تصنيف الفطر
تفاصيل العمل
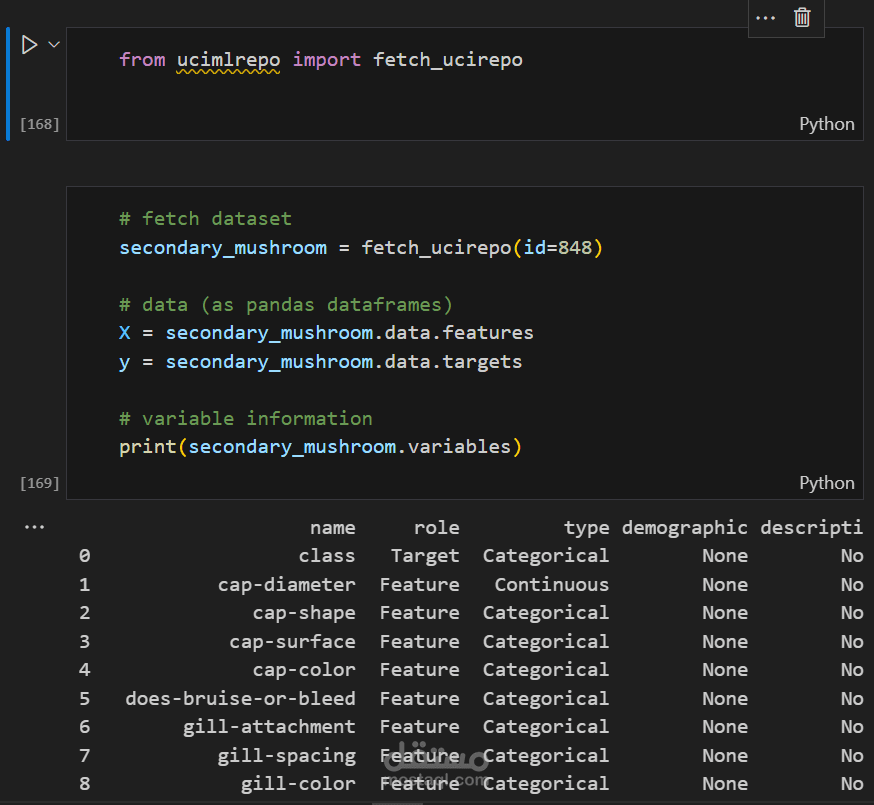
جلب البيانات: تم استخدام مكتبة ucimlrepo للحصول على بيانات الفطر (mushroom dataset).
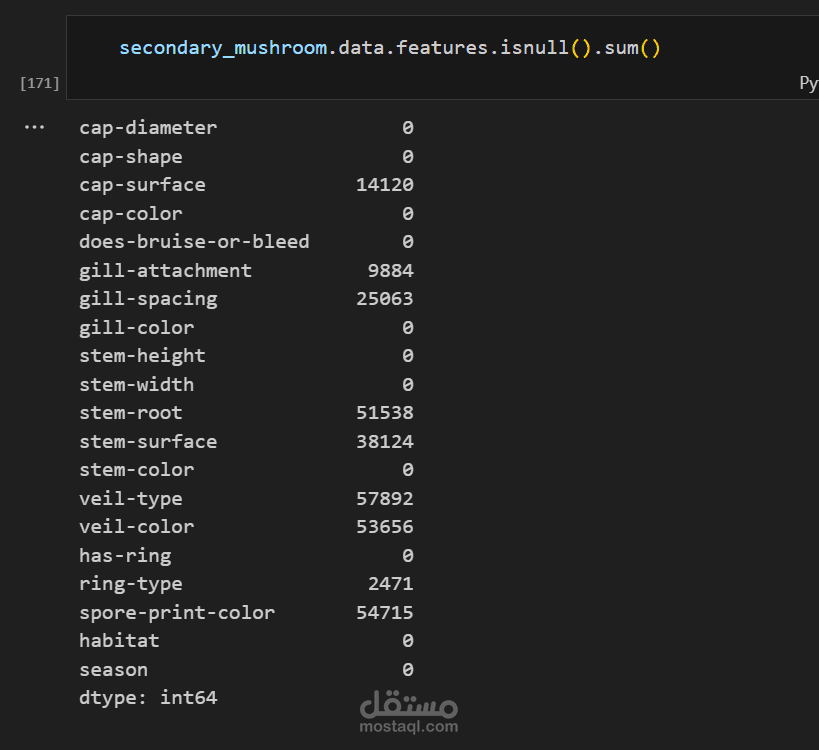
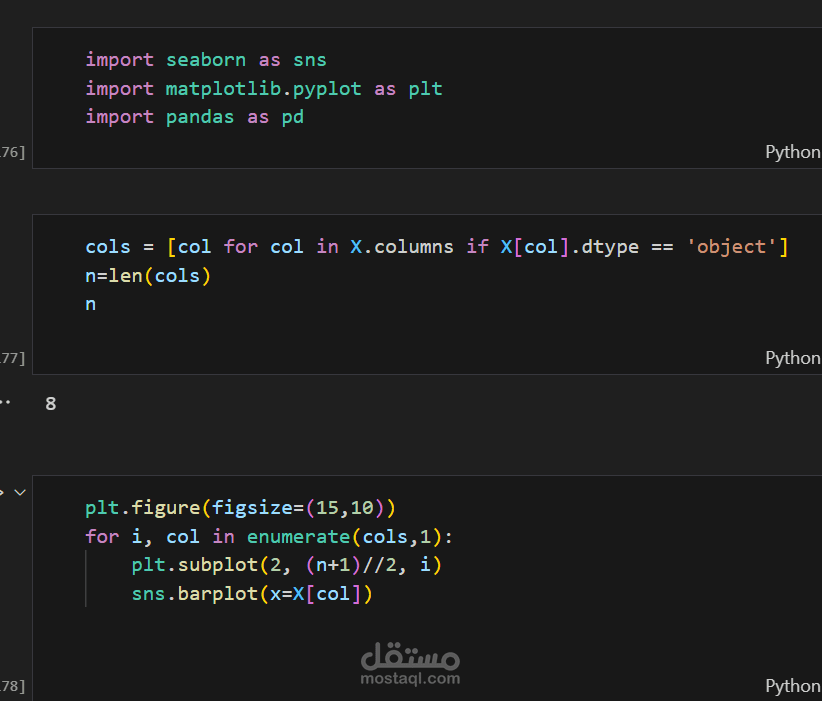
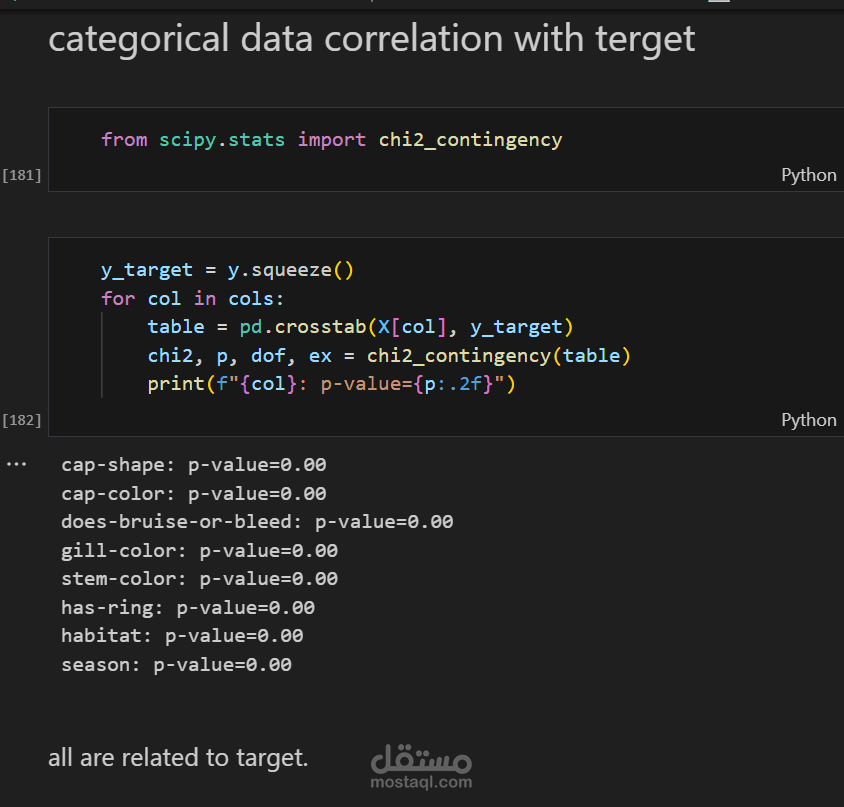
استكشاف البيانات (EDA): فحص القيم المفقودة، حذف الأعمدة غير المفيدة، إزالة التكرارات، وتحضير البيانات للتحليل.
مرحلة النمذجة: تم بناء عدة نماذج تصنيف ومقارنتها، منها:
الانحدار اللوجستي (Logistic Regression)
شجرة القرار (Decision Tree)
الغابة العشوائية (Random Forest)
نايف بايز (Naive Bayes)
تقييم الأداء: باستخدام تقارير التصنيف (Classification Report) ومصفوفات الالتباس (Confusion Matrix) لكل نموذج على بيانات التدريب والاختبار.