تصميم وتنفيذ Data Pipeline متكامل لمعالجة بيانات سيارات الأجرة في نيويورك باستخدام Spark و Power BI
تفاصيل العمل
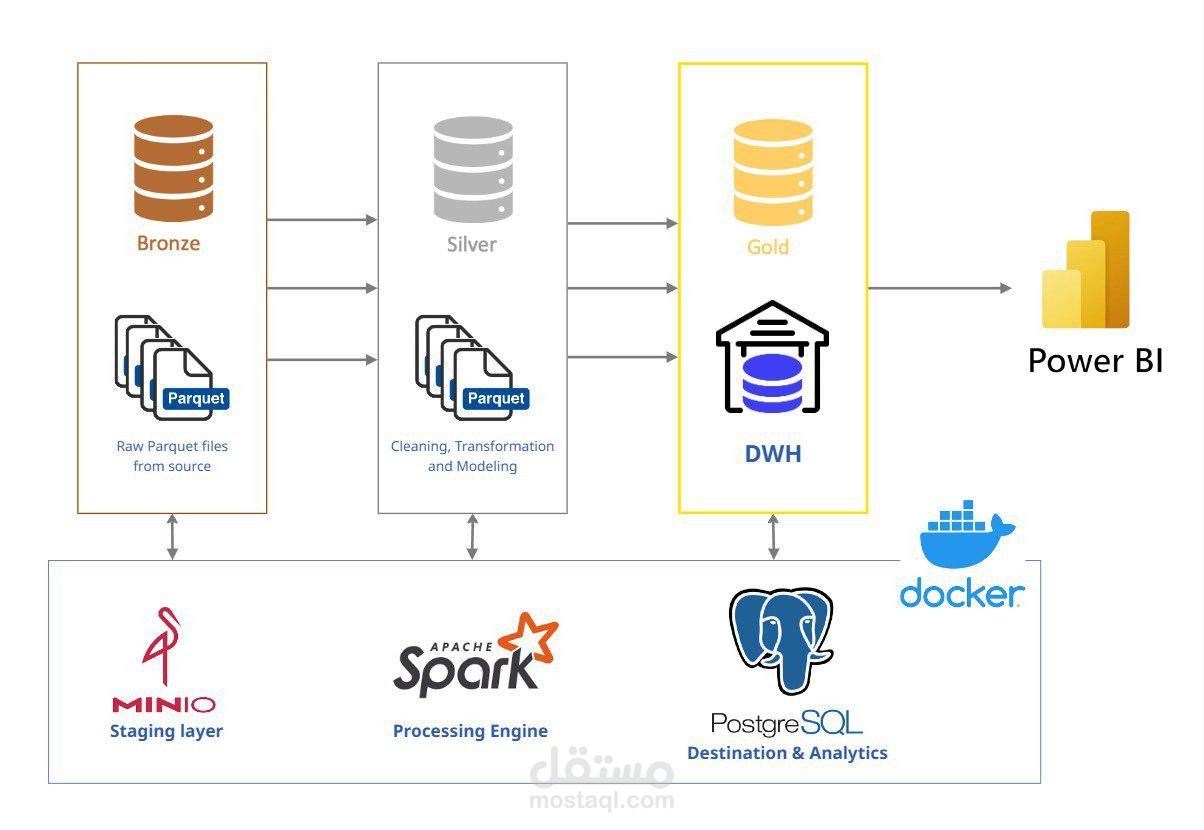
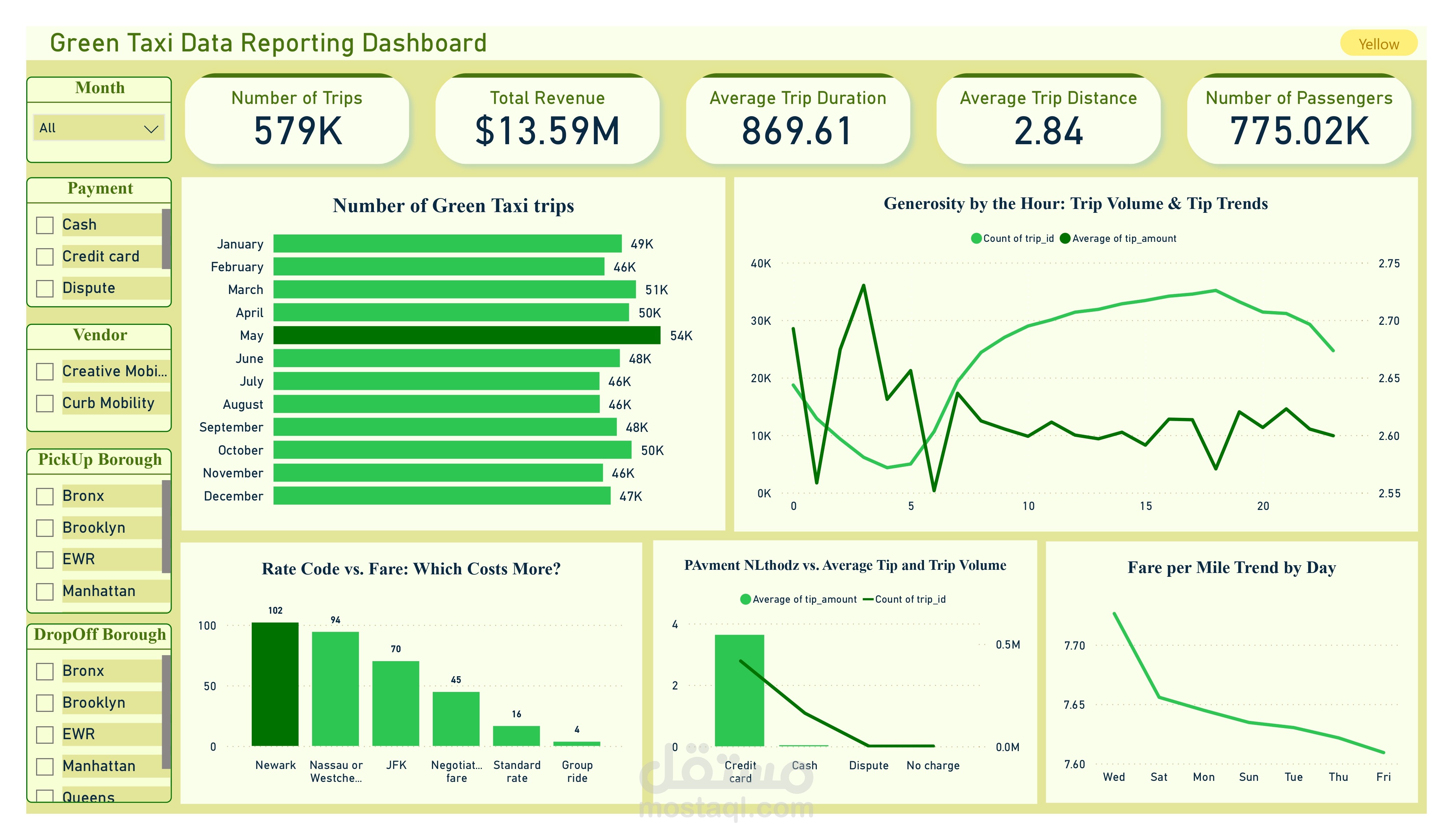
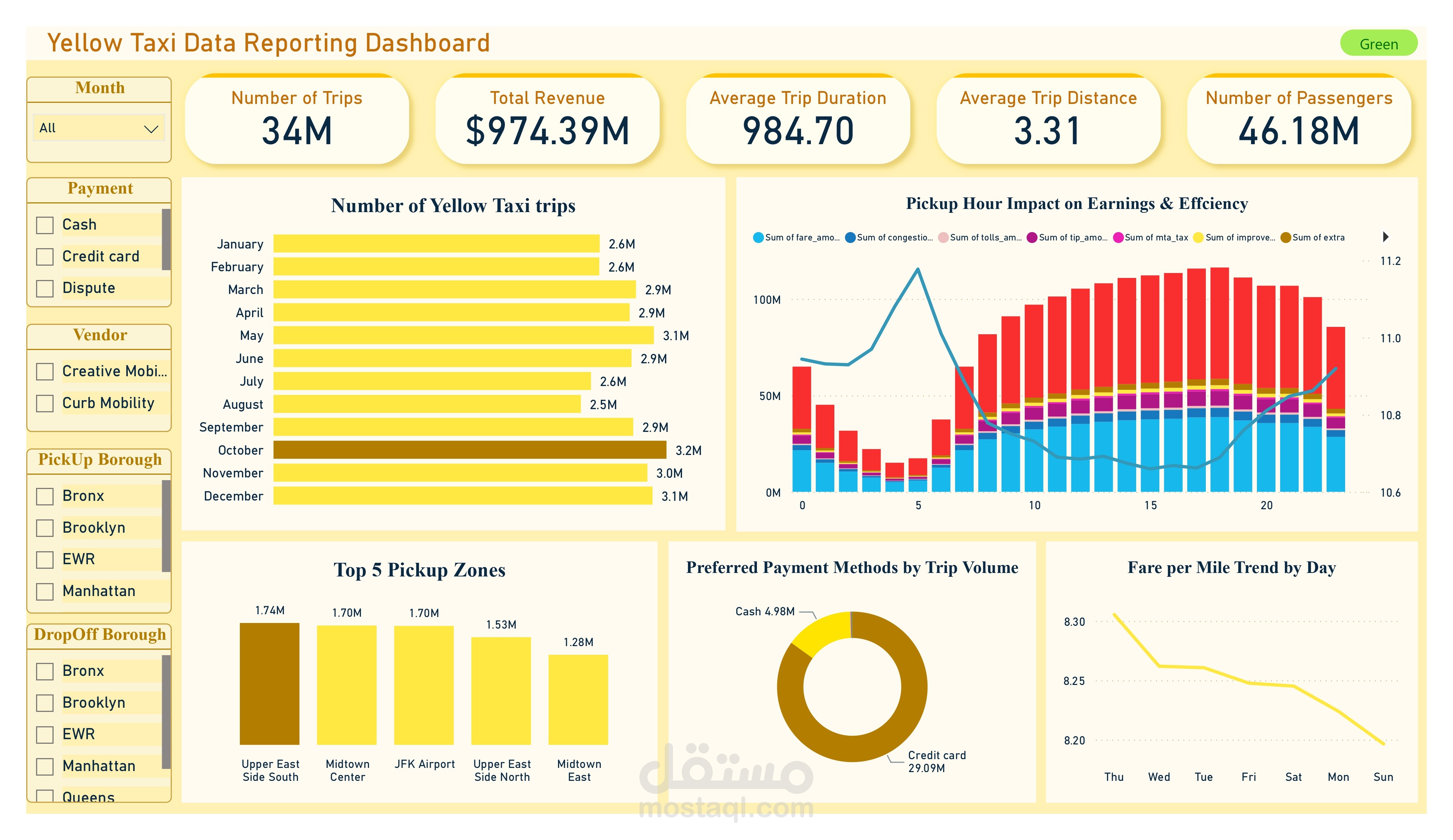

قمت بتطوير بايبلاين متكامل في مجال Data Engineering لمعالجة بيانات سيارات الأجرة (Yellow & Green Taxi – NYC, 2024).
المشروع تضمن:
بناء Data Lake باستخدام MinIO لاستيعاب أكثر من 48 مليون سجل خام.
تطوير عملية ETL باستخدام Apache Spark (PySpark) لتنظيف البيانات، إزالة التكرارات، ومعالجة القيم غير الصالحة.
إنشاء Star Schema داخل Spark وتخزين النتيجة في PostgreSQL (~41 مليون سجل نظيف).
ربط قاعدة البيانات مباشرة مع Power BI لتصميم Dashboards تفاعلية تعرض أنماط الركوب، الإيرادات، وأشهر مناطق التنقل.
النتيجة: نظام تحليلي متكامل جاهز للاستخدام يقدم رؤى عملية من ملايين السجلات في الزمن القريب من الحقيقي، قابل للتوسع والتطوير حسب احتياجات الأعمال.