Classification
تفاصيل العمل
هذا المشروع هو تطبيق عملي للتعلم الآلي لتصنيف الخلايا السرطانية في الثدي إلى خبيثة (Malignant - M) أو حميدة (Benign - B) باستخدام مجموعة البيانات الشهيرة "Breast Cancer Wisconsin (Diagnostic)".
الخطوات الرئيسية التي تم تنفيذها:
إعداد البيئة والبيانات:
تم استيراد جميع المكتبات اللازمة (pandas, numpy, matplotlib, seaborn, scikit-learn).
تم تحميل مجموعة البيانات مباشرة من مستودع UCI عبر الرابط الموجود في الكود.
تمت معالجة البيانات الأولية بما في ذلك:
حذف عمود "ID number" لأنه ليس feature مفيدًا للتنبؤ.
تحويل عمود "Diagnosis" (التشخيص) من قيم نصية (M, B) إلى قيم رقمية (1, 0) لتكون متوافقة مع خوارزميات التعلم الآلي.
تحليل البيانات الاستكشافي (EDA):
تم عرض أول 5 صفوف من البيانات لفهم هيكلها.
تم فحص شكل DataFrame (عدد الصفوف والأعمدة).
تم الحصول على معلومات عامة عن أنواع البيانات والقيم غير المفقودة (df.info()).
تم إنشاء إحصائيات وصفيّة (مثل المتوسط، الانحراف المعياري، القيم الدنيا والعليا) لفهم توزيع البيانات (df.describe()).
تم التحقق من وجود قيم مفقودة أو مكررة في البيانات.
هندسة الميزات وتقسيم البيانات:
تم فصل المتغيرات (Features - X) عن المتغير المستهدف (Target - y).
تم تقسيم البيانات إلى مجموعة للتدريب (80%) ومجموعة للاختبار (20%) باستخدام train_test_split مع ثابت random_state لضمان إمكانية إعادة النتائج.
تم تطبيع البيانات (Feature Scaling) باستخدام StandardScaler لضمان أن جميع الميزات على نفس المقياس، مما يحسن أداء خوارزمية الانحدار اللوجستي.
بناء وتدريب النموذج:
تم إنشاء نموذج الانحدار اللوجستي (LogisticRegression) مع زيادة max_iter لضمان التقارب.
تم تدريب النموذج على بيانات التدريب (X_train, y_train) باستخدام الدالة fit().
تقييم أداء النموذج:
تم استخدام النموذج المدرب للتنبؤ بقيم مجموعة الاختبار (y_pred).
تم حساب وتقديم مقاييس الأداء الرئيسية:
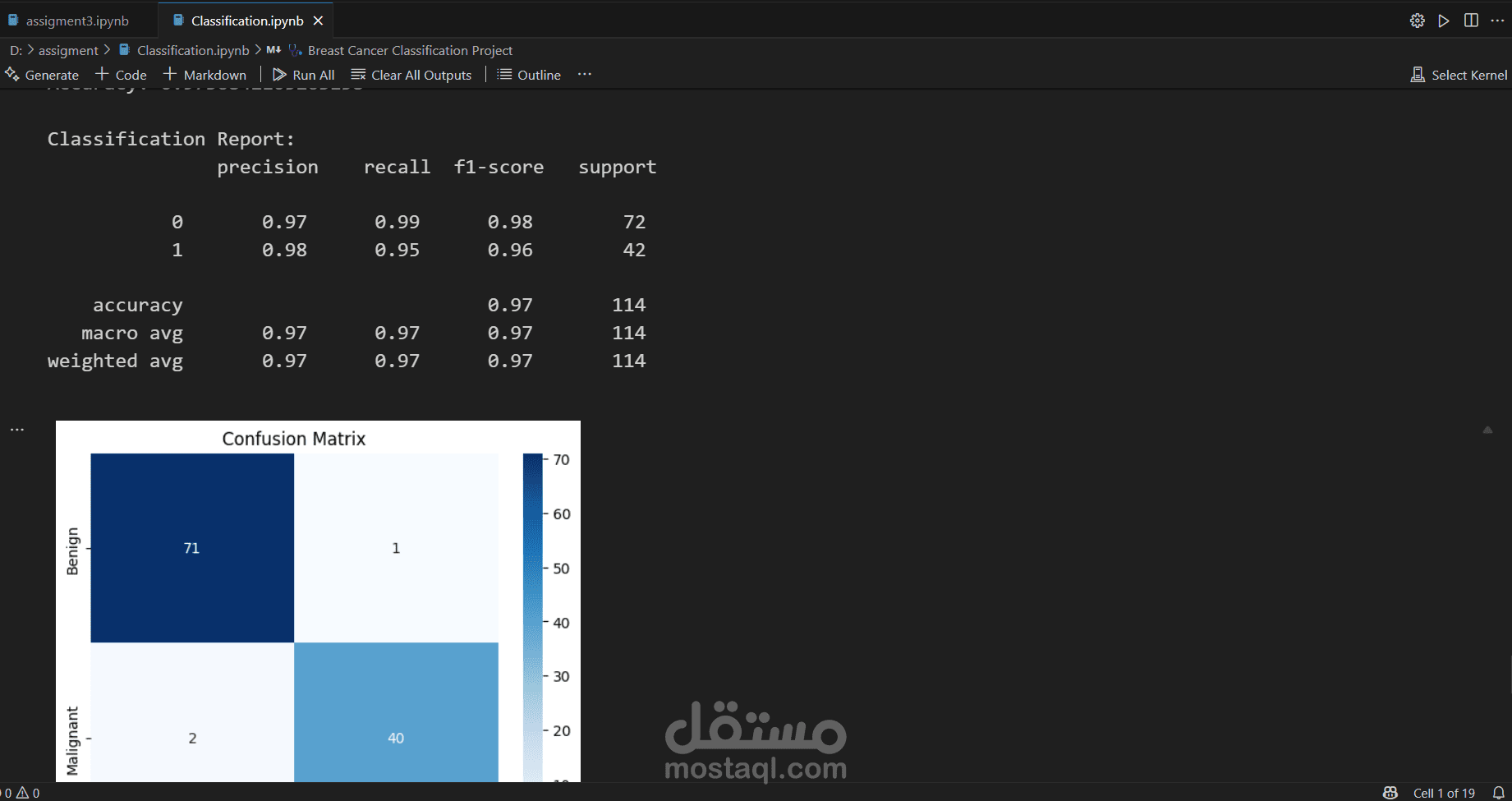
الدقة (Accuracy): 97.37% - وهي نسبة عالية جدًا تشير إلى أداء ممتاز للنموذج على بيانات الاختبار.
مصفوفة الالتباس (Confusion Matrix):
70 عينة تم تصنيفها بشكل صحيح كـ "حميدة" (True Negatives).
41 عينة تم تصنيفها بشكل صحيح كـ "خبيثة" (True Positives).
1 عينة تم تصنيفها خطأ كـ "خبيثة" بينما هي "حميدة" (False Positive).
2 عينة تم تصنيفها خطأ كـ "حميدة" بينما هي "خبيثة" (False Negatives). (هذا هو الخطأ الأكثر خطورة في هذا السياق الطبي).
تقرير التصنيف (Classification Report): أظهر نتائج ممتازة لكلتا الفئتين مع:
دقة (Precision) عالية للفئة 1 (الخبيثة): 0.98 (98% من العينات التي صنفت كخبيثة هي خبيثة بالفعل).
استدعاء (Recall) عالي للفئة 0 (الحميدة): 0.99 (تم التعرف على 99% من العينات الحميدة correctly).
نتيجة F1 (F1-Score) عالية لكلا الفئتين (0.98 و 0.96 على التوالي)، وهي متوسط توافقي بين الدقة والاستدعاء.