Sentiment Analysis Using Logistic Regression
تفاصيل العمل
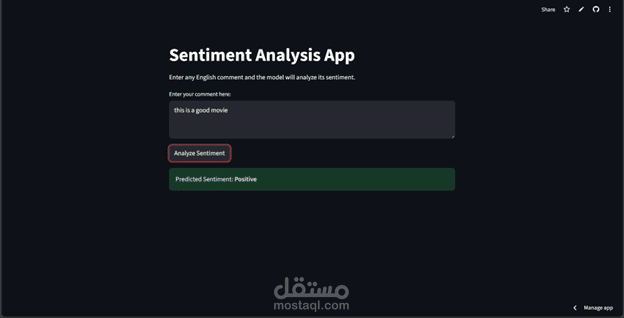
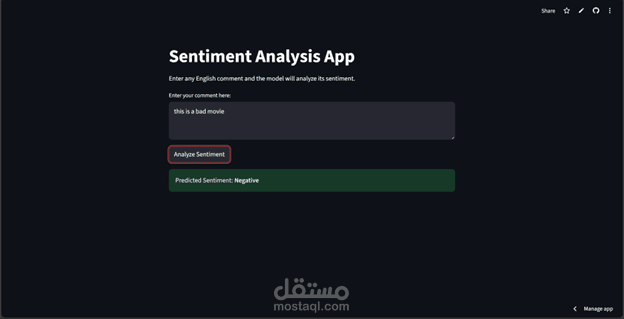
تصنيف النصوص باستخدام تقنيات الذكاء الاصطناعي
في هذا المشروع قمت ببناء نموذج ذكي قادر على تحليل النصوص وتصنيفها إلى (إيجابي – سلبي – محايد) اعتمادًا على خصائص TF-IDF وخوارزمية Logistic Regression.
المهام والمهارات الأساسية:
تجميع البيانات من مصادر مختلفة وتجهيزها للدراسة.
تنظيف البيانات (Data Cleaning) وإزالة الضوضاء والمعلومات غير المفيدة.
التحليل الاستكشافي للبيانات (EDA) لفهم الأنماط والعلاقات داخل البيانات.
معالجة البيانات النصية (Text Preprocessing) مثل Tokenization وStopwords Removal.
استخدام Python ومكتبة Scikit-Learn لبناء وتدريب النموذج.
تطبيق Logistic Regression باستخدام خصائص TF-IDF لاستخراج الميزات.
هذا المشروع يعكس قدرتي على التعامل مع البيانات من البداية للنهاية: تجميع → تنظيف → تحليل → بناء نموذج → نتائج قابلة للاستخدام، مما يجعله مناسبًا لتطبيقات مثل:
تحليل آراء العملاء (Customer Reviews)
مراقبة محتوى وسائل التواصل الاجتماعي
أنظمة دعم القرار للشركات