نظام كشف البريد المزعج
تفاصيل العمل
نظرة عامة على المشروع
هذا المشروع يهدف إلى بناء نموذج تصنيف للبريد الإلكتروني لتحديد ما إذا كان بريداً عادياً (ham) أو سبام (spam). تم استخدام عدة خوارزميات تعلم آلي ومقارنة أدائها.
الخطوات الرئيسية
1. استيراد المكتبات
تم استيراد جميع المكتبات الضرورية بما في ذلك:
pandas و numpy لمعالجة البيانات
scikit-learn لخوارزميات التعلم الآلي والتقييم
nltk للمعالجة اللغوية الطبيعية
matplotlib للتصورات
2. تحميل البيانات واستكشافها
البيانات الأصلية تحتوي على 5 أعمدة، تم الاحتفاظ بالعمودين الأساسيين فقط (v1 للتصنيف و v2 للنص)
تمت إعادة تسمية الأعمدة إلى 'label' و 'email'
تمت إزالة البيانات المكررة (403 سجل مكرر)
3. تنظيف البيانات ومعالجتها
تمت إزالة علامات الترقيم والروابط والإيموجيات
تحويل النص إلى أحرف صغيرة
إزالة الكلمات غير الضرورية (stopwords)
تم تحويل التصنيف إلى قيم رقمية (ham: 0, spam: 1)
4. تمثيل النص (Text Representation)
استخدام تقنية TF-IDF لتحويل النص إلى تمثيل رقمي
تم تحديد 5000 خاصية كحد أقصى
5. تقسيم البيانات
تقسيم البيانات إلى 80% تدريب و 20% اختبار
6. بناء وتقييم النماذج
تم تجربة أربعة نماذج مختلفة:
أ. الانحدار اللوجستي (Logistic Regression)
دقة: 95%
أداء جيد ولكن recall منخفض للسبام (66%)
ب. naive bayes (MultinomialNB)
دقة: 97%
أداء أفضل من الانحدار اللوجستي
recall للسبام: 79%
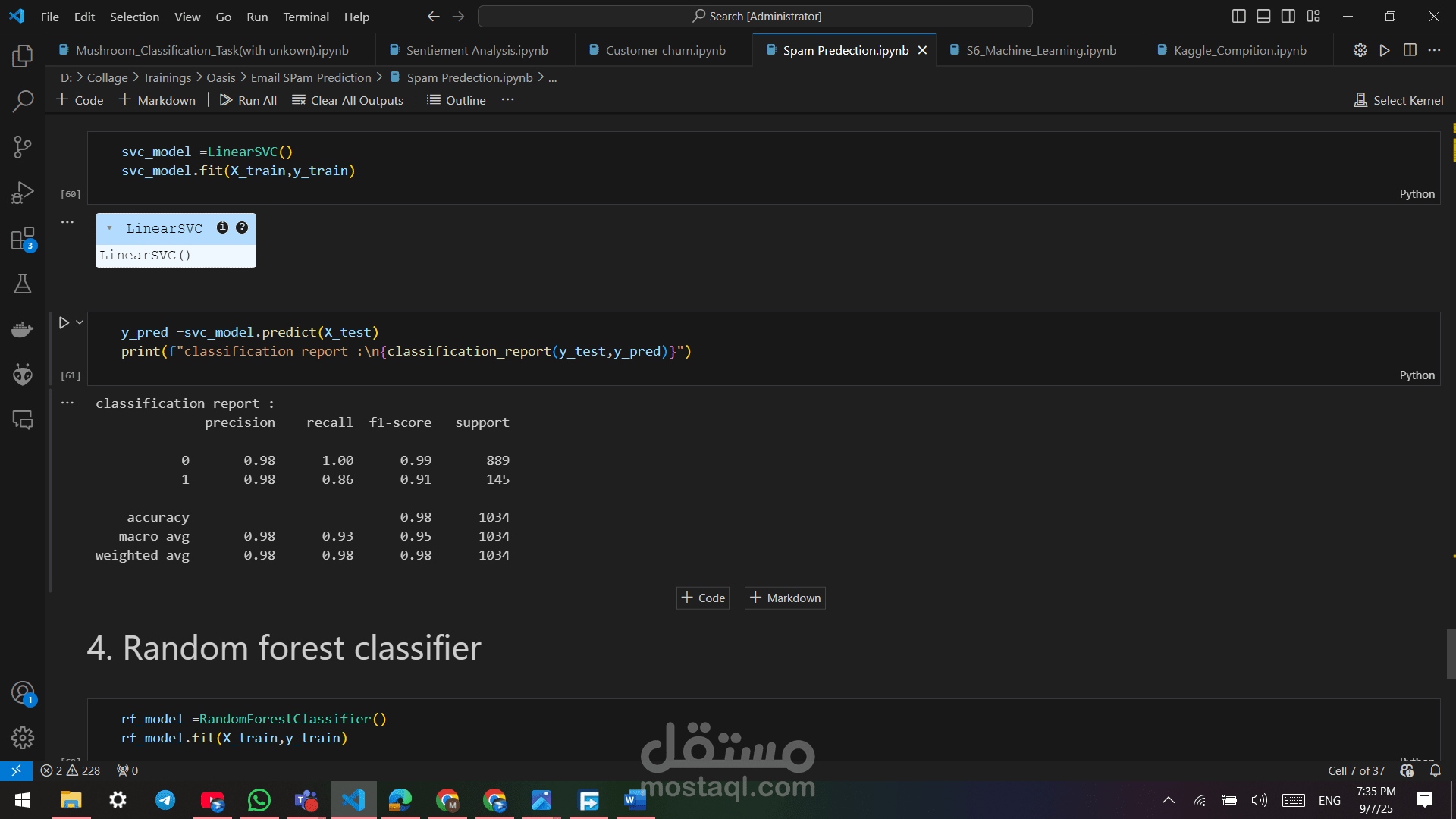
ج. Support Vector Classifier (SVC) - الأفضل
دقة: 98%
precision للسبام: 98%
recall للسبام: 86%
f1-score للسبام: 91%
د. Random Forest
دقة: 97%
أداء جيد جداً ولكن أقل قليلاً من SVC
التوصيات
نموذج SVC هو الأفضل ويوصى باستخدامه للنشر
يمكن تحسين الأداء أكثر عن طريق:
ضبط معاملات النموذج (Hyperparameter Tuning)
استخدام تقنيات أكثر تطوراً لمعالجة اللغة الطبيعية
جمع المزيد من البيانات خاصة للفئة spam لتحسين التوازن
النموذج جاهز للتطبيق في نظام تصفية البريد الإلكتروني مع دقة 98%
ملاحظة: تم معالجة مشكلة عدم التوازن في البيانات حيث أن 87% من البيانات هي ham و13% spam، مما قد يؤثر على أداء النموذج مع فئة السبام.