SMS (Spam Vs. Ham)
تفاصيل العمل

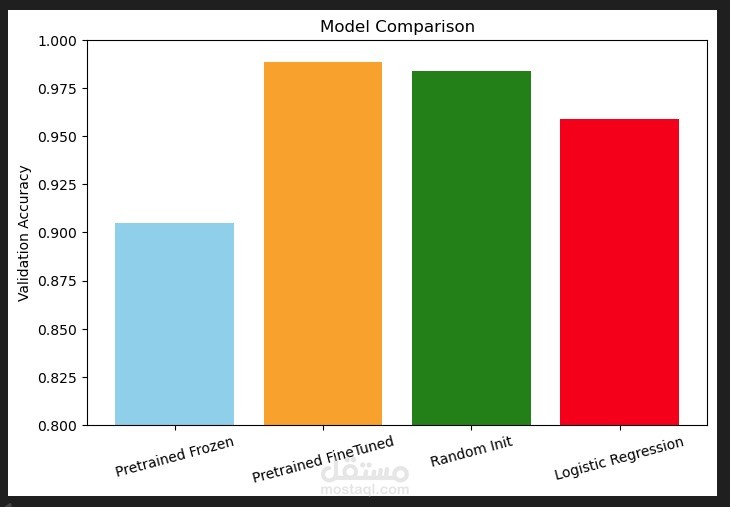
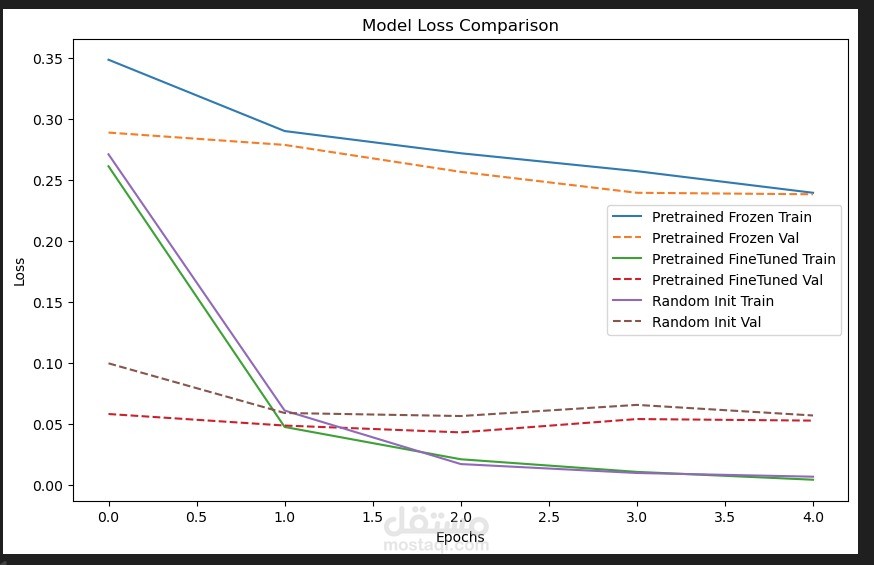
هذا المشروع يهدف إلى بناء نظام تصنيف رسائل SMS (مثلاً: Spam vs. Ham) باستخدام تقنيات التعلم العميق والتعلم التقليدي، ثم إجراء مقارنة بين النماذج المختلفة لتقييم الأداء.
النماذج المستخدمة:
Pretrained Embedding Model
اعتمد على word embeddings مُدرَّبة مسبقًا.
تم تثبيت أوزان الـ Embedding layer (trainable=False) للحفاظ على المعرفة العامة المكتسبة مسبقًا.
يحتوي على Bidirectional LSTM لمعالجة النص في الاتجاهين، يليه GlobalMaxPooling و Dense layers للتصنيف.
Fine-tuned Embedding Model
نفس البنية السابقة لكن مع جعل الـ Embedding قابلة للتدريب (trainable=True).
هذا يسمح بتخصيص الـ embeddings لتناسب طبيعة رسائل SMS، ما يزيد من الدقة على الداتا الخاصة.
Random Embedding Model
يبدأ من أوزان عشوائية للـ embeddings (بدون استخدام pretrained).
يتعلم التمثيلات أثناء التدريب فقط.
يمثل Baseline للمقارنة مع النماذج التي استخدمت knowledge مسبق.
Logistic Regression Model
نموذج إحصائي تقليدي يُستخدم كـ baseline إضافي.
يعتمد على خصائص مُستخرجة يدويًا أو TF-IDF من الرسائل.
يوفر مرجعًا لتوضيح قوة النماذج العميقة مقارنة بالطرق الكلاسيكية.