Investigated lifestyle and demographic drivers of obesity using machine learning, visualization, and statistical analysis to identify major risk factors and predictive insights
تفاصيل العمل
Description
This project investigates the risk factors associated with obesity by examining a dataset of individual characteristics (lifestyle, demographics, dietary habits, etc.). The aim is to uncover which features most strongly contribute to obesity risk, and to build predictive models that could help identify high-risk individuals for early intervention.
Key Components
ComponentWhat I Did
Data Cleaning & Preprocessing• Handled missing or inconsistent entries and cleaned up variables for analysis.
• Standardized or normalized numeric features and encoded categorical variables.
• Removed duplicates, checked for and handled outliers.
Exploratory Data Analysis (EDA)• Computed summary statistics (means, medians, variance) to understand feature distributions.
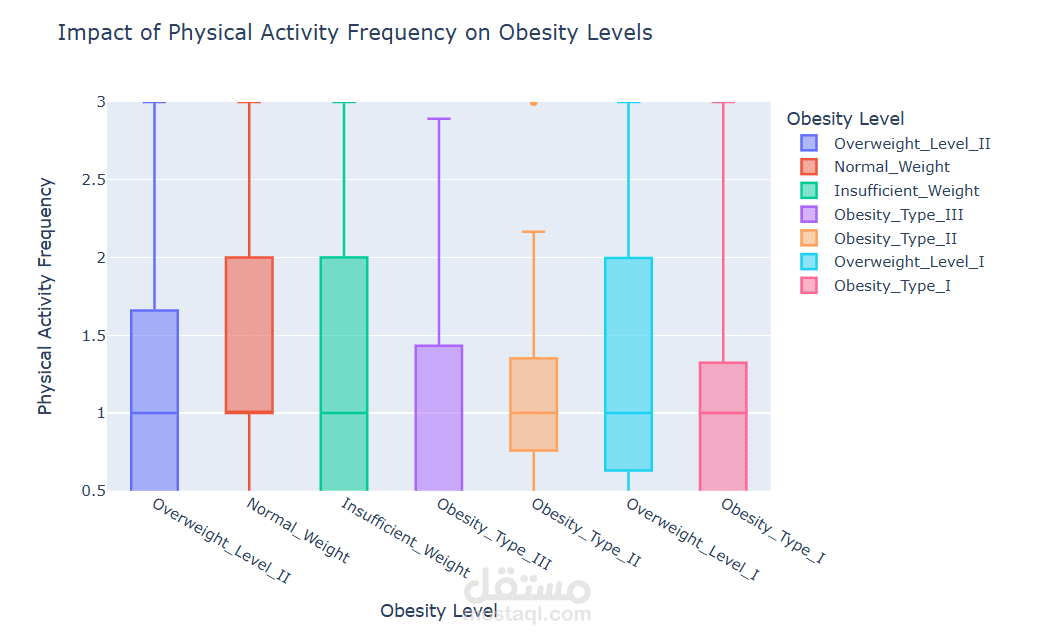
• Visualized relationships among features (scatterplots, histograms, box plots, correlation matrices).
• Investigated how different demographic or lifestyle variables correlate with obesity levels.
Feature Engineering & Selection• Created new derived features (e.g. combining lifestyle/diet indicators, age brackets, etc.).
• Used feature importance metrics and correlation thresholds to select most relevant features.
Modeling & Evaluation• Built machine learning classification models (e.g. logistic regression, decision trees, ensemble methods) to predict obesity risk categories.
• Used cross-validation to assess model stability.
• Evaluated models using metrics such as accuracy, precision, recall, ROC-AUC, confusion matrix.
Visualization & Insights• Used seaborn / matplotlib (or Plotly if applicable) to produce interpretable visualizations of key relationships (e.g., diet vs. obesity, activity levels vs. obesity).
• Plotted model performance metrics and feature importance to show what drives predictions.
Reporting & Findings• Documented all steps clearly: data sources, assumptions, methods, and findings.
• Highlighted which risk factors are strongest (e.g. certain diet habits, physical activity, demographic factors).
• Discussed limitations (e.g. potential bias in data, missing variables, sample representativeness) and suggestions for deeper study.
Skills Demonstrated
Strong use of Python (Pandas, NumPy) for data manipulation
Data visualization skills using tools (Seaborn, Matplotlib, etc.)
Machine learning knowledge: classification models, feature selection, model evaluation with ROC-AUC, confusion matrix, etc.
Ability to preprocess real-world data (cleaning, handling missing values, encoding categorical features)
Good communication of findings: narrative + charts so others can understand which obesity risk factors matter most