Explored key factors contributing to hair loss through data cleaning, EDA, and predictive modeling, uncovering patterns and building models for early risk assessment
تفاصيل العمل
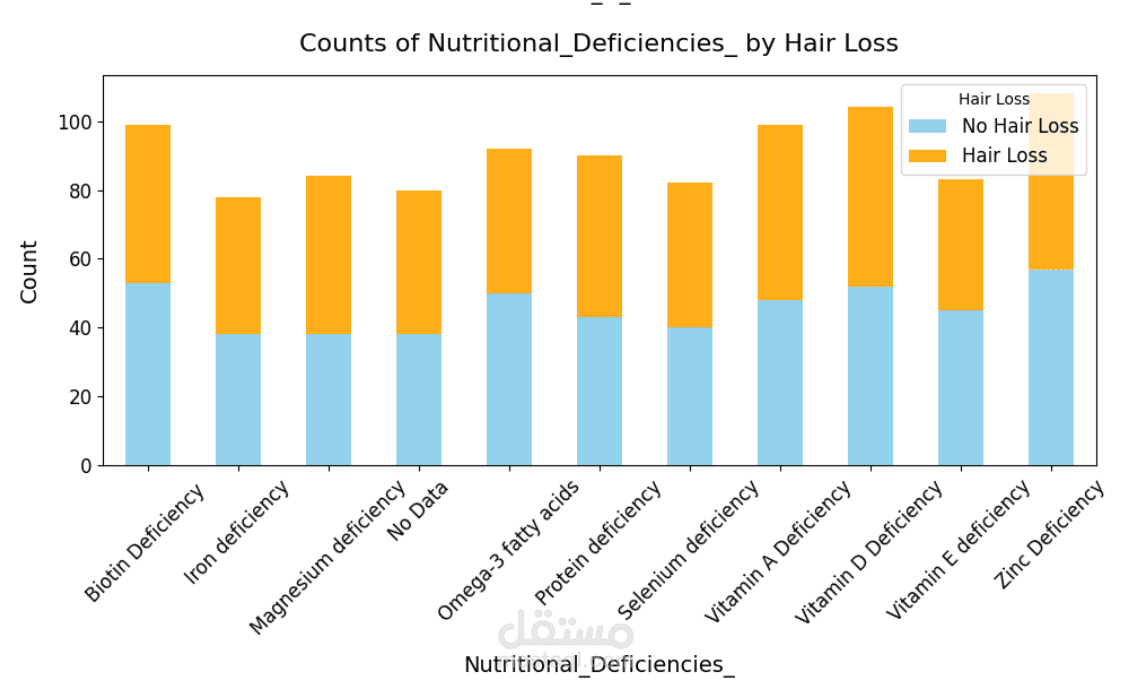
This project explores factors contributing to hair loss by analyzing relevant data, cleaning it, and applying statistical and machine learning techniques to derive insights. The goal is to understand which features are most predictive of hair loss and to build a model that could help in early detection or risk assessment.
Key Elements
ComponentWhat I Did
Data Cleaning & Preprocessing• Handled missing values, duplicate entries, and inconsistent formatting.
• Transformed categorical variables with encoding techniques.
• Scaled and normalized numerical features where required.
Exploratory Data Analysis (EDA)• Generated descriptive statistics (means, medians, standard deviations).
• Visualized distributions of variables, correlations, and trends using plots (histograms, box plots, correlation heatmap, etc.).
• Identified outliers and patterns.
Feature Engineering & Selection• Derived features to capture important signals (e.g., transformation, interaction of features).
• Tested different feature selection methods (correlation threshold, feature importance from tree-based models, etc.) to reduce dimensionality.
Modeling & Evaluation• Built machine learning models (e.g., decision trees, random forests, possibly gradient boosting methods) to predict hair loss risk.
• Evaluated models using metrics such as accuracy, precision, recall, ROC-AUC, confusion matrix.
• Performed cross-validation to ensure model robustness.
Visualization & Insights• Created visualizations (seaborn / matplotlib / Plotly) to illustrate insights: which features have the strongest association, how predictions distribute, performance of models.
• Included plots that are interpretable and help non-technical stakeholders understand findings.
Documentation & Reporting• Narrated each step with markdown: the motivation, the methods, the findings.
• Discussed limitations of the dataset and modeling approach, and suggestions for next steps (e.g. gathering more data, adding new features, trying more advanced models).
Skills Demonstrated
Proficient use of Python with libraries such as Pandas, NumPy for data handling
Effective use of visualization tools: matplotlib, seaborn, possibly Plotly
Machine learning model building including feature engineering, model selection, and evaluation
Understanding of evaluation metrics like ROC-AUC, confusion matrix, cross-validation
Clear communication of findings and insights through storytelling and visual aids