ml,dl,nlp project from scratch
تفاصيل العمل



Technical Report: An Analysis of a Student Performance Prediction System
1. Introduction
This report provides a technical deep-dive into the Flask.py script, a Python application designed for student performance analysis and prediction. The script integrates data loading, preprocessing, model training, and a web API for real-time predictions. The primary goal of this analysis is to deconstruct the code's logic, highlight its key architectural components, and evaluate the technical decisions made.
2. Code Architecture and Logic Flow
The Flask.py script follows a sequential, top-down architecture, with the core logic executed within the home() route upon application startup. The overall flow can be summarized in the following phases:
1.Initialization: Global variables for models (regression_models, classification_models) and the data scaler are initialized.
2.Data Processing: The script loads the student performance datasets, combines them, and performs a series of preprocessing steps.
3.Model Training: A wide range of machine learning models for both regression and classification are trained on the processed data.
4.Prediction API: A dedicated route (/predict) is set up to handle incoming prediction requests, preprocess new data, and return predictions from the best-performing models.
5.Web Interface: The main route (/) renders an HTML template that visualizes the results of the model training and provides a user interface for the prediction API.
3. Detailed Component Analysis
3.1 Data Loading and Preprocessing
The data pipeline begins with a robust loading mechanism.
•The script loads student-mat.csv and student-por.csv using pd.read_csv with the correct separator.
•It then uses pd.merge() to combine the datasets based on a specific set of student-related features, ensuring a consistent final dataset.
•A crucial preprocessing step involves handling categorical variables. The code correctly identifies non-numeric columns and applies One-Hot Encoding using pd.get_dummies(). This is a best practice for preparing categorical data for machine learning algorithms.
•The target variable G3 is then used to create a new classification target, risk_category, which groups students into "High Risk", "Medium Risk", and "Low Risk." This demonstrates an understanding of how to transform a regression problem into a classification problem for a different type of analysis.
3.2 Model Training
The script trains a comprehensive suite of models, showcasing a solid grasp of model selection and evaluation.
•Data Splitting: The data is correctly split into training and testing sets using train_test_split with a 80/20 ratio. This is fundamental for evaluating model performance on unseen data.
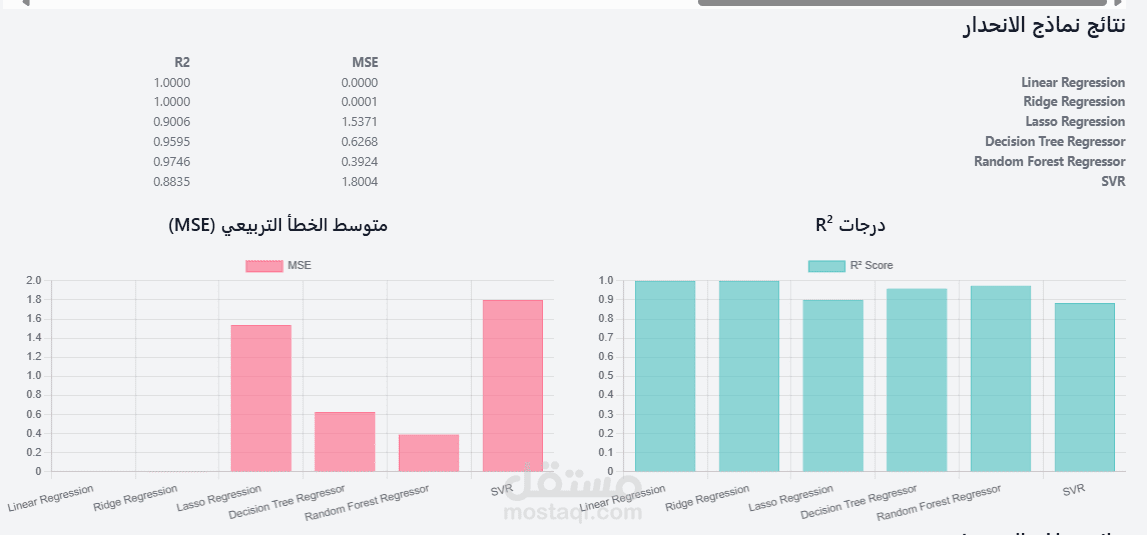
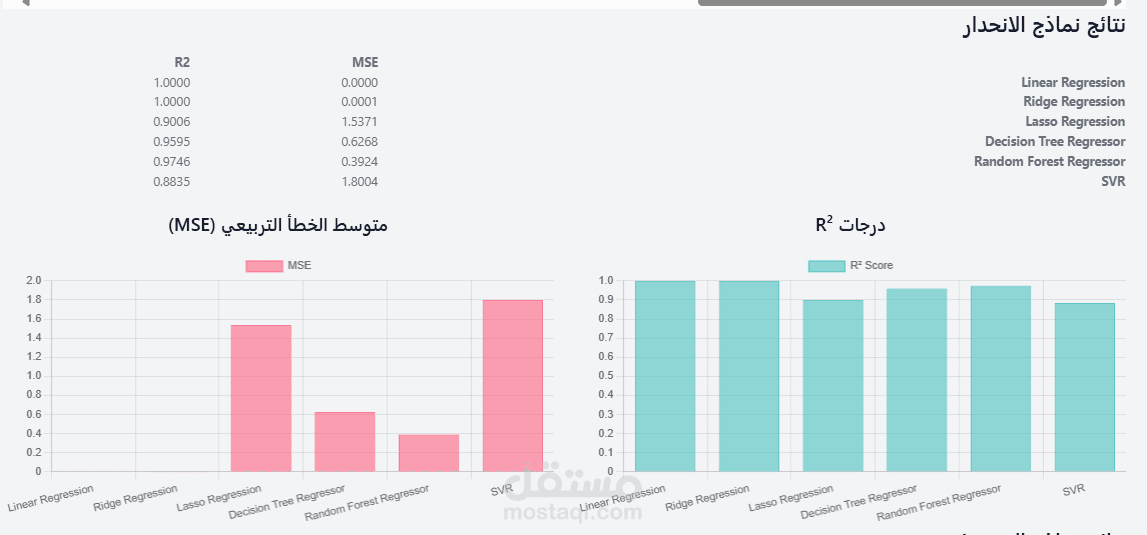
•Regression Models: The script trains multiple regression models, including Linear Regression, Ridge, Lasso, Decision Tree, Random Forest, SVM, and a custom deep learning model. The use of a dictionary (regression_models) to store and manage these models is an efficient and clean programming pattern.
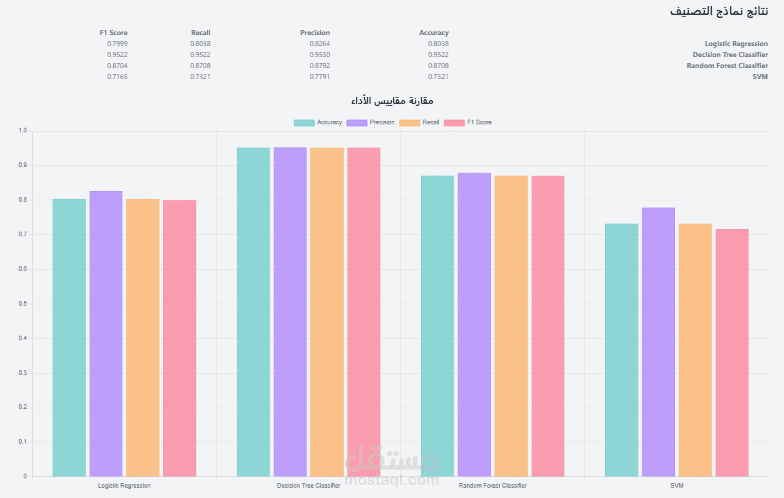
•Classification Models: Similarly, a variety of classification models are trained. The code also correctly handles the MinMaxScaler for the deep learning models, which is a necessary step to ensure convergence.
•Deep Learning Architecture: The TensorFlow/Keras model is defined as a Sequential model with Dense and Dropout layers. This is a standard and effective architecture for structured data, with Dropout helping to prevent overfitting.
•Evaluation Metrics: The code uses appropriate metrics for each task:
oRegression: mean_squared_error and r2_score are used to measure the accuracy and fit of the regression models.
oClassification: accuracy_score, precision_score, recall_score, and f1_score are used to provide a detailed view of the classifier's performance.
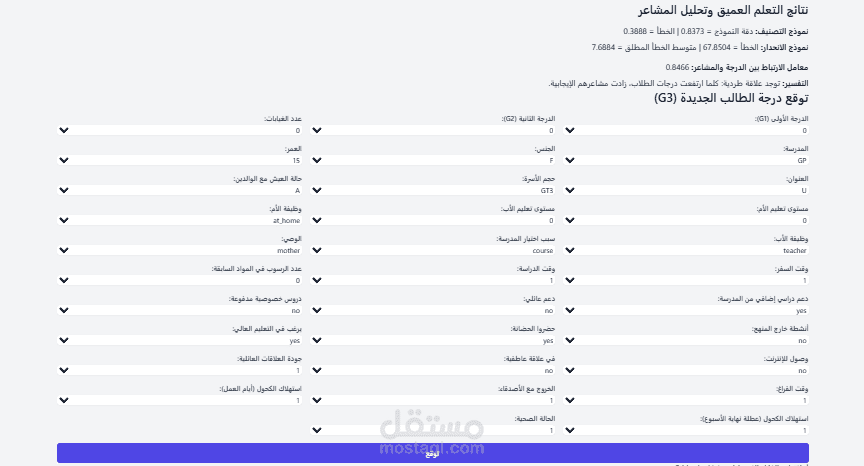
3.3 The Prediction API (/predict)
The Flask.py script includes a REST API endpoint that is particularly well-engineered.
•Data Handling: The endpoint receives JSON data, converts it to a Pandas DataFrame, and applies the same preprocessing steps as the training pipeline.
•Column Alignment: A critical piece of logic is the use of input_encoded.reindex(...). This ensures that the input data for prediction has the same columns and order as the original training data, preventing common errors when one-hot encoding is used.
•Model Loading: Instead of retraining models on every request (which would be highly inefficient), the script uses globally stored, pre-trained models. This is a fundamental principle for deploying machine learning models in a production environment.
•Prediction Logic: The script correctly uses the predict() method of the best-performing models (e.g., Random Forest) to generate both a regression and a classification prediction for the new data.
•JSON Response: The predictions are returned as a JSON object, a standard practice for API communication.
4. Conclusion and Technical Evaluation
The Flask.py script demonstrates a comprehensive and technically sound approach to a data science problem. The code is well-structured and follows logical steps from data ingestion to model deployment. Key strengths include:
•The use of robust libraries like Pandas and Scikit-learn.
•The implementation of standard machine learning practices (data splitting, preprocessing, and appropriate evaluation metrics).
•The development of a functional web API that is efficient and scalable by using globally initialized models.
•The code's ability to handle both regression and classification tasks within a single pipeline, showing versatility.
Overall, the script serves as an excellent example of a complete, end-to-end machine learning project.