Image-Classification
تفاصيل العمل
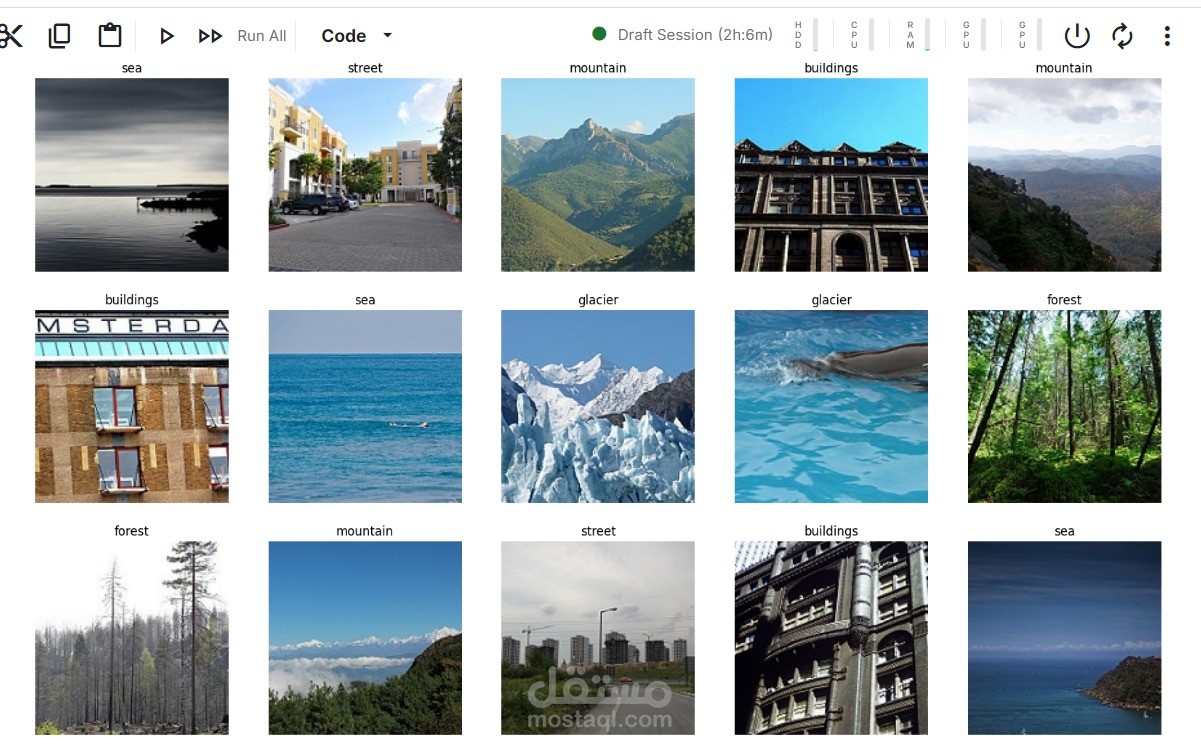
تدريب نموذج AlexNet أساسي من الصفر، ثم إعادة ضبط (Fine-tuning) لنموذج InceptionV3 المُدرَّب مسبقًا على مجموعة بيانات مكونة من 25 ألف صورة بأبعاد 150x150 موزعة على 6 فئات: (مباني، غابة، جليد، جبل، بحر، شارع).
بالإضافة إلى ذلك، تم توفير نشر بسيط باستخدام Streamlit لإجراء الاستدلال (Model Inference) بشكل تفاعلي.