Mushroom Classification
تفاصيل العمل
تحليل البيانات الاستكشافي (EDA):
فحص شكل البيانات والأعمدة وأنواعها.
تحديد القيم المفقودة ومعالجتها.
تنظيف البيانات ومعالجتها:
تقسيم البيانات إلى مجموعات تدريب واختبار.
معالجة البيانات الرقمية والفئوية بشكل منفصل باستخدام ColumnTransformer.
بناء خط أنابيب معالجة البيانات (Preprocessing pipeline).
بناء وتدريب نماذج التصنيف:
تدريب 6 نماذج مختلفة:
Logistic Regression
Decision Tree
Random Forest
SVM
K-Nearest Neighbors (KNN)
Naive Bayes
تقييم أداء كل نموذج باستخدام مقاييس الدقة والتقارير التفصيلية.
تحسين النماذج:
استخدام تقنيات ضبط المعلمات لتحسين أداء النماذج.
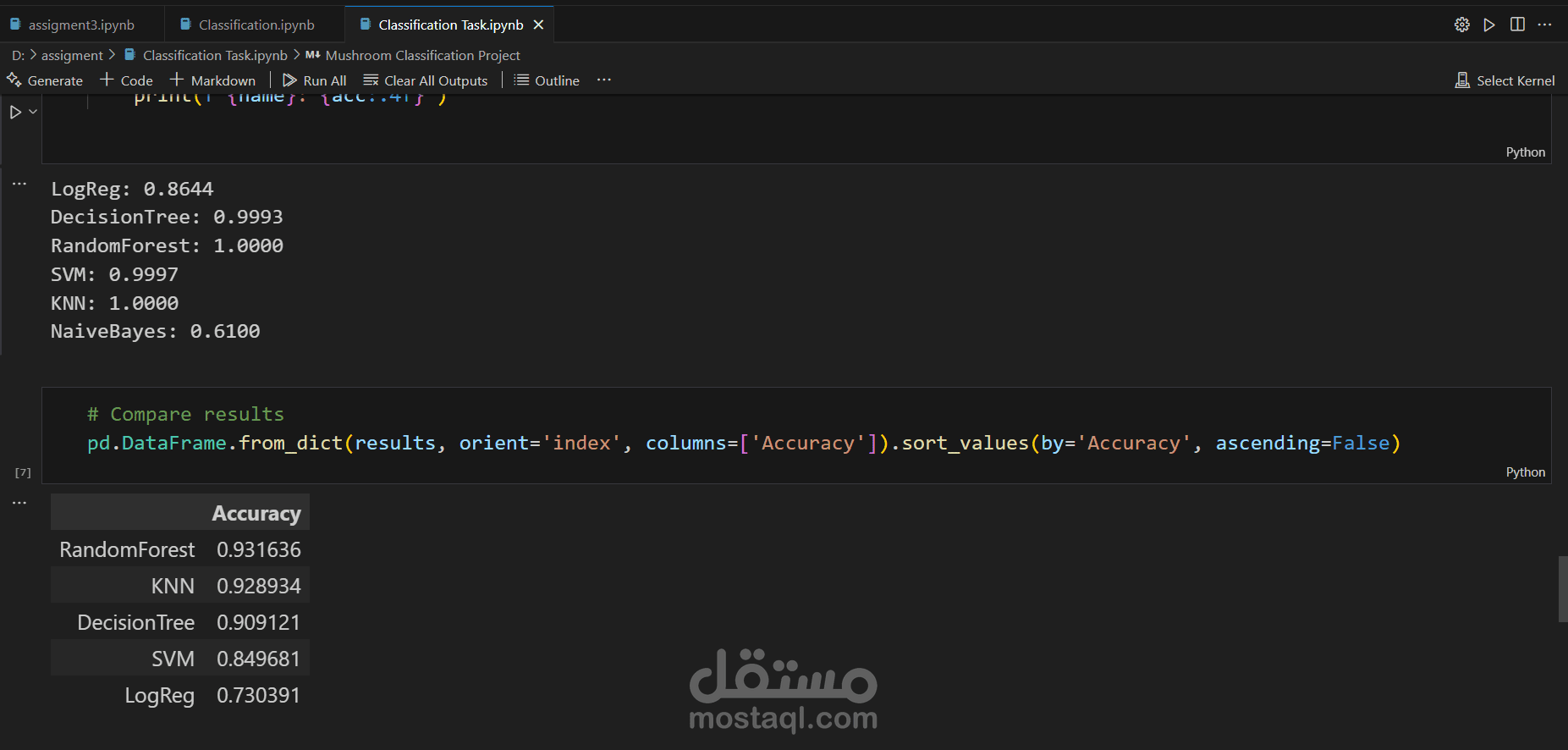
مقارنة النماذج:
مقارنة أداء النماذج بناءً على الدقة ومنحنيات ROC.
تحديد أفضل نموذج (Random Forest في هذه الحالة).
حفظ النموذج النهائي:
حفظ نموذج Random Forest المُحسَّن باستخدام pickle لاستخدامه في التنبؤات المستقبلية.