IMDB Movies Data Analysis
تفاصيل العمل
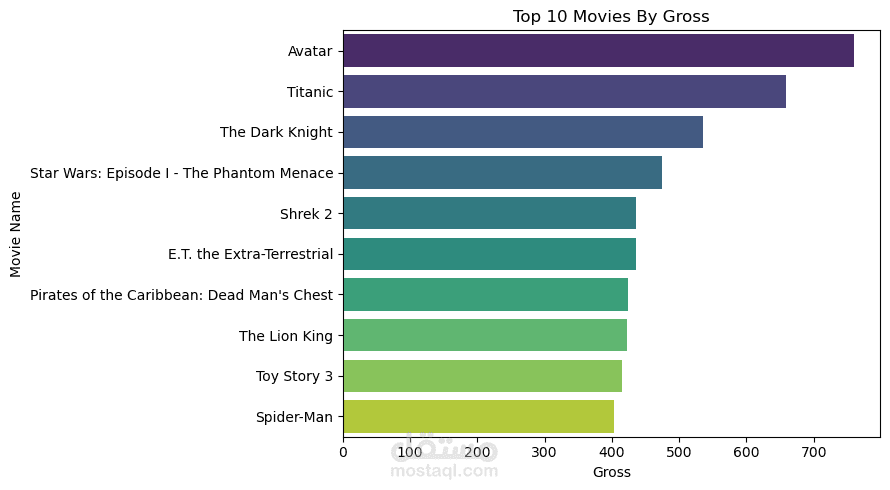
في هذا المشروع، قمنا بتطبيق خطوات معالجة البيانات المسبقة، والتصور البياني، وتقنيات التجميع باستخدام طريقتي K-Medoids و Hierarchical Clustering على بيانات أفلام IMDB.
استخرجنا معلومات مهمة عن الأفلام مثل: الفيلم الذي حقق أعلى إيرادات في شباك التذاكر، والفيلم الأعلى تقييمًا، وقمنا بتجميع الأفلام في مجموعات بناءً على عدة خصائص متعددة.