Data Analysis and Machine Learning Price Prediction of Data Science Books
تفاصيل العمل
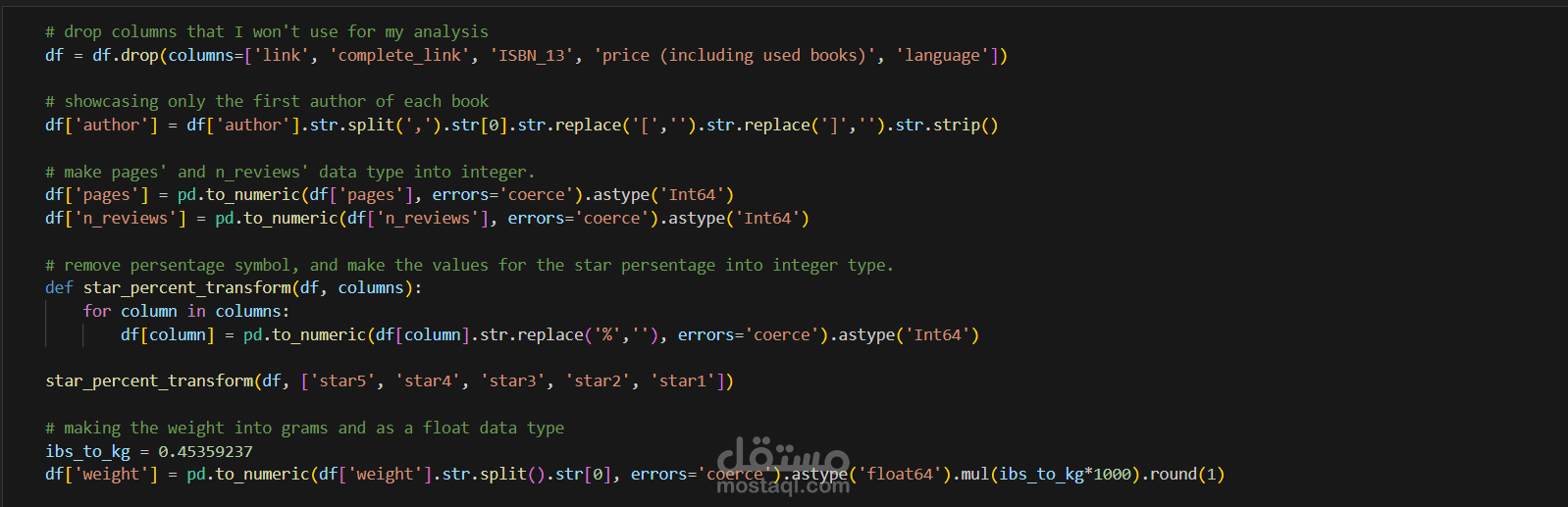
The provided Jupyter Notebook analyzes and predicts the prices of data science books. It uses a dataset from Kaggle and includes several key steps:
Data Preprocessing and Feature Engineering: The notebook cleans the data, handles missing values, and creates new features like book size and publication year.
Exploratory Data Analysis (EDA): The analysis explores questions such as: "Which author wrote the most books?", "Are newer books more expensive?", and "What are the most common words in book titles?".
Machine Learning: Several models were trained to predict book prices. The best-performing model, a GradientBoostingRegressor, achieved an R2 score of 0.41.