تقسيم عملاء بطاقات الائتمان باستخدام التعلم الآلي
تفاصيل العمل
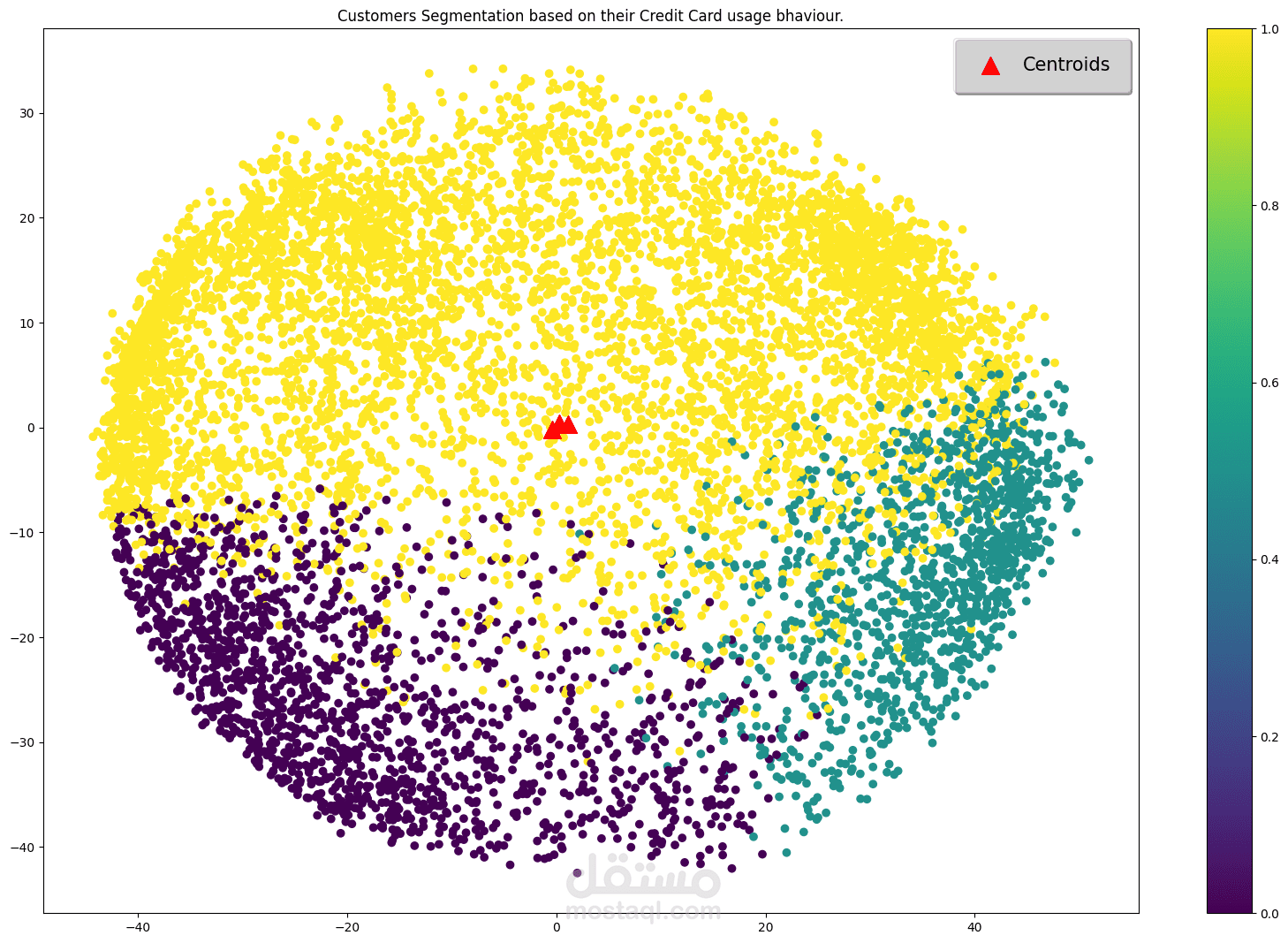
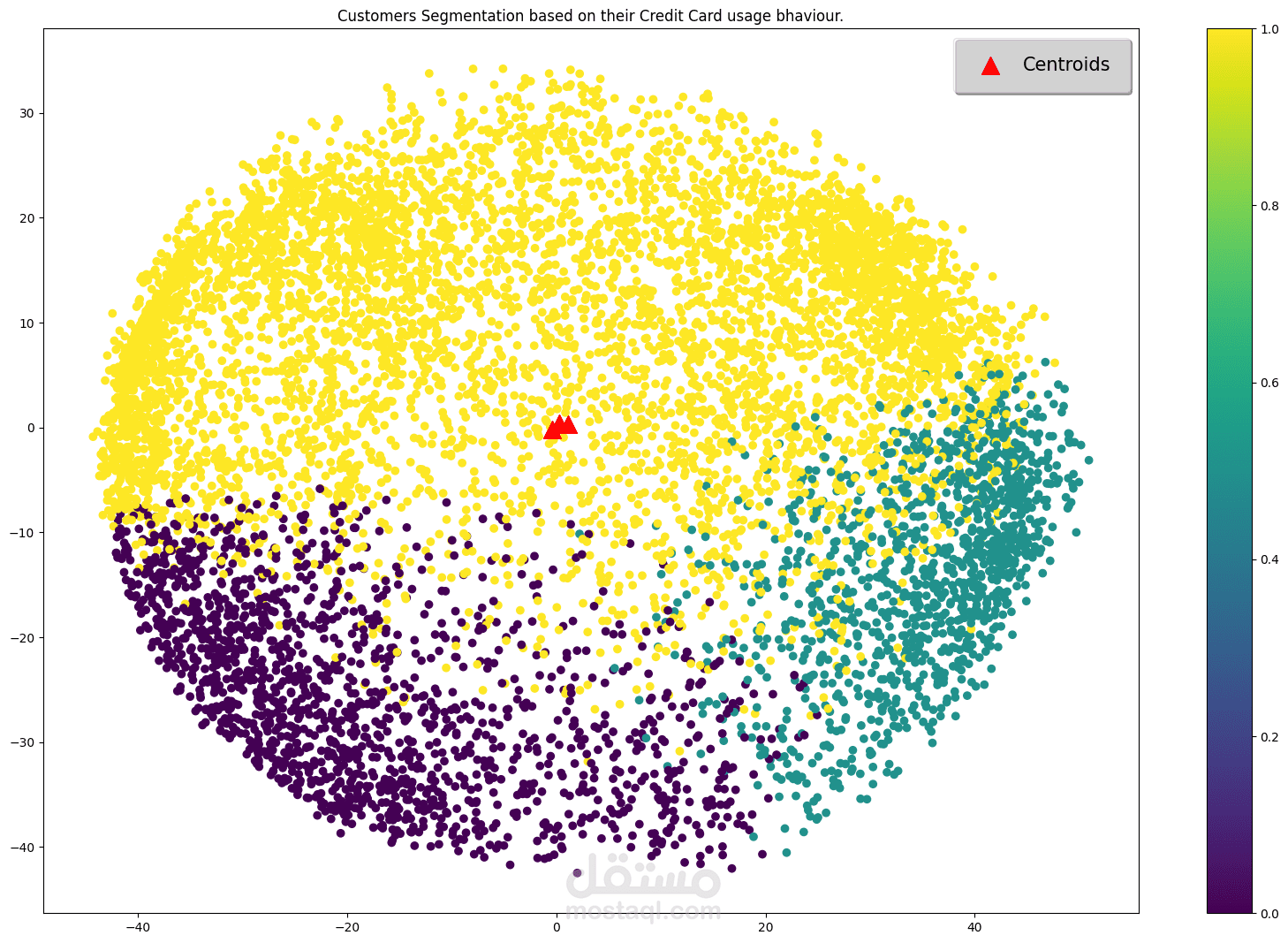

١. Unsupervised Learning (تصنيف K-Means)
- قُسِّم العملاء بناءً على أنماط استخدام بطاقات الائتمان.
- تم الحصول على درجة Silhouette قدرها ٠٫٢٥٠، مما يُشير إلى فصلٍ فعّالٍ بين المجموعات.
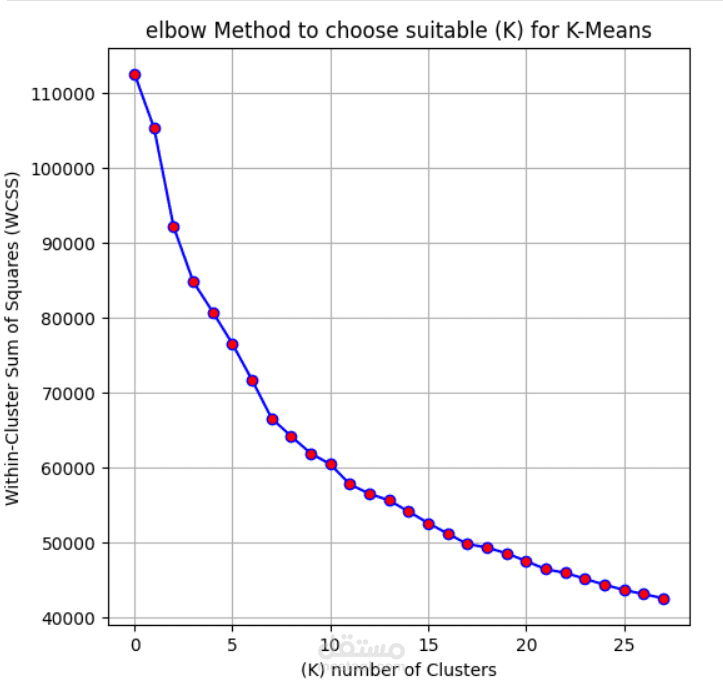
- تم استخدام طريقة Elbow لتحديد العدد الأمثل للمجموعات.
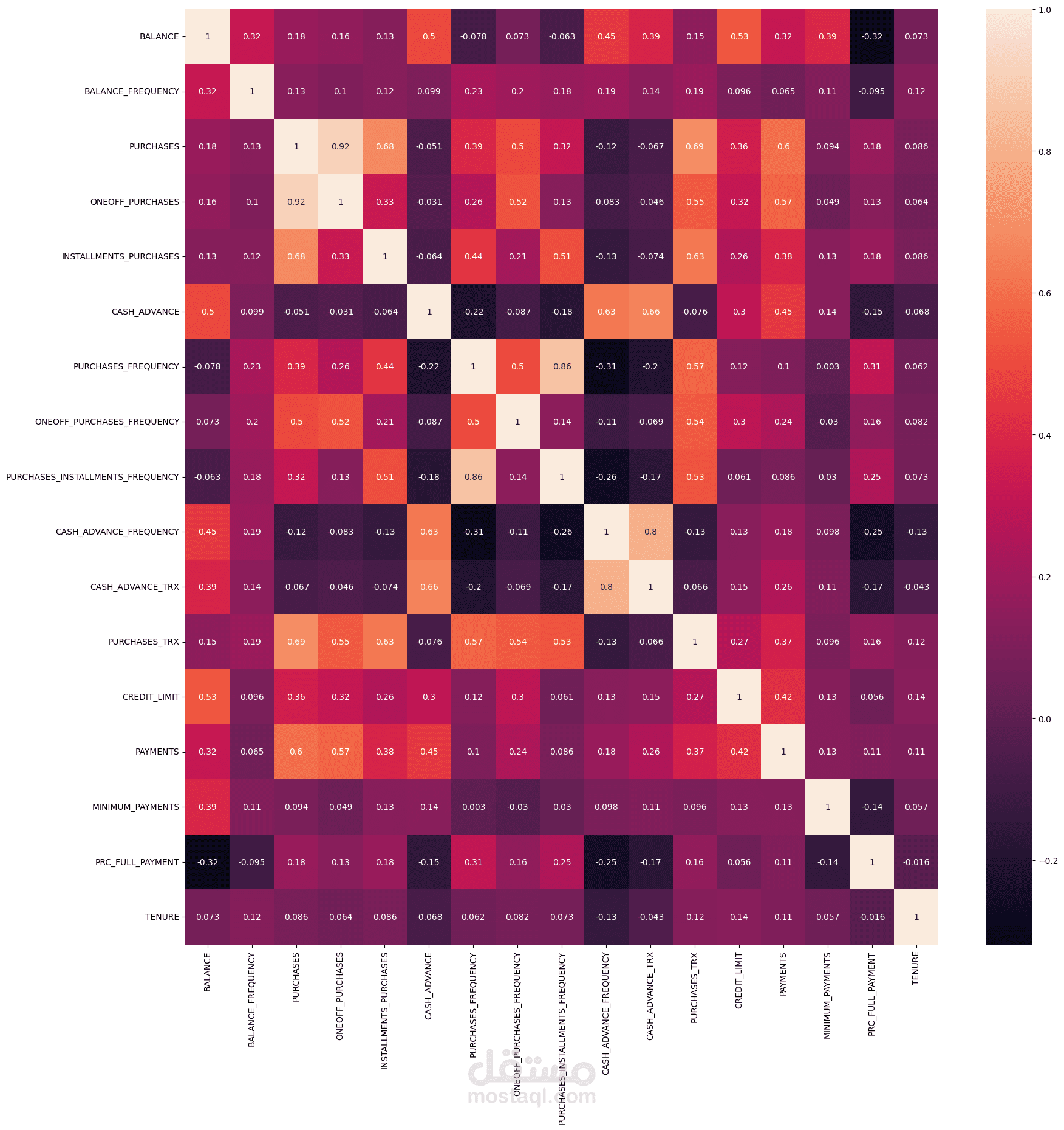
- تم تصوير توزيعات المجموعات للتفسير.
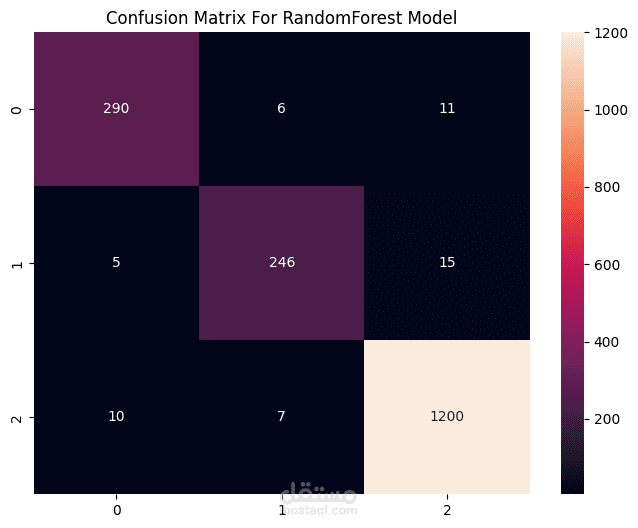
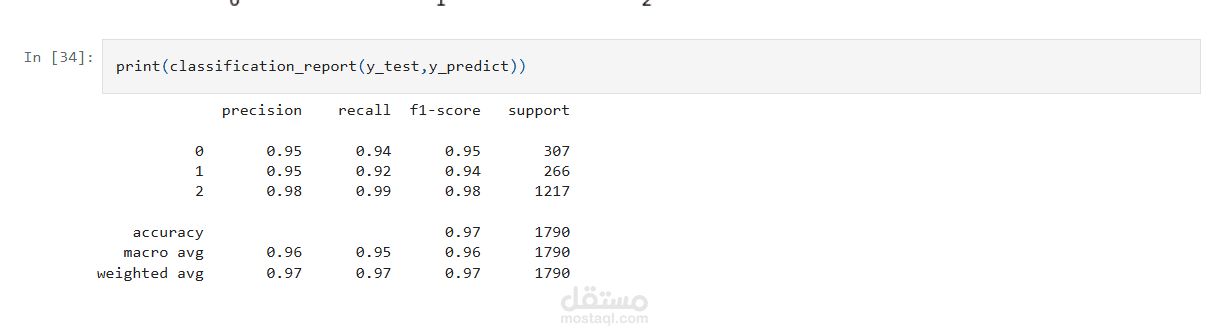
٢. Supervised Learning (Random Forest)
- تم التعامل مع تعيينات المجموعات كتسمياتٍ زائفة.
- تم بناء RandomForest Classifier للتنبؤ بعضوية مجموعة العملاء.
- تم تحقيق دقة ٩٦٫٩٨٪، حيث بلغت F1-Score جميعها ≈ 96.0%