Obesity Prediction - Python ML
تفاصيل العمل
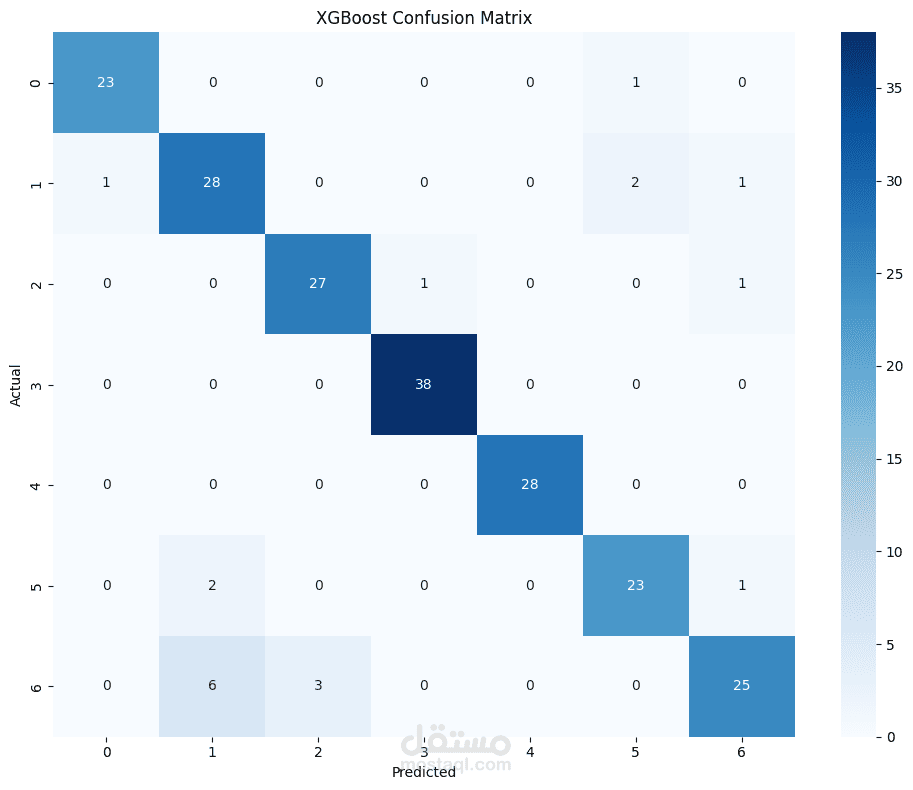
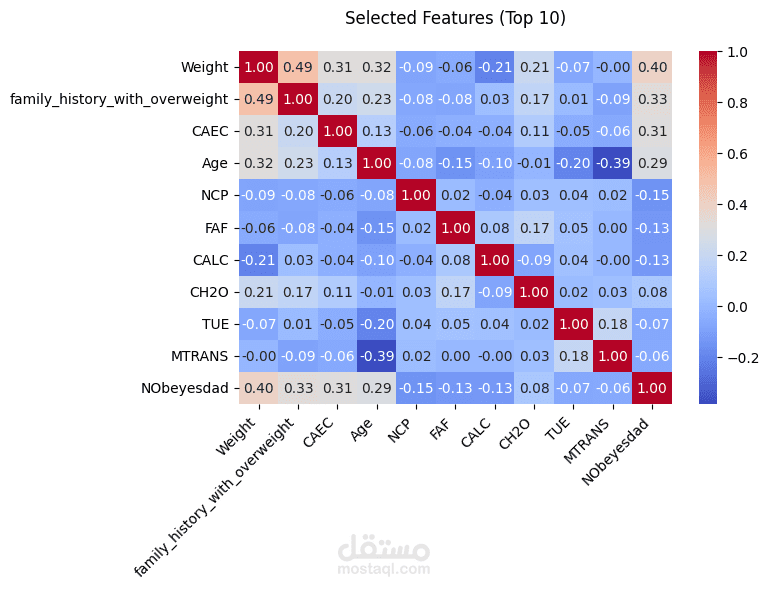
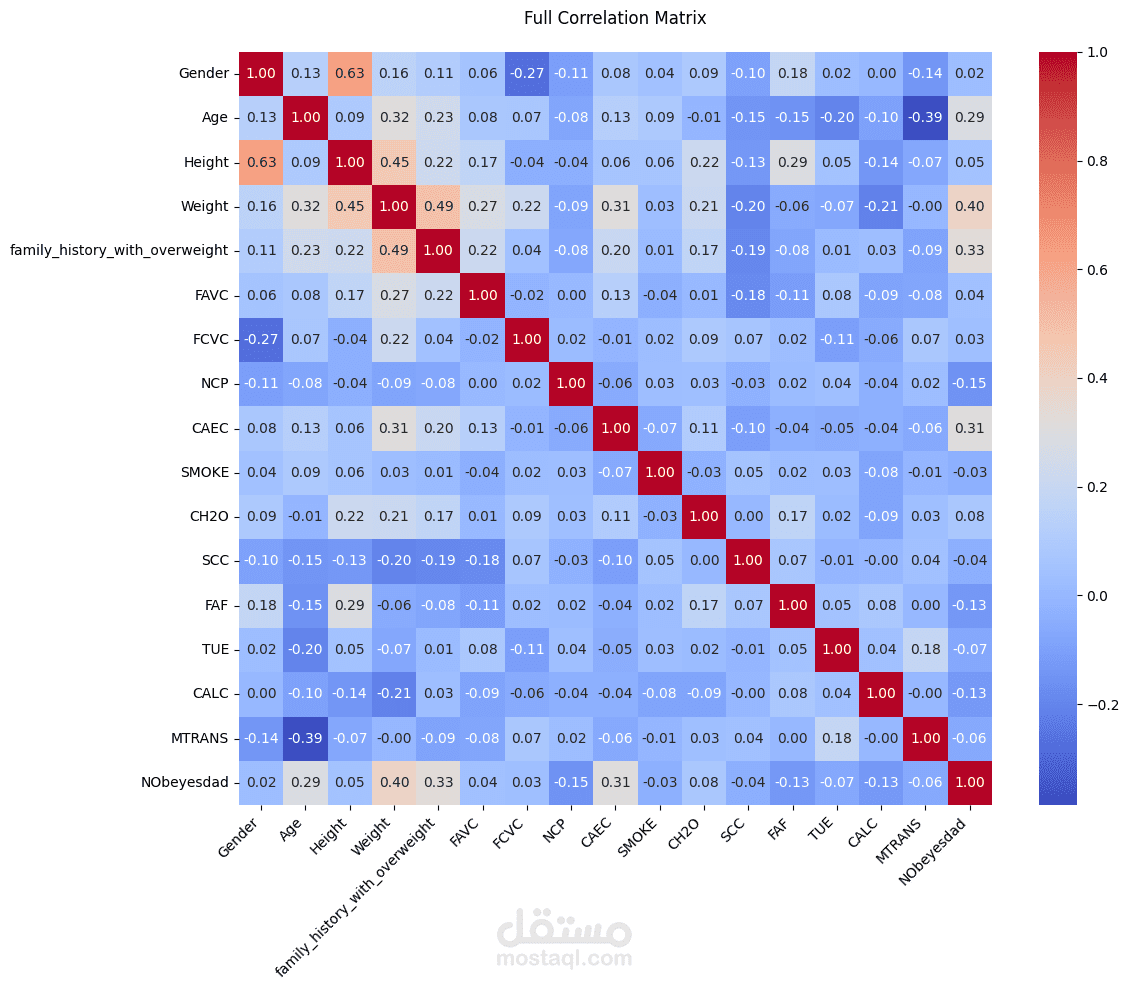
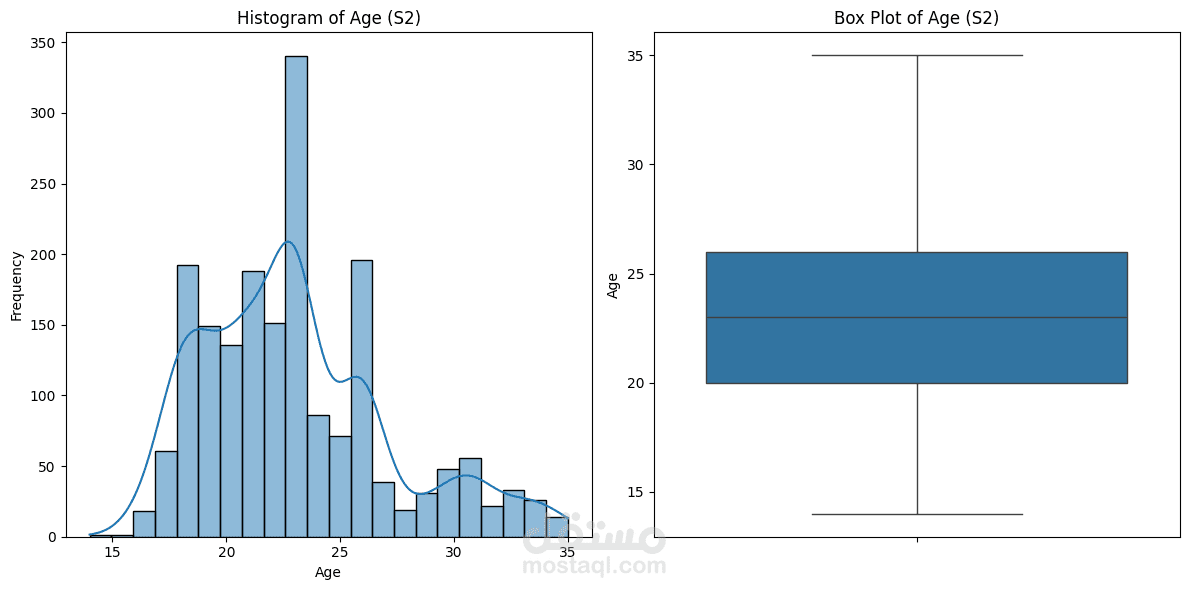
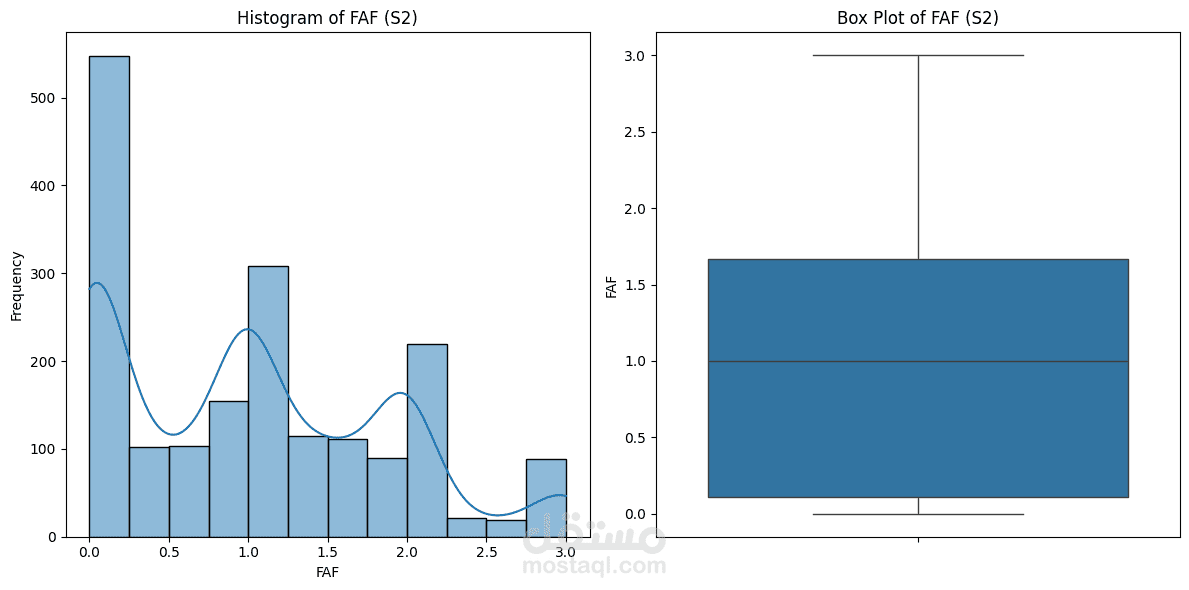
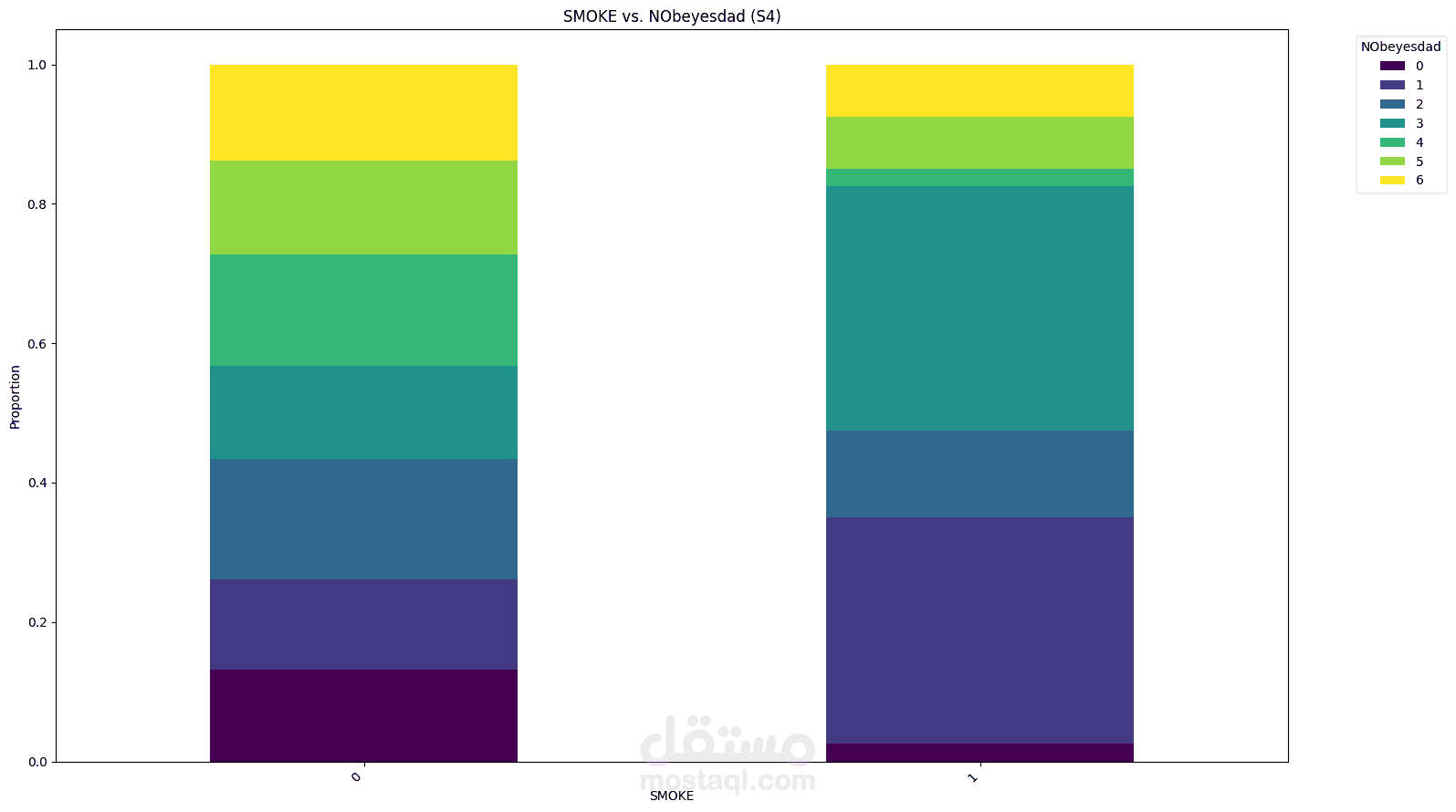
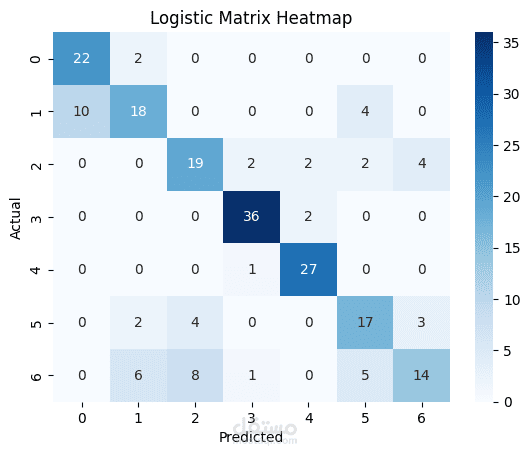
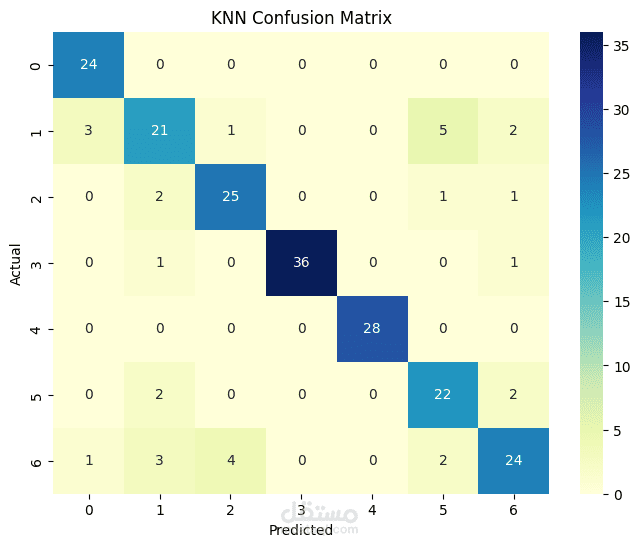
Obesity is a growing global health challenge, closely tied to conditions like diabetes and heart disease. This project focused on predicting obesity levels using Machine Learning models trained on lifestyle and demographic data.
Implementation Details:
Imported and cleaned the dataset using Pandas, handling missing values and encoding categorical features.
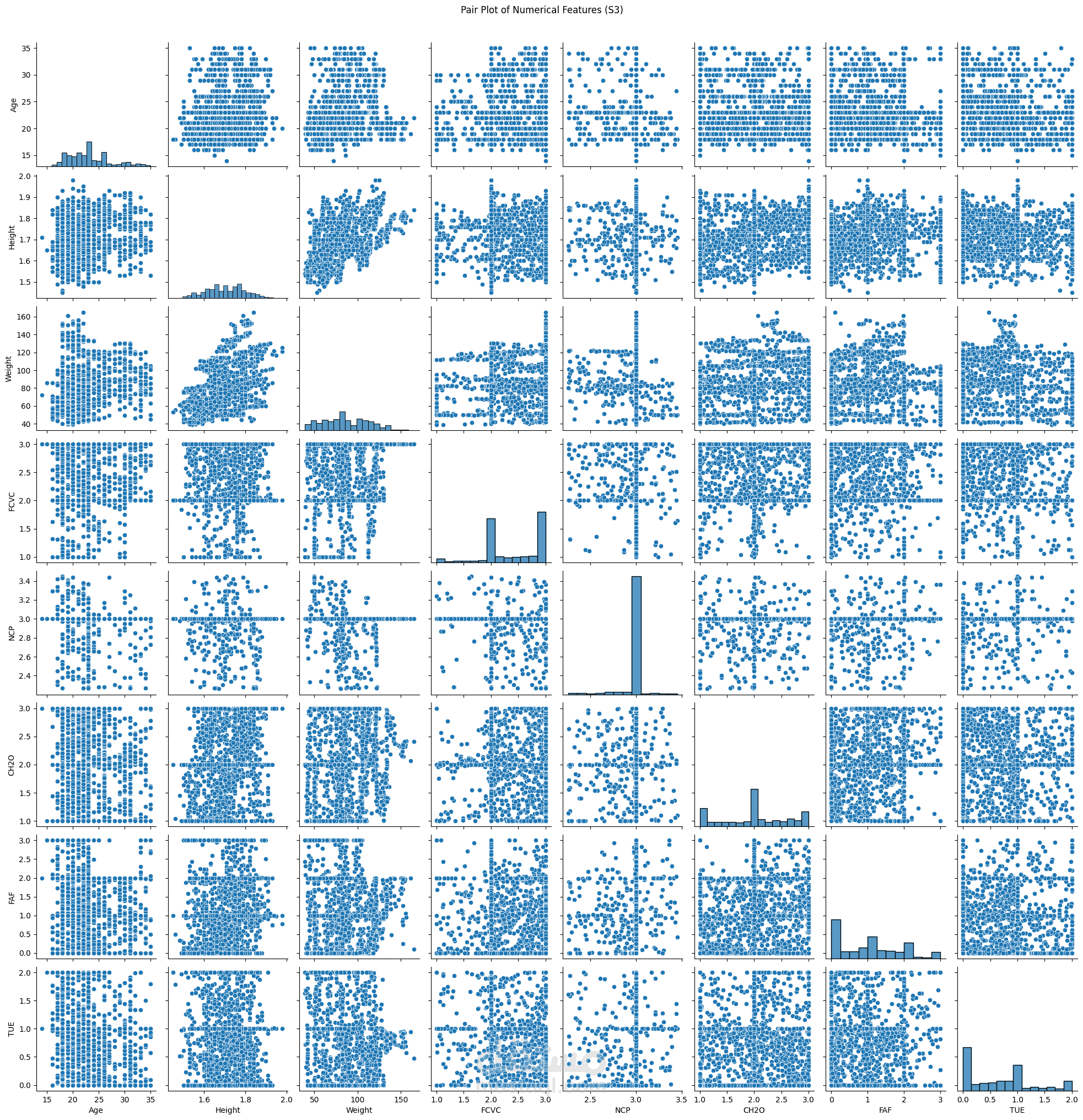
Performed exploratory data analysis (EDA) to uncover correlations between calorie intake, activity levels, and BMI.
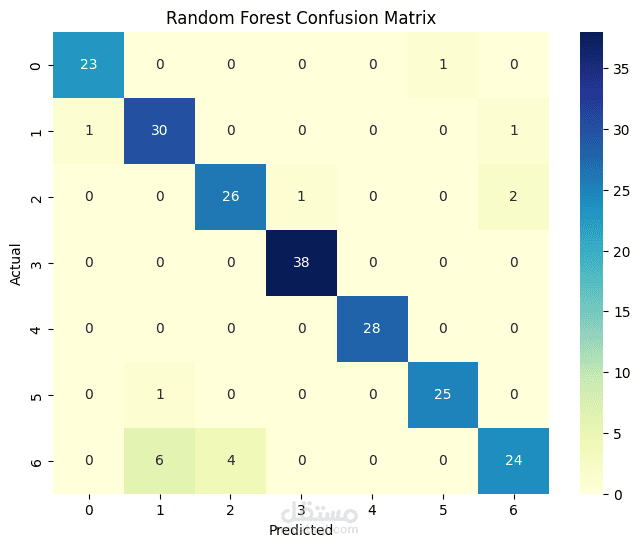
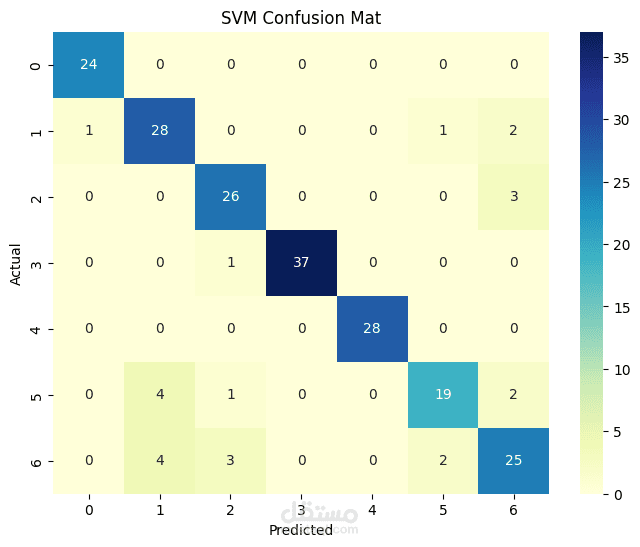
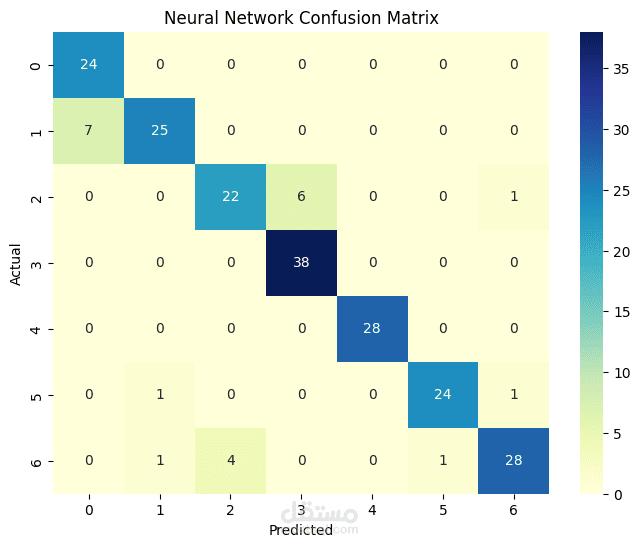
Applied several supervised learning algorithms including Logistic Regression, Random Forest, and K-Nearest Neighbors (KNN) using Scikit-learn.
Tuned hyperparameters to improve model performance using cv-search.
Visualized patterns using Matplotlib and Seaborn, including feature importance and class distribution.
Compared accuracy, precision, recall, and F1-score across models to determine the best approach.
Outcome:
Achieved high accuracies across all models, 85% on average. The results demonstrate how data-driven approaches can support early obesity risk detection and public health interventions.
Tools Used:
Python, Pandas, Scikit-learn, Matplotlib, Seaborn, Data Cleaning, Classification, Machine Learning, Predictive Modeling