استخراج بيانات وظائف من موقع Wuzzuf باستخدام لغه بايثون
تفاصيل العمل

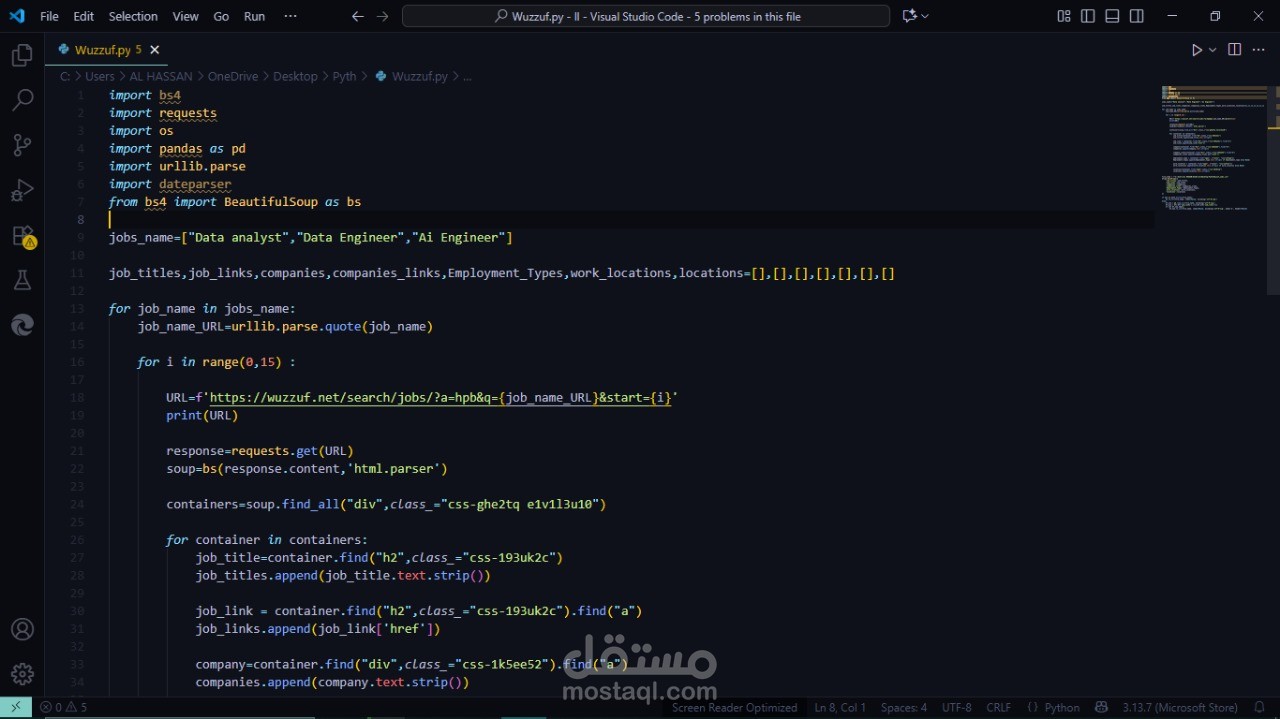
أشارك معكم تجربتي الصغيرة في مشروع Web Scraping الذي أنجزته الفترة الماضية باستخدام Python، والذي من خلاله قمت بعمل Scraping لموقع Wuzzuf للحصول على البيانات الخاصة بالوظائف ووضعها في ملف CSV، ومن ثم البدء في التعامل معها كمحلل بيانات (Data Analyst).
بدأت بدافع الفضول لمعرفة المزيد عن الوظائف على Wuzzuf، وقلت لنفسي: لماذا لا نقوم بعمل Scraping بشكل احترافي وجمع البيانات كلها في مكان واحد؟
استخدمت Python مع المكتبات التالية:
requests: لجلب صفحات الـ HTML
BeautifulSoup (bs4): لاستخراج العناصر المطلوبة من الصفحة
pandas: لتنظيم البيانات في DataFrame وعمل Export إلى ملف CSV
os: للتأكد من وجود الملف قبل إضافة أي بيانات جديدة وتجنب التكرار
urllib.parse: لعمل encoding لأي اسم وظيفة قبل إرساله في الـ URL
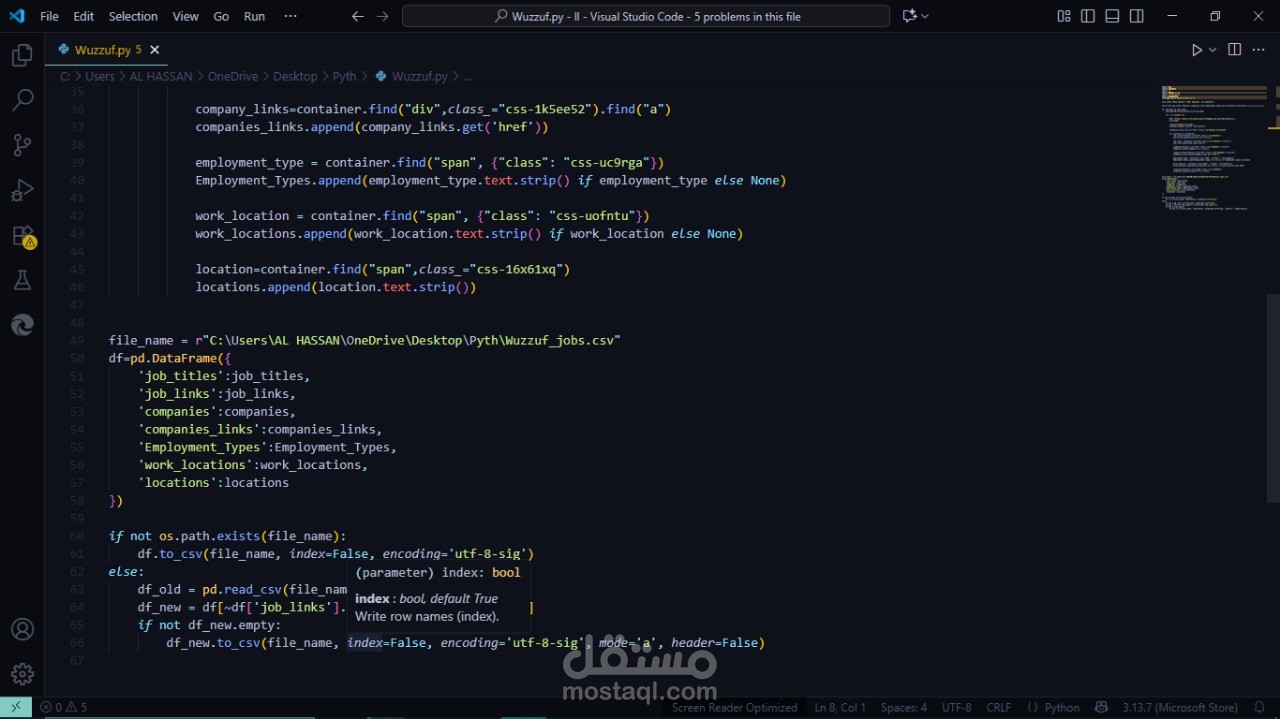
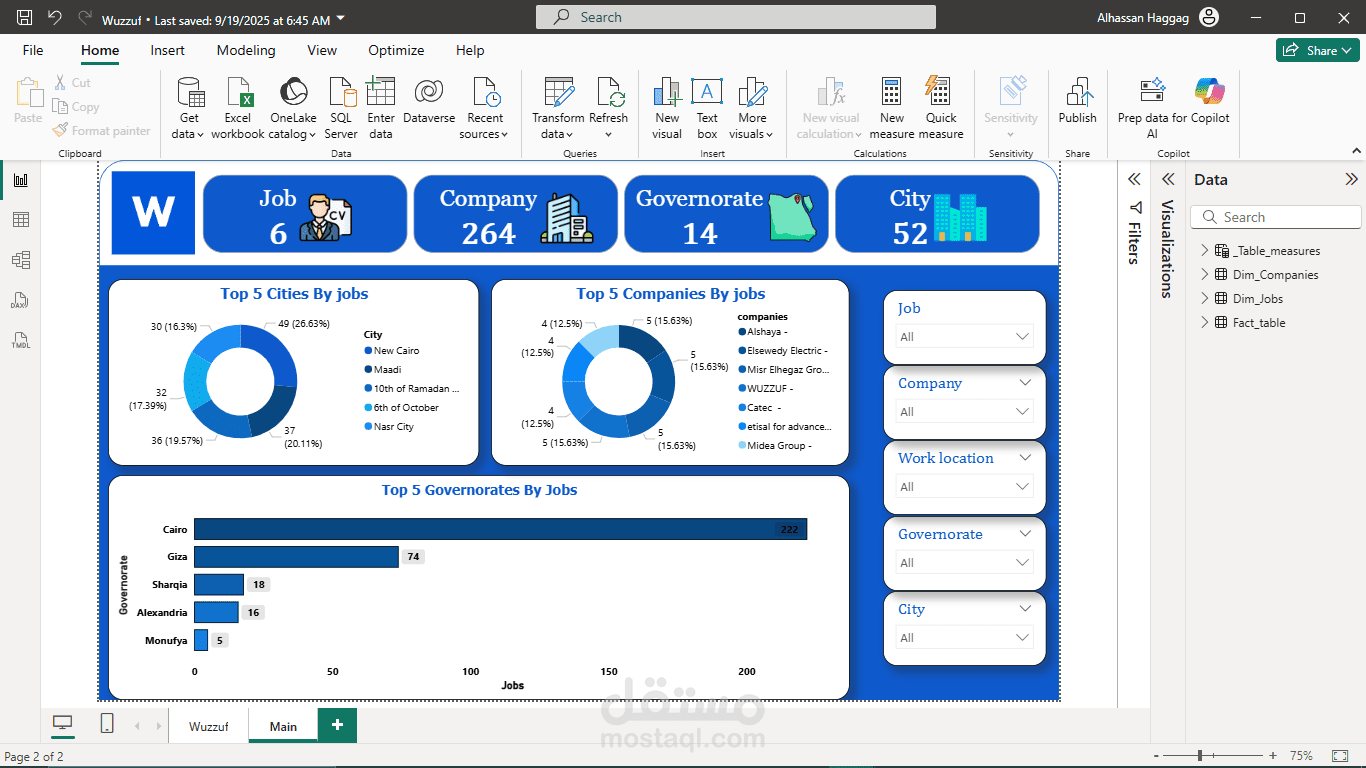
جمعت جميع البيانات مثل: job titles، job links، Companies، companies links، Employment Type، Work location، locations، وبعد الانتهاء قمت بعمل Export للنتائج كلها إلى ملف CSV.
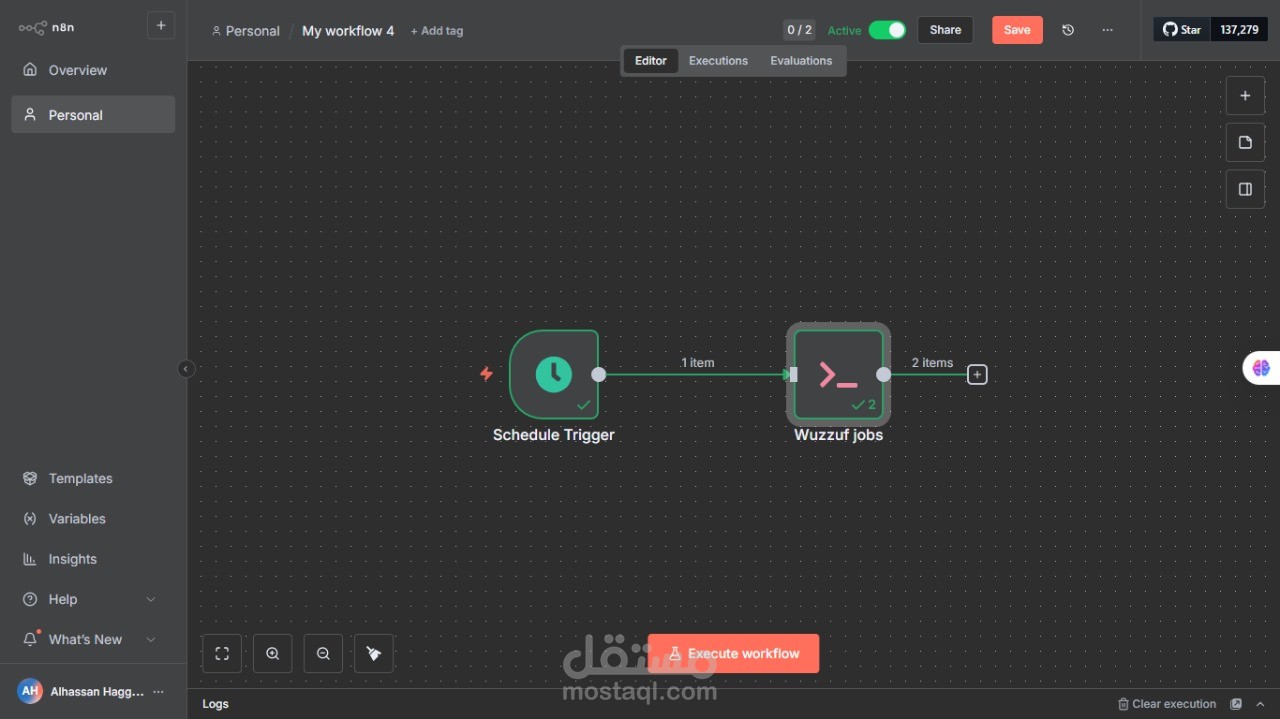
بعدها خطر ببالي سؤال: هل سأقوم بتشغيل الكود يدويًا كل مرة لجلب بيانات جديدة؟ بالطبع لا، الموضوع يحتاج إلى أتمتة (Automation).
لذلك، استخدمت n8n وأنشأت Workflow يقوم بـ:
تشغيل الكود يوميًا صباحًا عبر Schedule Trigger
تنفيذ الكود تلقائيًا باستخدام Execute Command
التحقق من الـ duplicates وعدم إضافة الوظائف نفسها مرة أخرى
حفظ البيانات الجديدة تلقائيًا في ملف CSV
النتيجة؟ نظام كامل يراقب الوظائف أولًا بأول بدون أي جهد مني، والملف دائمًا نظيف ومحدث.
والأمر الجميل أيضًا أنني أستطيع توسيع الفكرة لأي Use Case آخر، سواء جمع بيانات من مواقع أخرى أو ربطها مع Dashboards لعرض توجهات السوق.
هذه التجربة علمتني أن الأتمتة ليست رفاهية، بل ضرورة، فهي تجعل وقتك مخصصًا للتحليل والفهم بدلاً من الانشغال بالروتين.