تحليل احتمالية الصلع باستخدام التعلم الآلي
تفاصيل العمل
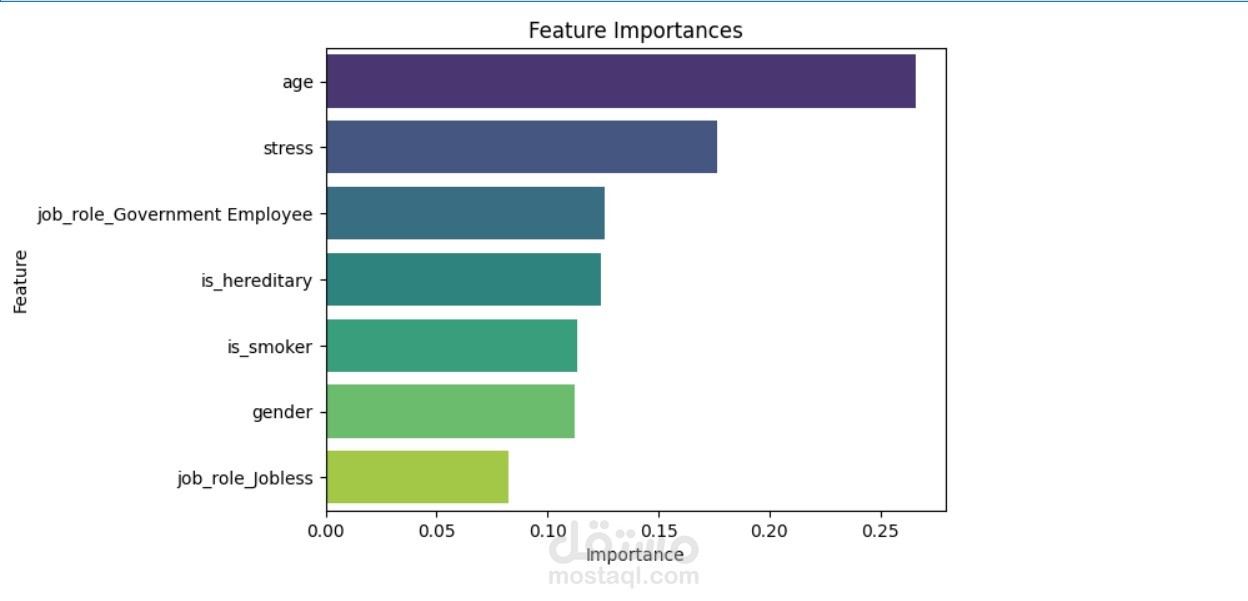

هذا المشروع يهدف إلى تحليل بيانات احتمالية الصلع من ملف CSV باستخدام تقنيات تعلم الآلة. تم تطبيق عدة خوارزميات (KNN, SVM, Decision Tree, Naive Bayes) لتقييم الأداء واختيار النموذج الأكثر دقة وفعالية.
الأدوات والتقنيات المستخدمة:
Python · Pandas · Matplotlib · Scikit-learn · TensorFlow/Keras (اختياري)
النتائج الرئيسية:
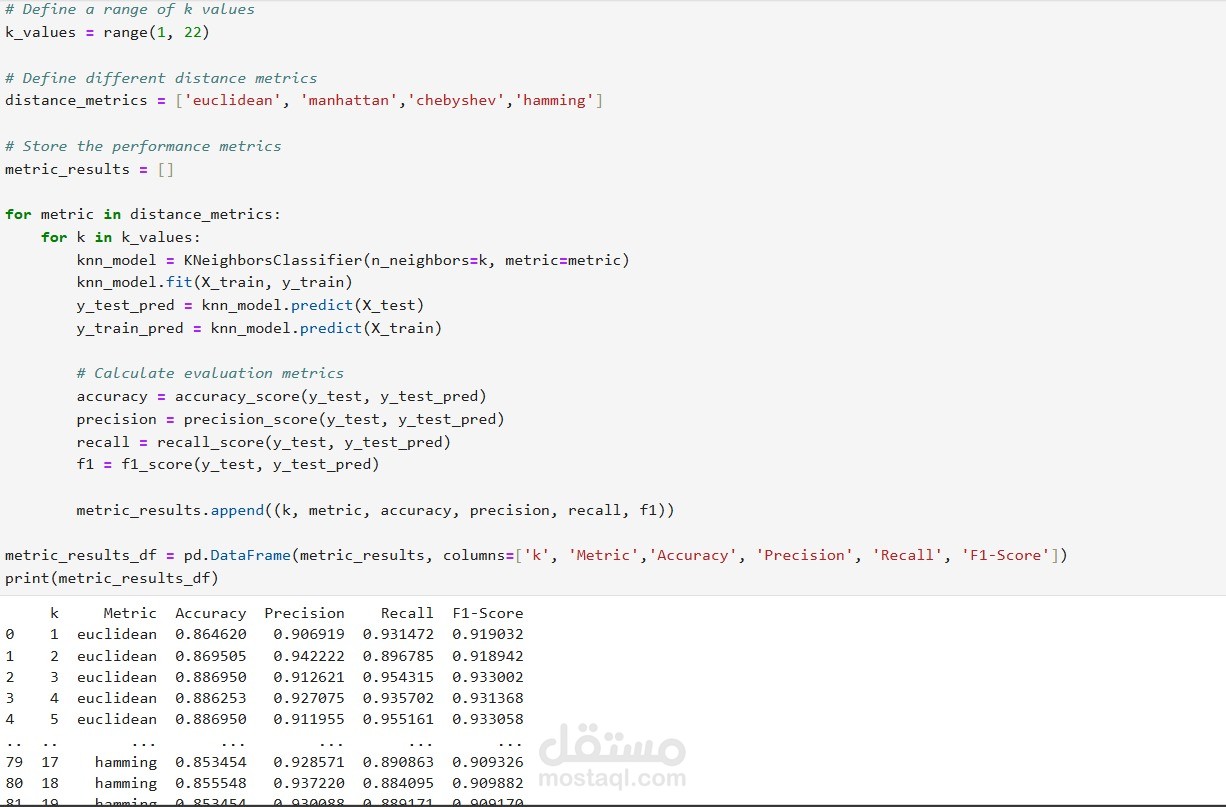
نموذج KNN حقق أعلى دقة (~89%) مع Precision و Recall مرتفعة.
مقارنة أداء النماذج الأخرى:
SVM: دقة 88%
Decision Tree: دقة 86% (موديل قابل للتفسير)
Naive Bayes: دقة 63% (أقل فعالية للبيانات)
رسم بياني يوضح تغير دقة نموذج KNN مع قيم مختلفة لـ k
Confusion Matrix لتوضيح دقة التصنيف على عينات البيانات
الفائدة من المشروع:
استخراج رؤى دقيقة من البيانات الصحية المتعلقة بالصلع.
توفير نموذج تنبؤ يمكن استخدامه في تطبيقات بحثية أو صحية.
مقارنة الخوارزميات تساعد على اختيار النموذج الأمثل حسب البيانات.