تحليل بيانات ركاب Titanic وبناء نماذج للتنبؤ بالبقاء
تفاصيل العمل

تم العمل على مجموعة بيانات Titanic الشهيرة بهدف تحليل خصائص الركاب والتنبؤ باحتمالية نجاتهم باستخدام تقنيات تحليل البيانات والتعلم الآلي.
المهام المنجزة:
- تنظيف البيانات ومعالجتها: معالجة القيم المفقودة، حذف الأعمدة غير المفيدة، والتعامل مع البيانات النصية عبر الترميز (Encoding).
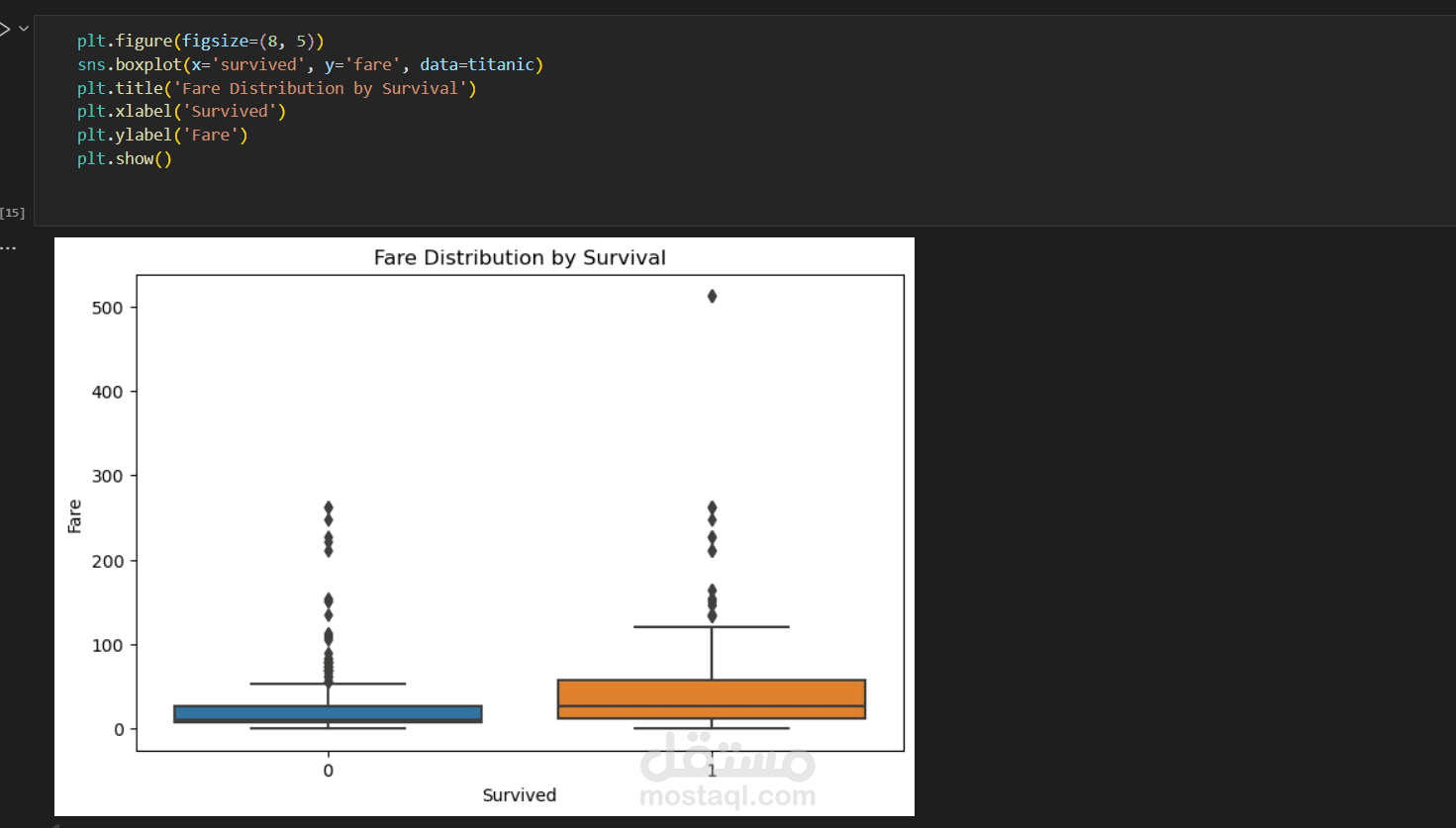
- التحليل الاستكشافي (EDA):
- دراسة توزيع الأعمار، العلاقة بين الدرجة (Pclass) ومعدل النجاة.
- تحليل أثر الأجرة (Fare) على النجاة.
- استكشاف تأثير حجم العائلة، مكان الصعود (Embark Town) على فرص النجاة.
- هندسة الخصائص (Feature Engineering): إنشاء متغيرات جديدة مثل:
تقسيم الركاب إلى مجموعات عمرية (Child, Teen, Adult, Senior).
حساب حجم العائلة.
متغير يحدد إن كان الراكب بمفرده (is_alone).
- إعداد البيانات للنمذجة: تطبيق StandardScaler للتوحيد القياسي، وترميز المتغيرات الفئوية باستخدام One-Hot Encoding.
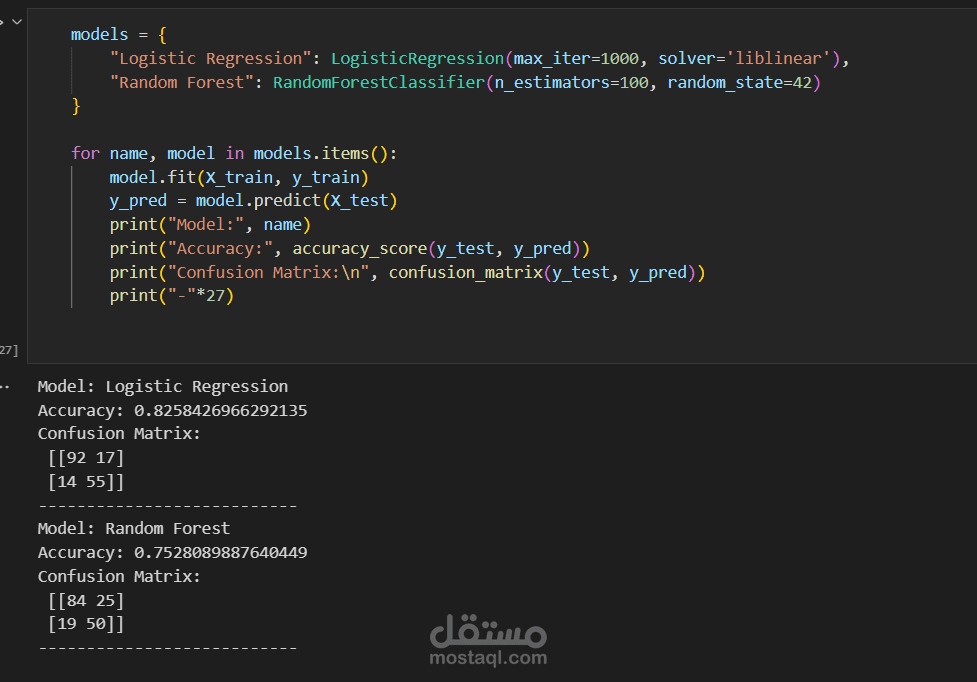
- النمذجة (Modeling):
Logistic Regression
Random Forest Classifier
- تقييم النماذج: باستخدام Accuracy و Confusion Matrix، مع مقارنة أداء كل نموذج.
النتيجة:
الحصول على نماذج تصنيفية قادرة على التنبؤ ببقاء الركاب بدقة جيدة، مع استخراج رؤى مهمة حول العوامل الأكثر تأثيرًا على النجاة (مثل الدرجة، العمر، الأجرة، وحجم العائلة).
التقنيات المستخدمة:
Python (Pandas, NumPy, Seaborn, Matplotlib, Scikit-learn)