Penguins Species Clustring
تفاصيل العمل
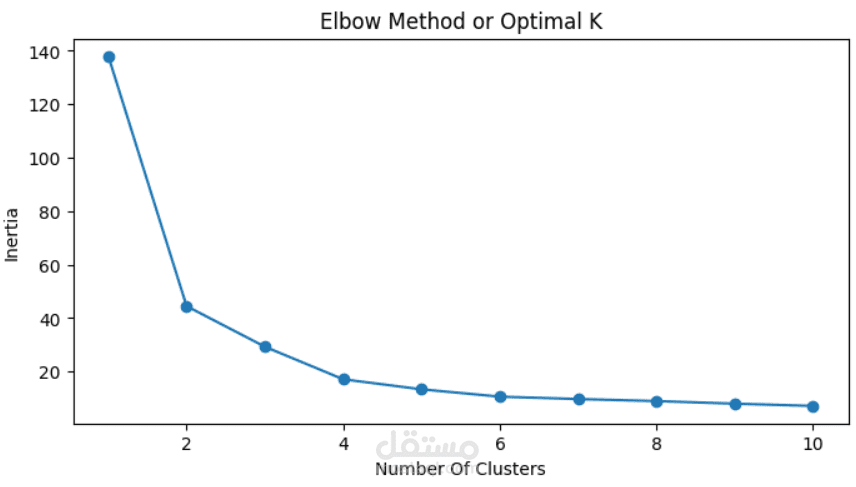
This project applies unsupervised machine learning techniques to group penguin species based on their biological characteristics. The dataset includes physical measurements such as bill length, bill depth, flipper length, and body mass, along with categorical features like island and sex.
The workflow covers:
Data Cleaning & Preprocessing: Handling missing values, encoding categorical variables, and scaling numerical features.
Clustering Techniques: Implemented K-Means and DBSCAN algorithms to identify natural clusters in the penguin population.
Evaluation: Compared cluster quality using silhouette scores and visualized clusters in feature space to assess biological relevance.
Key Insights:
K-Means successfully grouped penguins into distinct clusters resembling species boundaries.
DBSCAN helped detect noise/outliers, offering insights into rare or unique samples.