مشروع تصنيف بالتعلم الآلي – التنبؤ بالدخل
تفاصيل العمل


اللغة والتقنيات: Python
مكتبات: Pandas, NumPy, Matplotlib, Seaborn, Scikit-Learn
معالجة البيانات:
- تنظيف البيانات والتعامل مع القيم المفقودة
- اكتشاف والتعامل مع القيم المتطرفة (Outliers)
- ترميز البيانات النصية (Encoding)
تقنيات التحسين:
- استخدام StandardScaler لتقييس البيانات
- تطبيق PCA لتقليل الأبعاد وتحسين الأداء
النماذج المستخدمة:
- Logistic Regression
- Decision Tree
- Random Forest
- Support Vector Machine (SVM)
- K-Nearest Neighbors (KNN)
تحسين النتائج:
- استخدام GridSearchCV لاختيار أفضل معاملات للنماذج
- تطبيق Voting Classifier (Ensemble) لزيادة دقة التنبؤ
مميزات المشروع:
- مشروع متكامل يبدأ من تحليل البيانات (EDA) حتى بناء النماذج النهائية.
- مقارنة بين عدة خوارزميات لتحديد الأفضل من حيث الدقة.
- الاعتماد على تقنيات حديثة مثل PCA وEnsemble Learning لتحسين الأداء.
- قابلية إعادة الاستخدام مع بيانات مشابهة في مجالات مختلفة (تصنيف، تنبؤ).
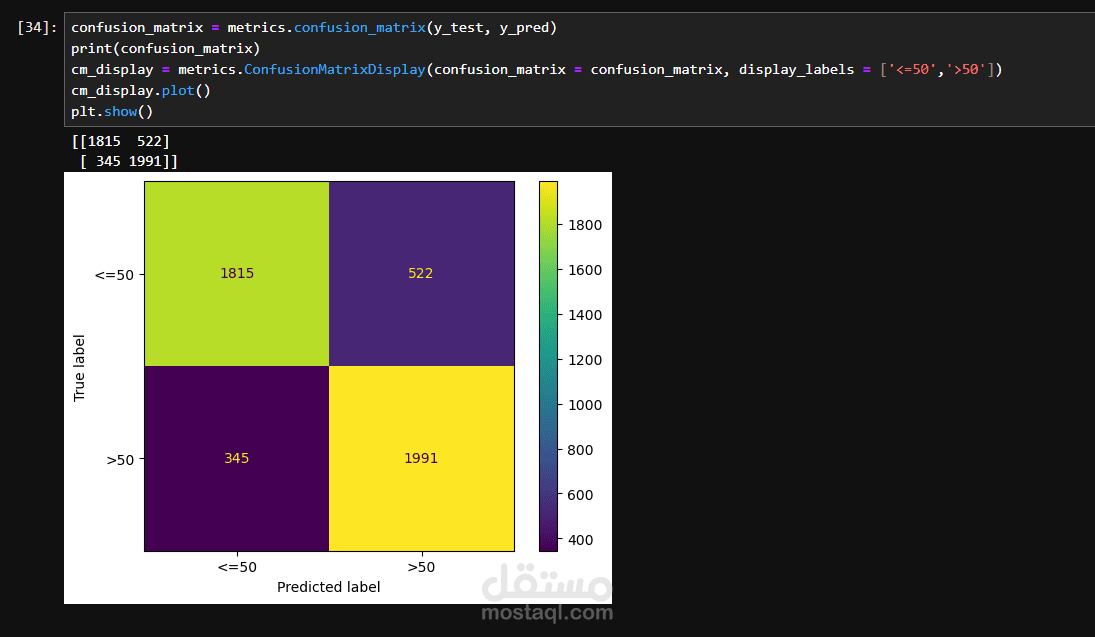
- عرض نتائج واضحة من خلال تقارير الأداء (Confusion Matrix، Accuracy، Classification Report).