بناء Data Pipeline متكاملة (Batch + Streaming) لتحليل بيانات حافلات نيويورك (MTA) باستخدام Airflow, Kafka, Spark و Power BI
تفاصيل العمل
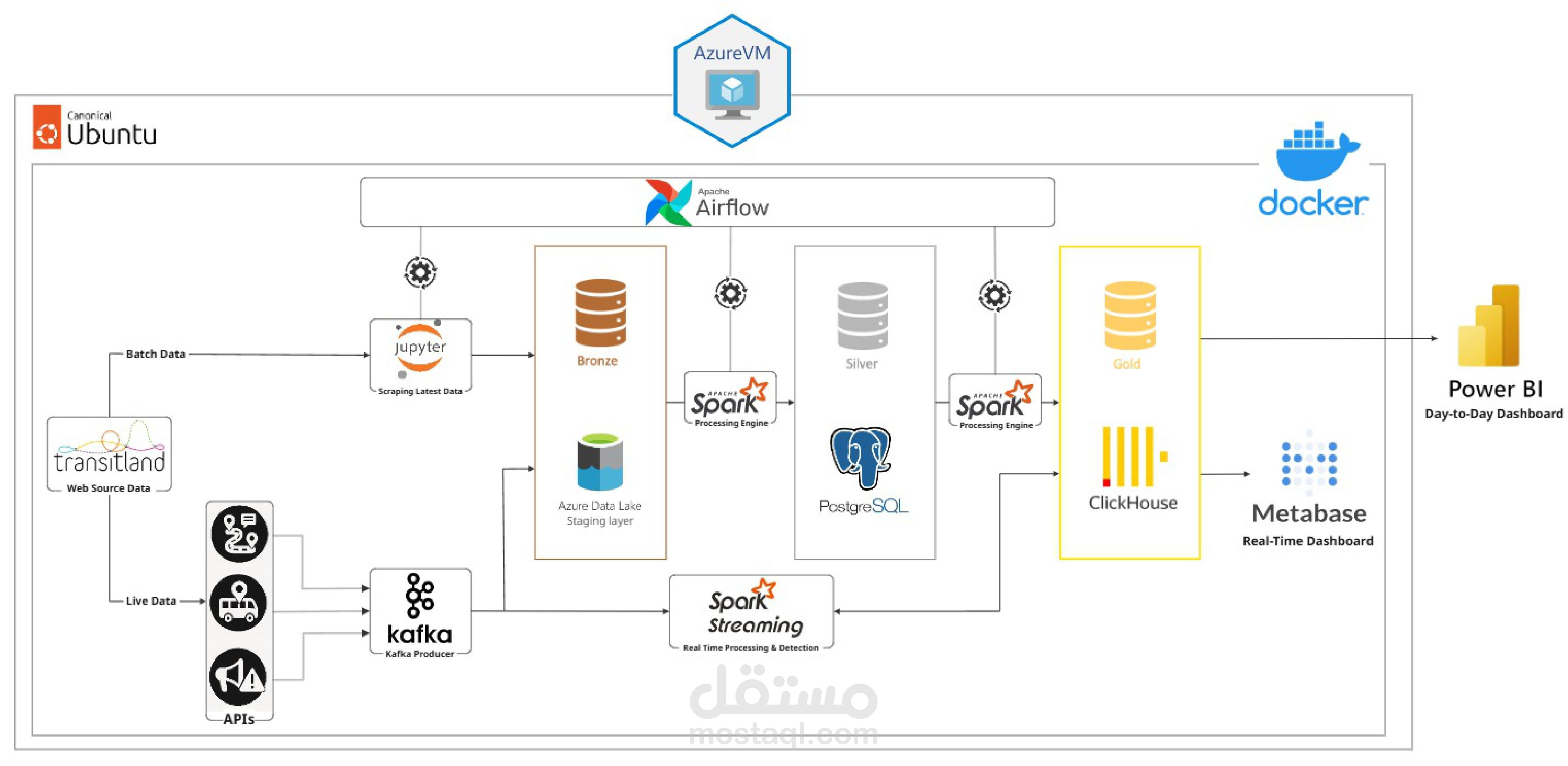
قمت بتطوير وتنفيذ بايبلاين متكامل يجمع بين Batch Processing و Real-Time Streaming لمعالجة وتحليل بيانات حافلات MTA في نيويورك.
المشروع تضمن:
استخدام Apache Airflow لأتمتة الـ Batch pipelines مع Web Scraping لجلب البيانات التاريخية من Transitland.
بناء Streaming Pipeline باستخدام Apache Kafka و Spark Structured Streaming لمعالجة بيانات GTFS Realtime (مواقع الحافلات، التحديثات، والتنبيهات).
تطبيق SCD Type 2 لحفظ تاريخ تغييرات البيانات وضمان التتبع الزمني.
تخزين البيانات النظيفة والـ Star Schema في PostgreSQL و ClickHouse.
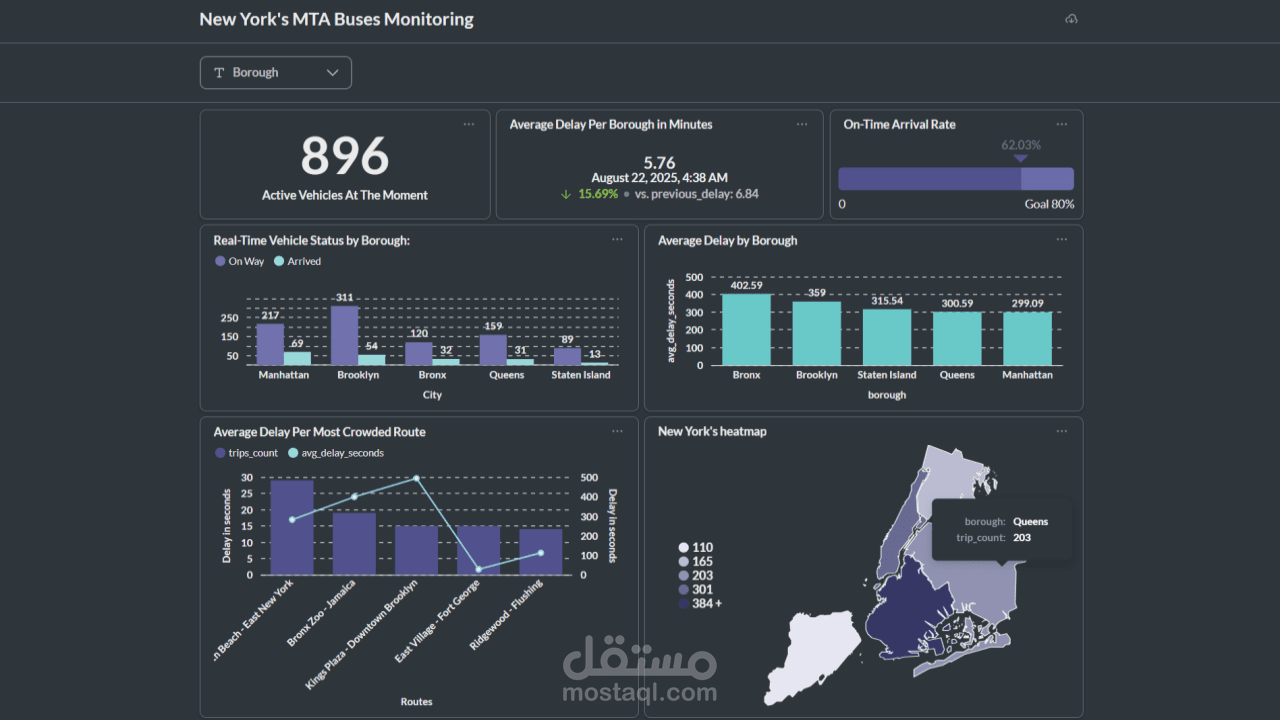
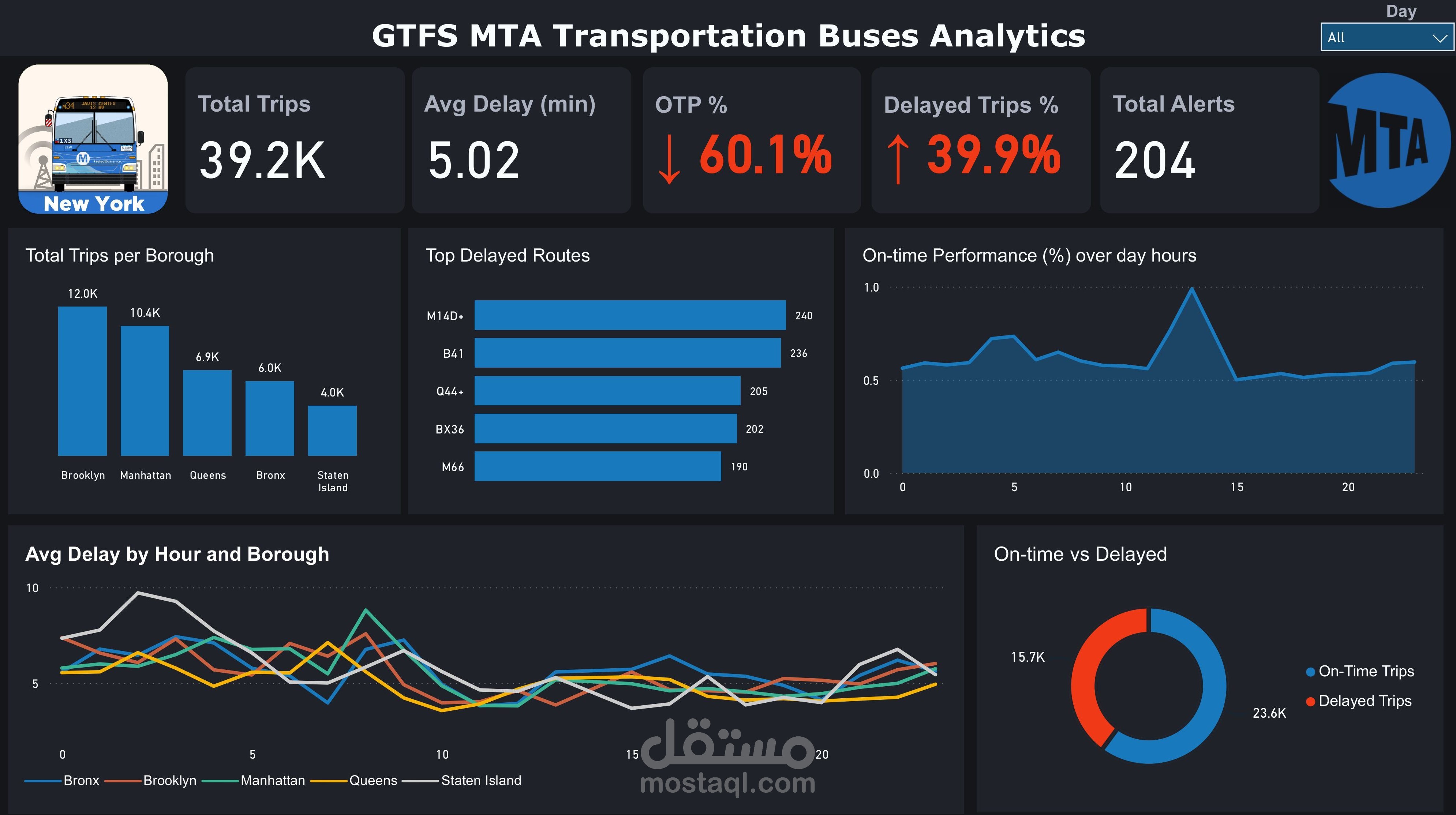
تصميم Dashboards تفاعلية باستخدام Power BI و Metabase لعرض:
تتبع مباشر للحافلات
أداء الرحلات ومتوسط التأخيرات
تحليلات جغرافية حسب المناطق
تنبيهات حية لحالات الطوارئ
النتيجة: نظام متكامل يعالج بيانات النقل في الزمن الحقيقي، يدعم اتخاذ القرار لمشغلي النقل والجهات الحكومية، ويحسن تجربة الركاب من خلال تقليل أوقات الانتظار وزيادة الكفاءة التشغيلية.