تجميع بيانات الويب (Web Scraping)
تفاصيل العمل
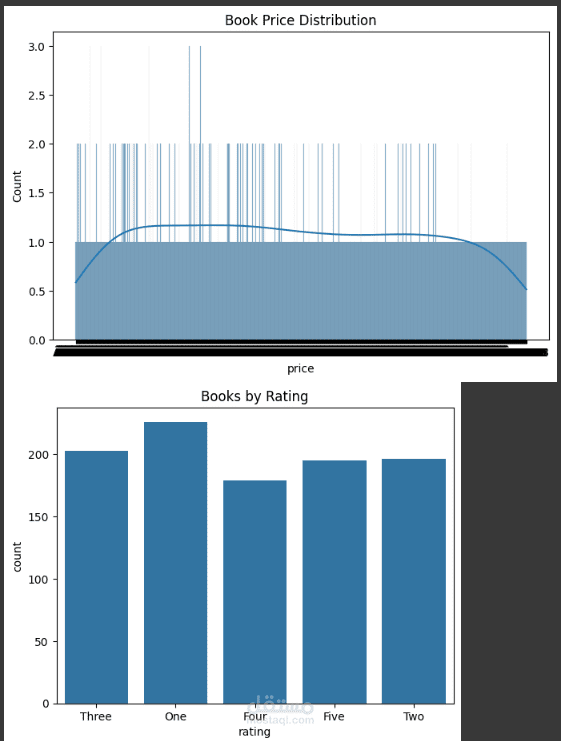
اسم المشروع: تجميع بيانات الويب (Web Scraping)
فكرة المشروع:
استخراج بيانات كتب من موقع تجريبي (Books to Scrape) تلقائيًا لجمع معلومات مثل العنوان، السعر، مدى التوفر، والتقييم، على عدة صفحات.
الأدوات المستخدمة:
Python، مكتبة Requests، مكتبة BeautifulSoup، Pandas لمعالجة البيانات وتنظيمها، وتنظيفها.
ما تم إنجازه:
• جمع أكثر من 1000 كتاب عبر صفحات متعددة.
• تقييم جودة البيانات من خلال إزالة التكرارات، التعامل مع القيم الفارغة، وتحويل الصيغ لتكون رقمية حيث يلزم.
• إنشاء ملف بيانات نظيف جاهز للتحليل أو للنمذجة.
القيمة المضافة:
هذا المشروع يُظهر قدرتي على التعامل مع بيانات غير مرتبة، تحويلها إلى dataset جاهز يمكن استخدامه في عرض بصري، تحليل متقدم، أو بناء نماذج تنبؤية.