تنبو باسعار السيارات
تفاصيل العمل
هذا المشروع يهدف إلى بناء نموذج للتنبؤ بأسعار السيارات بناءً على خصائصها المختلفة مثل السنة، سعر البيع الحالي، المسافة المقطوعة، نوع الوقود، نوع البيع، ناقل الحركة، وعدد المالكين السابقين. تم استخدام تقنيات تعلم الآلة لتحليل البيانات وبناء نموذج تنبؤ دقيق.
---
**الخطوات الرئيسية:**
### 1. استيراد المكتبات
تم استيراد المكتبات الأساسية مثل:
- `pandas` و `numpy` لمعالجة البيانات.
- `matplotlib` و `seaborn` للتصورات البيانية.
- `scikit-learn` لتقسيم البيانات، المعالجة، والنمذجة.
---
### 2. قراءة البيانات
تم تحميل بيانات السيارات من ملف `car data.csv`.
---
### 3. تنظيف البيانات
- **البيانات الناقصة:** لم يكن هناك أي قيم ناقصة.
- **البيانات المكررة:** تم حذف سجلين مكررين.
- **الشكل النهائي:** أصبحت البيانات تحتوي على 299 سجلاً و9 أعمدة.
---
### 4. التعامل مع القيم المتطرفة (Outliers)
- تم تحديد القيم المتطرفة باستخدام مخططات الصندوق (Boxplots) للأعمدة الرقمية.
- تمت إزالة القيم المتطرفة باستخدام قاعدة IQR (الربيع الأول والثالث).
- أصبح شكل البيانات بعد الإزالة 253 سجلاً.
---
### 5. تحليل البيانات واستكشافها
(ملاحظة: لم يتم عرض هذا الجزء في الكود، لكنه يشمل عادةً)
- دراسة العلاقات بين المتغيرات.
- استخدام مصفوفات الارتباط والرسوم البيانية لفهم البيانات.
---
### 6. تقسيم البيانات
- تم تقسيم البيانات إلى متغيرات مستقلة (Features) ومتغير تابع (Target).
- المتغير التابع: `Selling_Price` (سعر البيع).
- المتغيرات المستقلة: `Year`, `Present_Price`, `Driven_kms`, `Fuel_Type`, `Selling_type`, `Transmission`, `Owner`.
---
### 7. ترميز المتغيرات الفئوية (Categorical Encoding)
- تم تحويل المتغيرات الفئوية (`Fuel_Type`, `Selling_type`, `Transmission`) إلى قيم رقمية باستخدام `OneHotEncoder`.
---
### 8. تقسيم البيانات إلى تدريب واختبار
- تم تقسيم البيانات إلى 80% تدريب و20% اختبار.
---
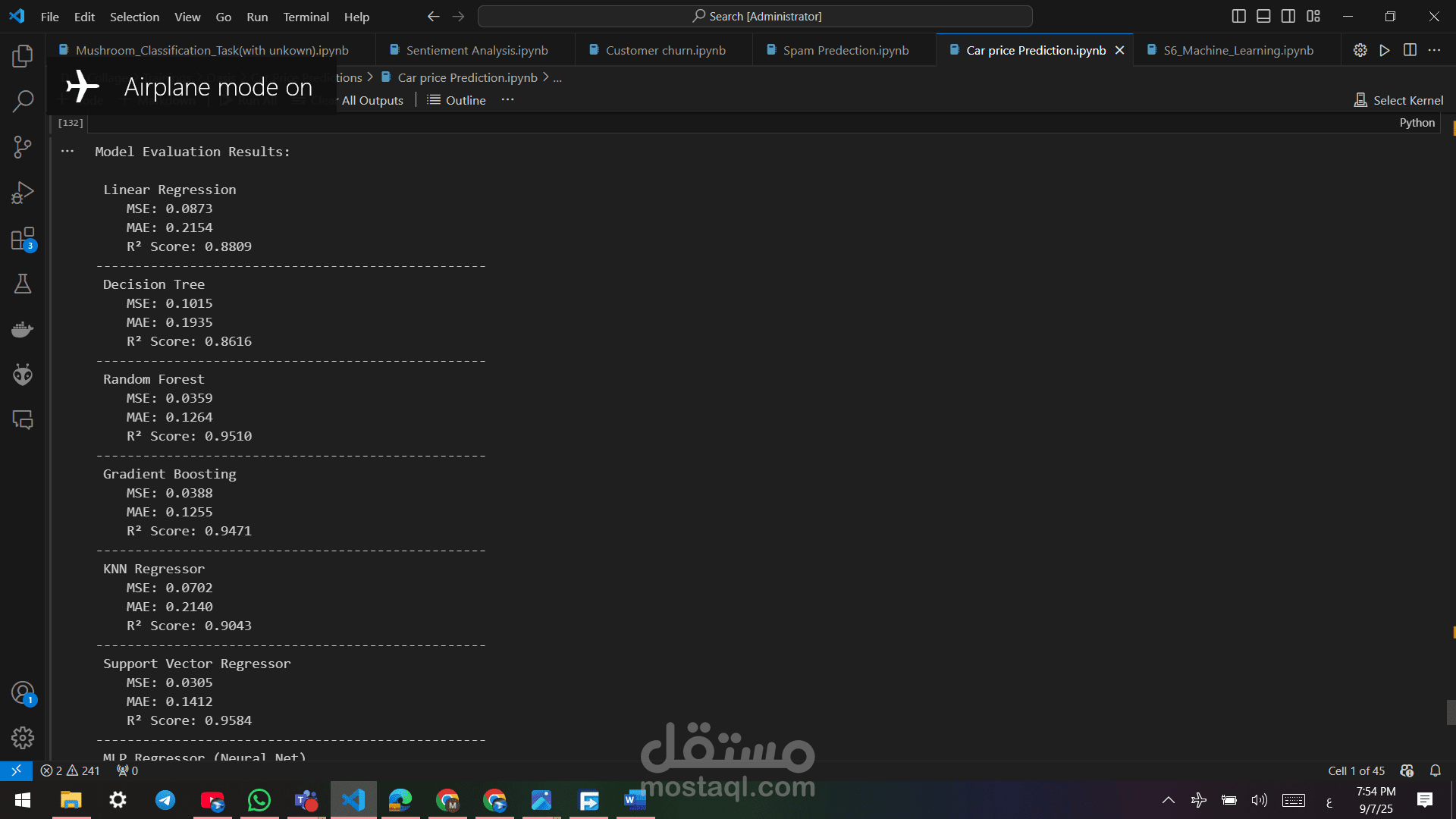
### 9. تطبيق النماذج وتقييمها
تم تجربة عدة نماذج وتقييمها باستخدام:
- `Mean Absolute Error` (MAE)
- `Mean Squared Error` (MSE)
- `R-squared` (R²)
#### النماذج المستخدمة:
1. **الانحدار الخطي (Linear Regression)**
2. **Lasso Regression**
3. **Random Forest Regressor**
4. **Gradient Boosting Regressor**
#### النتائج:
- نموذج **Random Forest** حقق أفضل أداء بـ:
- MAE: 0.64
- MSE: 0.89
- R²: 0.93
---
### 10. استنتاجات وتوصيات
- نموذج **Random Forest** هو الأفضل للتنبؤ بأسعار السيارات في هذه البيانات.
- يمكن تحسين النموذج أكثر عن طريق:
- ضبط المعاملات (Hyperparameter Tuning).
- جمع المزيد من البيانات لتحسين دقة النموذج.
- تجربة نماذج أخرى مثل XGBoost أو Neural Networks.