مشروع سكراب للمواقع
تفاصيل العمل
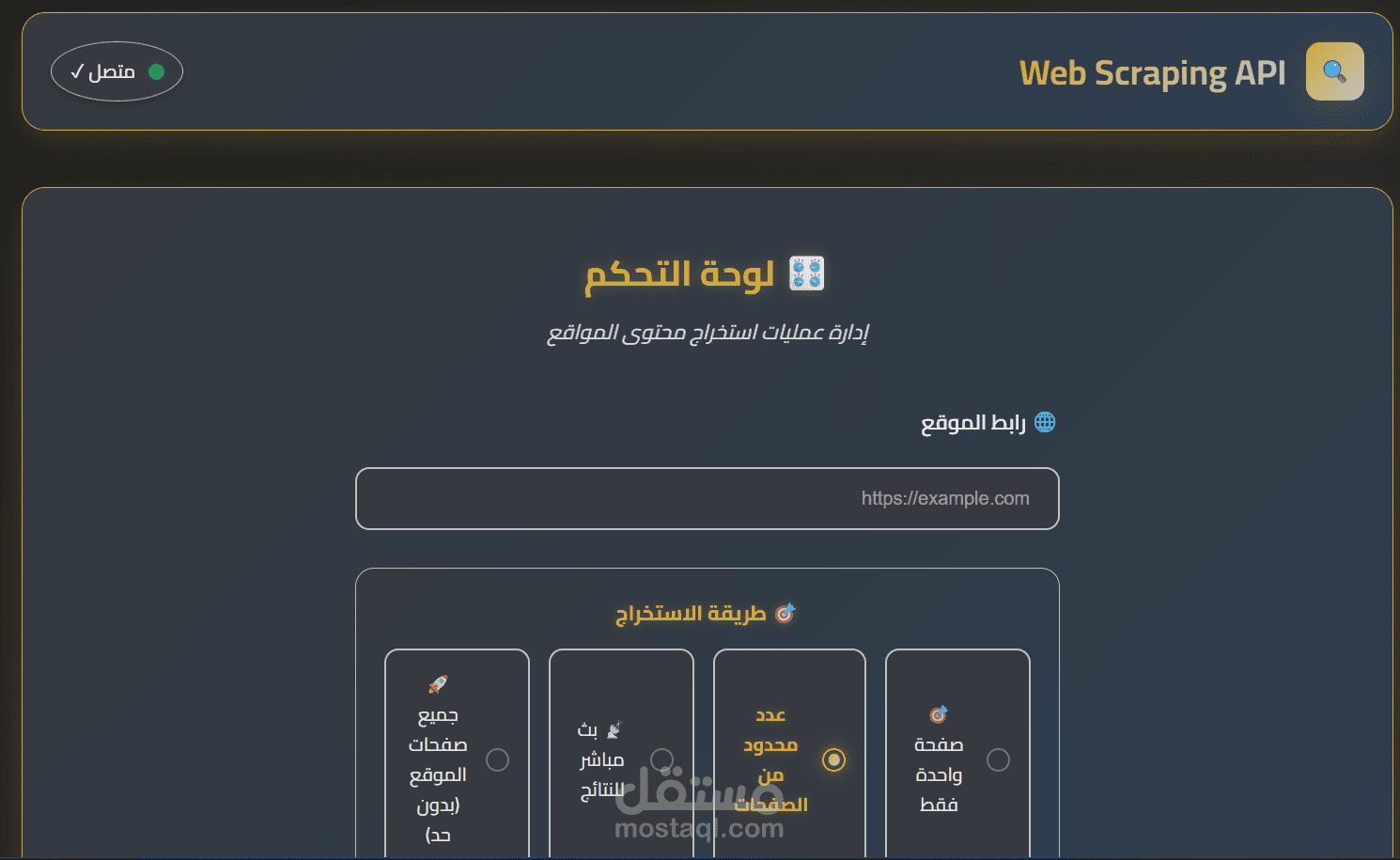
Advanced Web Scraping API
A powerful, professional-grade web scraping platform built with FastAPI, featuring real-time streaming capabilities, intelligent content extraction, and comprehensive security measures.
Python FastAPI License
Key Features
Multiple Scraping Modes
Single Page Extraction - Precise content extraction from individual pages
Limited Batch Scraping - Controlled scraping with customizable page limits
Real-time Streaming - Live results with immediate page-by-page updates
Unlimited Website Crawling - Comprehensive site-wide content extraction
️ Enterprise-Grade Security
Advanced duplicate URL detection and normalization
Domain-restricted crawling for security compliance
Intelligent rate limiting and timeout controls
User-agent rotation to avoid bot detection
Request validation and sanitization
Real-Time Capabilities
Server-Sent Events (SSE) streaming architecture
Live progress tracking and status updates
Non-blocking asynchronous processing
Interactive web interface with Arabic/RTL support
Advanced Content Processing
Enhanced HTML parsing with trafilatura integration
WordPress and modern CMS optimized extraction
Elementor and dynamic content support
Smart content filtering and cleanup
️ Technical Architecture
Backend Stack
Framework: FastAPI with automatic OpenAPI documentation
Language: Python 3.11+ with modern async/await patterns
HTTP Client: Requests library with persistent session management
Content Extraction: BeautifulSoup4 + trafilatura for superior parsing
Data Validation: Pydantic models with automatic serialization
Server: Uvicorn ASGI with hot reload capabilities
Frontend Features
Responsive Arabic-RTL supporting interface
Real-time API health monitoring
Advanced form validation with live feedback
Results management with download/export functionality
3D styling and modern animations
Core Design Principles
Scalable Architecture: Object-oriented design with separation of concerns
Performance Optimized: HTTP session pooling and connection reuse
Security First: Comprehensive input validation and domain restrictions
User Experience: Real-time feedback and intuitive interface design
Quick Start
Prerequisites
Python 3.11 or higher
pip package manager
Installation & Setup
Clone the repository
git clone <repository-url>
cd web-scraping-api
Install dependencies
pip install -r requirements.txt
Start the server
python -m uvicorn main:app --host 0.0.0.0 --port 5000 --reload
Access the application
Web Interface: http://localhost:5000
API Documentation: http://localhost:5000/doc...
Alternative Docs: http://localhost:5000/red...
API Endpoints
Core Scraping Endpoints
POST /scrape-pages
Limited scraping with page count control
{
"url": "https://example.com";,
"max_pages": 50,
"timeout": 10
}
POST /scrape-single
Extract content from a single page
{
"url": "https://example.com/artic...;,
"timeout": 10
}
Real-Time Streaming Endpoints
POST /scrape-stream
Real-time streaming with page limits
{
"url": "https://example.com";,
"max_pages": 100,
"timeout": 10
}
POST /scrape-stream-unlimited
Unlimited website crawling with live updates
{
"url": "https://example.com";,
"timeout": 10
}
Health & Monitoring
GET /health
API health check and status monitoring
Web Interface Usage
Navigate to the web interface at http://localhost:5000
Enter target URL in the input field
Select scraping mode:
Single page only
Limited pages (specify count)
Real-time streaming
Unlimited website scraping
Configure settings (max pages, timeout)
Start scraping and monitor real-time progress
Download or export results in JSON format
️ Configuration Options
Scraping Parameters
URL: Target website URL (required)
Max Pages: Page limit for controlled scraping (1-500)
Timeout: Request timeout per page (5-60 seconds)
Security Controls
Domain Restriction: Automatic same-domain enforcement
Rate Limiting: Built-in request throttling
Duplicate Prevention: Advanced URL normalization
Content Filtering: Smart content extraction
Advanced Features
URL Normalization & Deduplication
Removes tracking parameters (UTM, fbclid, etc.)
Handles URL fragments and anchors
Case-insensitive domain matching
Path normalization and canonicalization
Content Extraction Intelligence
WordPress-optimized parsing
Modern CMS compatibility
Dynamic content handling
Article structure detection
Performance Optimizations
HTTP connection pooling
Session management and reuse
Async/await processing
Memory-efficient streaming
Response Format
Standard Response
{
"url": "https://example.com/page&...;,
"title": "Page Title",
"content": "Extracted content...",
"links": ["https://example.com/link1...;],
"timestamp": "2025-08-13T10:30:00Z",
"word_count": 1250
}
Streaming Response Format
{
"type": "page",
"data": {
"url": "https://example.com/page&...;,
"title": "Page Title",
"content": "Content...",
"links": ["..."],
"timestamp": "2025-08-13T10:30:00Z"
},
"progress": {
"current": 15,
"total": 100,
"percentage": 15
}
}
️ Security & Compliance
Built-in Protections
Domain validation and restriction
Request rate limiting
Input sanitization
URL validation
Timeout enforcement
Memory usage controls
Best Practices
Always respect robots.txt
Implement appropriate delays between requests
Monitor server resources during large operations
Use reasonable page limits for batch operations
Error Handling
The API provides comprehensive error responses:
400 Bad Request: Invalid URL or parameters
404 Not Found: Page or resource not accessible
429 Too Many Requests: Rate limit exceeded
500 Internal Server Error: Server processing error
Performance Metrics
Typical Performance
Single Page: 1-3 seconds per page
Batch Scraping: 50-100 pages per minute
Memory Usage: ~50MB for standard operations
Concurrent Requests: Up to 10 simultaneous streams
? Contributing
We welcome contributions! Please follow these steps:
Fork the repository
Create a feature branch (git checkout -b feature/amazing-feature)
Commit your changes (git commit -m 'Add amazing feature')
Push to the branch (git push origin feature/amazing-feature)
Open a Pull Request
License
This project is licensed under the MIT License - see the LICENSE file for details.
Credits
Developed by: Eng. Amr Hossam
Architecture: FastAPI + Python 3.11+
Frontend: Modern JavaScript with Arabic RTL support
Links
Documentation: API Docs
Alternative Docs: ReDoc
Health Check: Status