Image Captioning Using LSTM and CNN
تفاصيل العمل


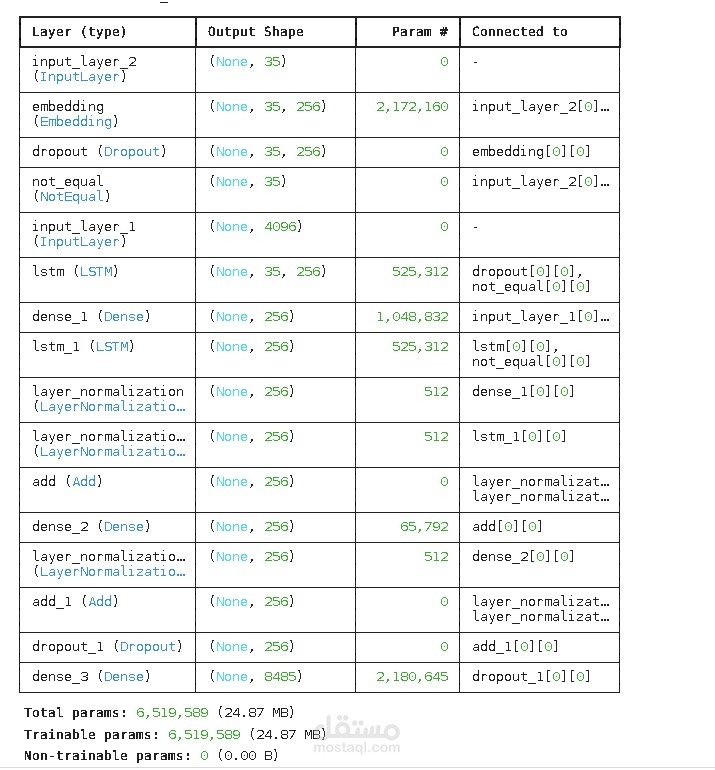
هذا المشروع يقدّم نظام توليد أوصاف للصور (Image Captioning) بالاعتماد على دمج الشبكات العصبية الالتفافية (CNNs) مع الشبكات العصبية المتكررة (RNNs) لتوليد جمل وصفية تلقائية للصور.
استخراج الخصائص (Encoder):
تم استخدام نموذج VGG16 المُدرَّب مسبقًا لاستخراج متجه خصائص (Feature Vector) بأبعاد 4096 من الصور، والذي يمثل السمات البصرية عالية المستوى.
معالجة التسلسل النصي (Decoder):
تم تمرير تسلسل الكلمات عبر طبقة Embedding ثم شبكتين LSTM متتاليتين (Stacked LSTM) مع إضافة Layer Normalization و Dropout صغير لتحسين التعميم واستقرار التدريب.
الدمج والـ Residual Connections:
يتم دمج خصائص الصورة مع تمثيل النص من خلال عملية Additive Fusion، مع إضافة وصلات Residual Connections لتحسين تدفق التدرجات وتسريع التدريب.
التنظيم والتحسين (Regularization & Optimization):
تم استخدام L2 Regularization و Dropout لتقليل فرط التعلّم (Overfitting).
التدريب تم باستخدام خوارزمية Adam مع Categorical Crossentropy مضاف إليها Label Smoothing للحصول على استقرار أكبر.
تم استخدام Callbacks مثل (ReduceLROnPlateau و EarlyStopping) لرفع كفاءة عملية التدريب.
المخرجات:
الطبقة الأخيرة عبارة عن Dense مع Softmax للتنبؤ بالكلمة التالية في الوصف، وبذلك يولّد النظام جُملاً وصفية طبيعية للصور المدخلة.