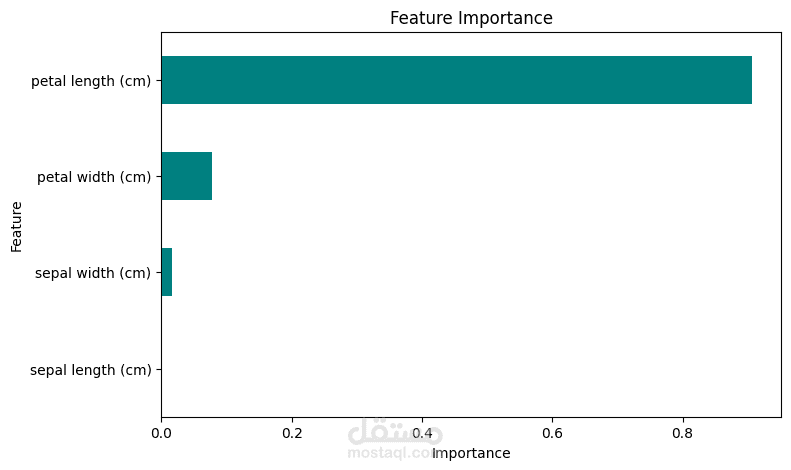
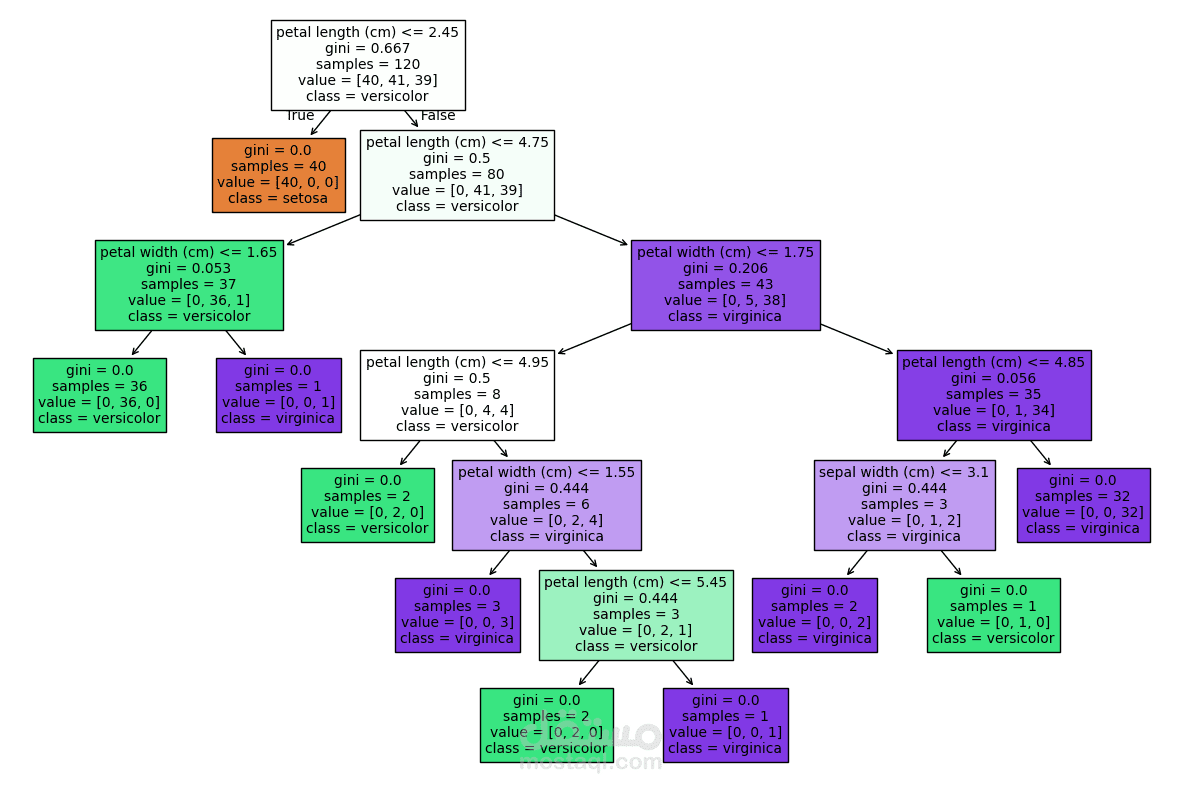
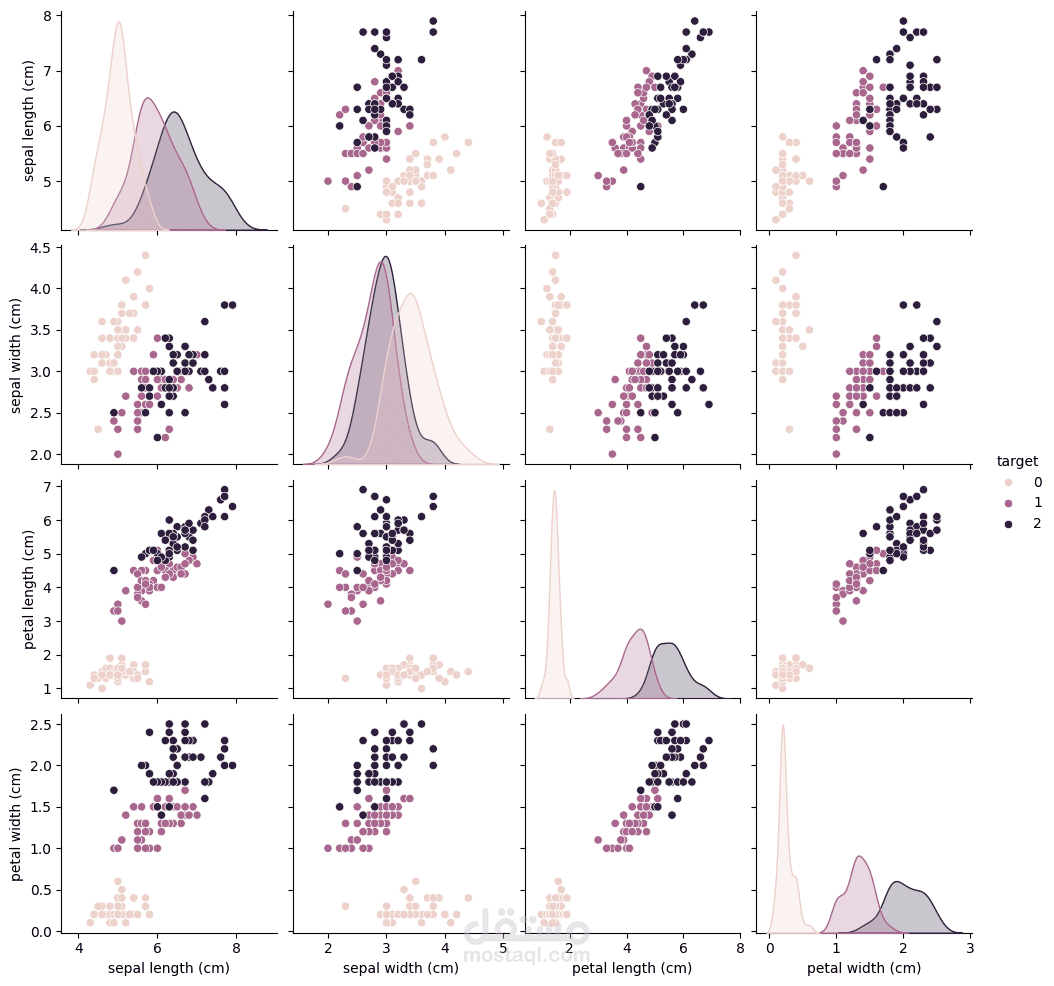
في هذا المشروع قمت بتطبيق تقنيات تحليل البيانات وتعلم الآلة على مجموعة بيانات Iris الشهيرة، بهدف بناء نموذج قادر على تصنيف الأنواع المختلفة من الزهور (Setosa, Versicolor, Virginica) بدقة عالية.
خطوات العمل:
استكشاف البيانات (EDA) باستخدام Pandas و Seaborn لمعرفة خصائص كل فئة.
تقسيم البيانات إلى تدريب واختبار لضمان دقة التقييم.
بناء نموذج Decision Tree Classifier باستخدام مكتبة scikit-learn.
تقييم النموذج من خلال Accuracy, Confusion Matrix, Classification Report.
إنشاء رسومات توضيحية:
شجرة القرار (Decision Tree Plot).
مصفوفة الالتباس (Confusion Matrix Heatmap).
أهمية الخصائص (Feature Importance Plot).
النتائج:
حقق النموذج دقة وصلت إلى %100 على بيانات الاختبار.
أظهر التحليل أن أهم الخصائص المؤثرة في التصنيف هي Petal length و Petal width.
المشروع يوضح خطوات عملية كاملة من إعداد البيانات → بناء النموذج → التقييم → استخراج الرؤى.