shopping_trends
تفاصيل العمل

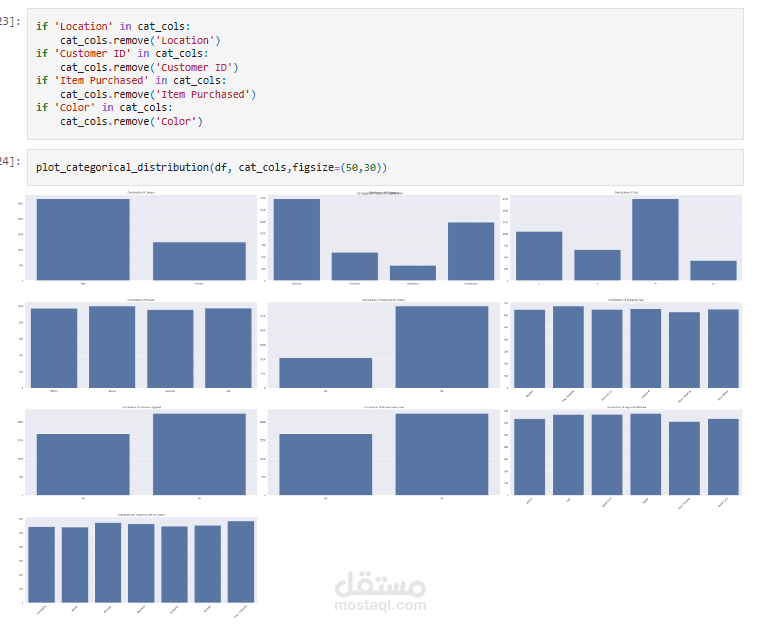
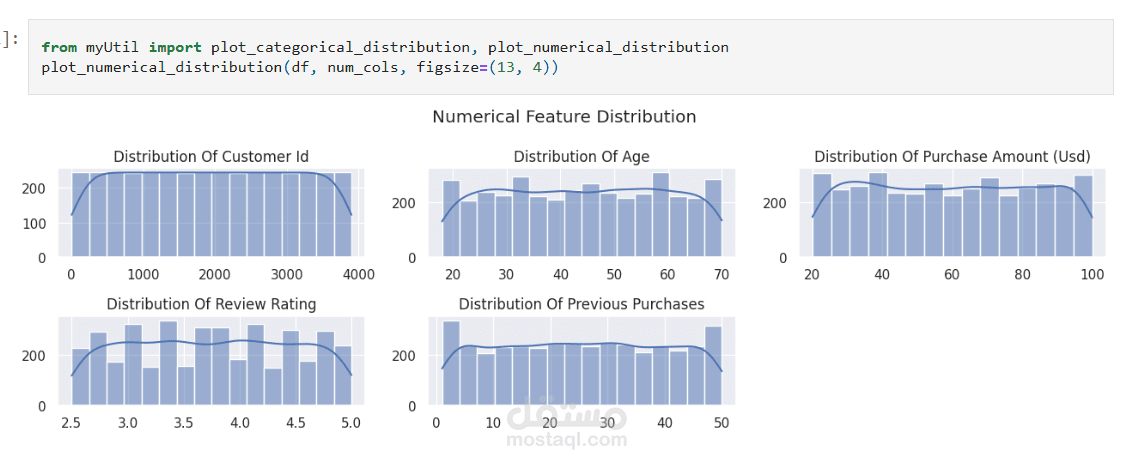
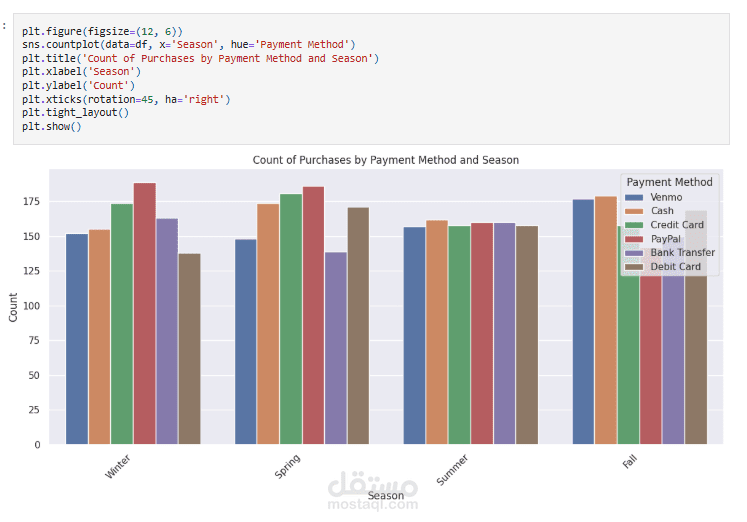
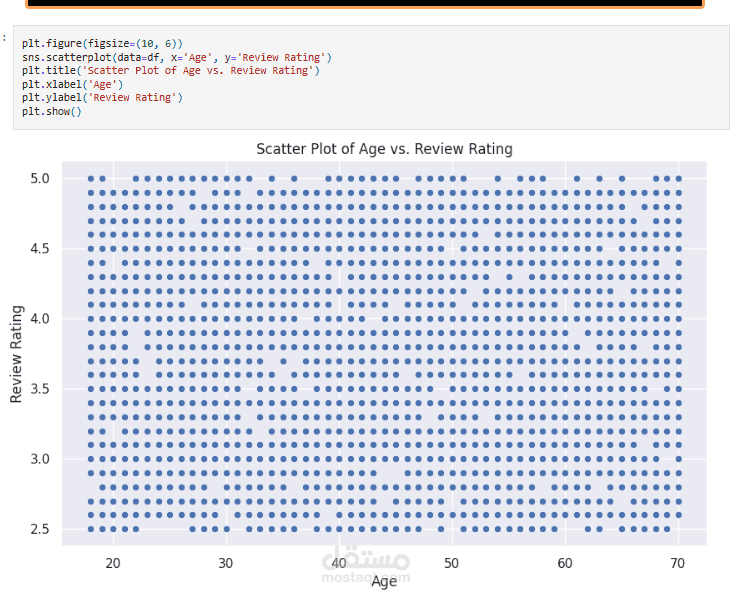
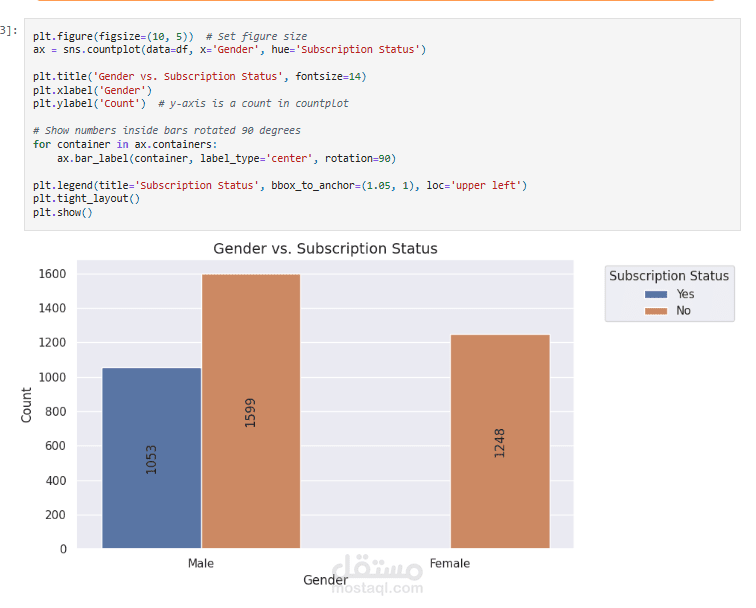
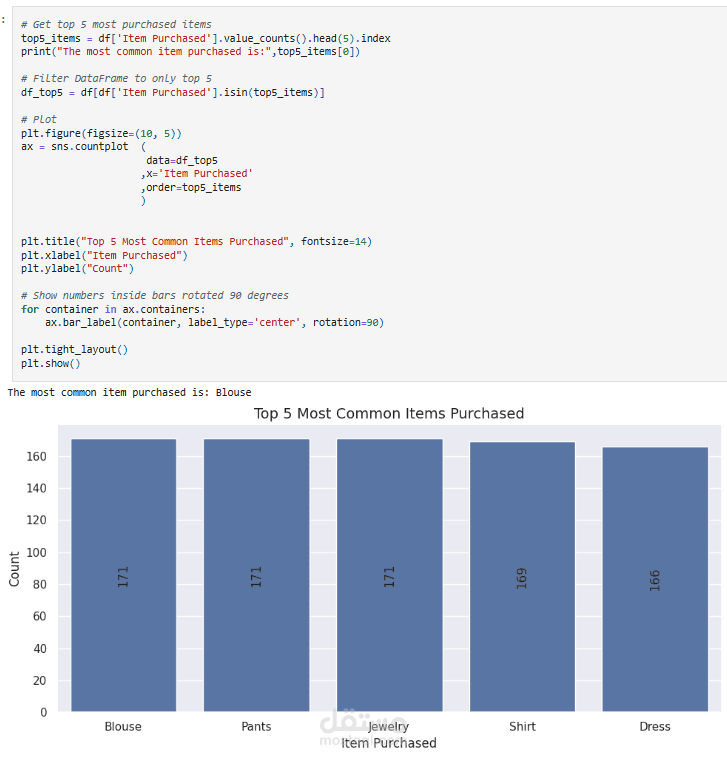
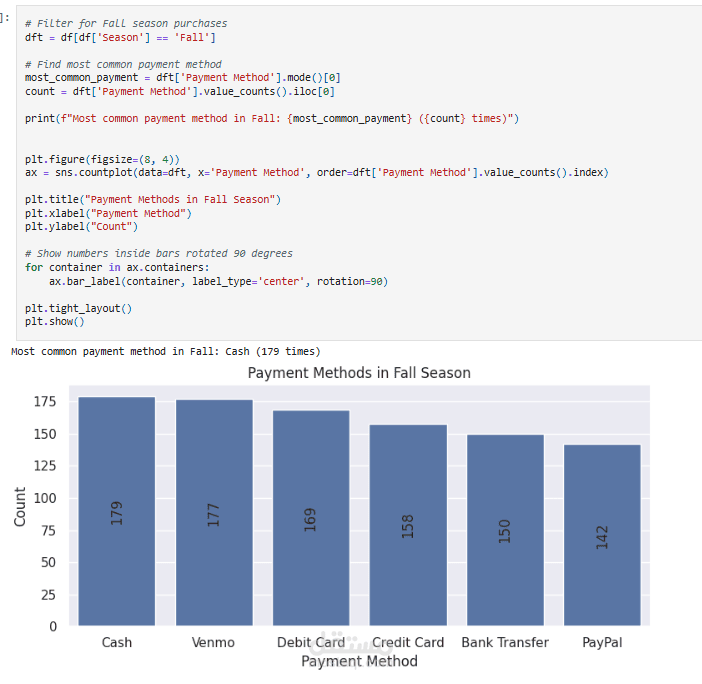
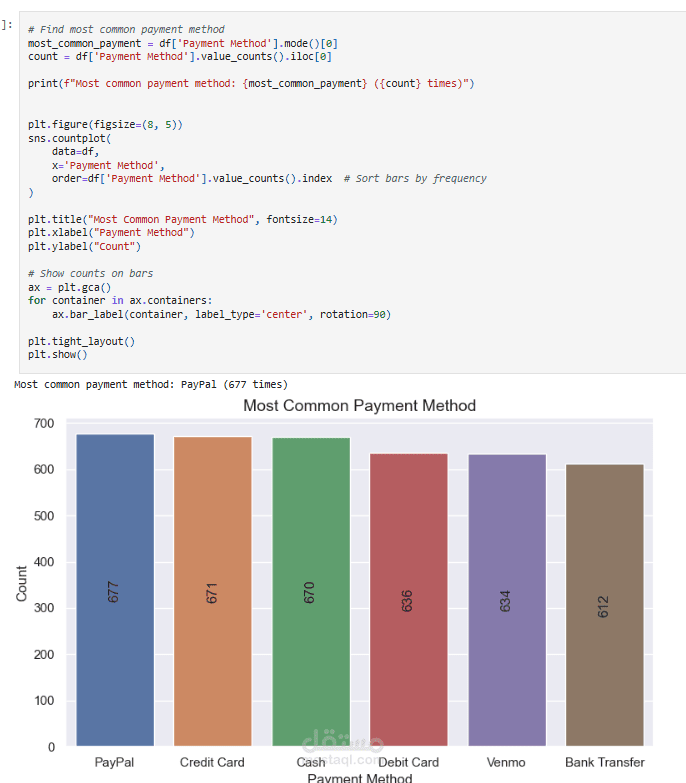
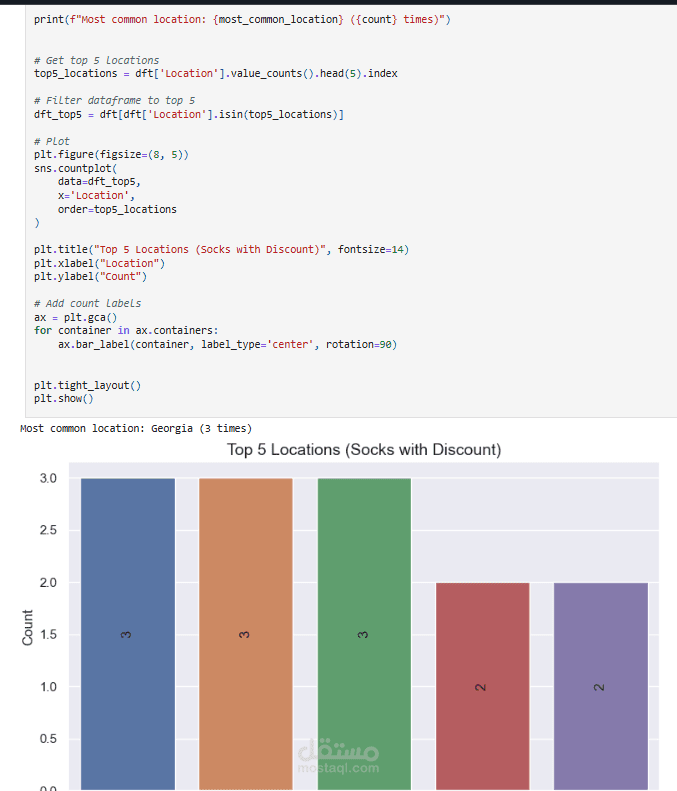
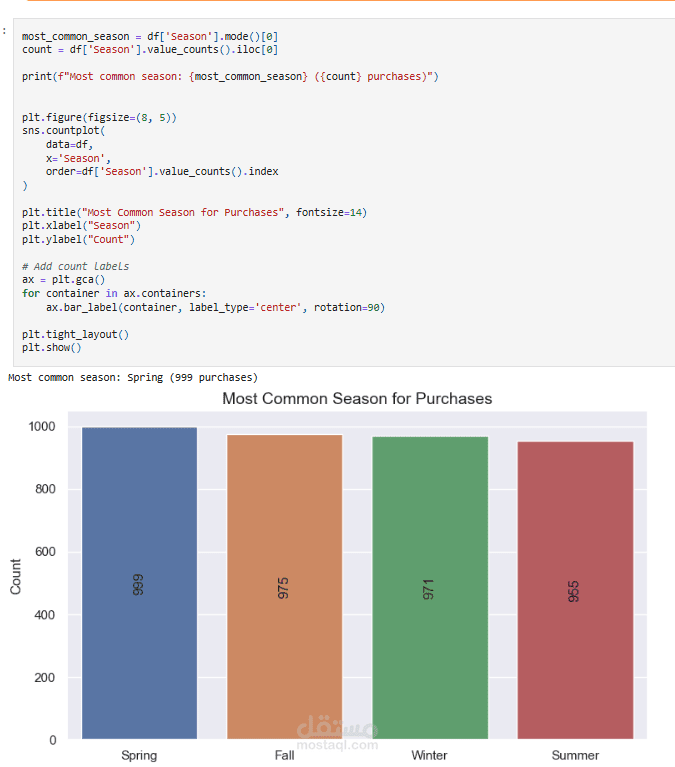
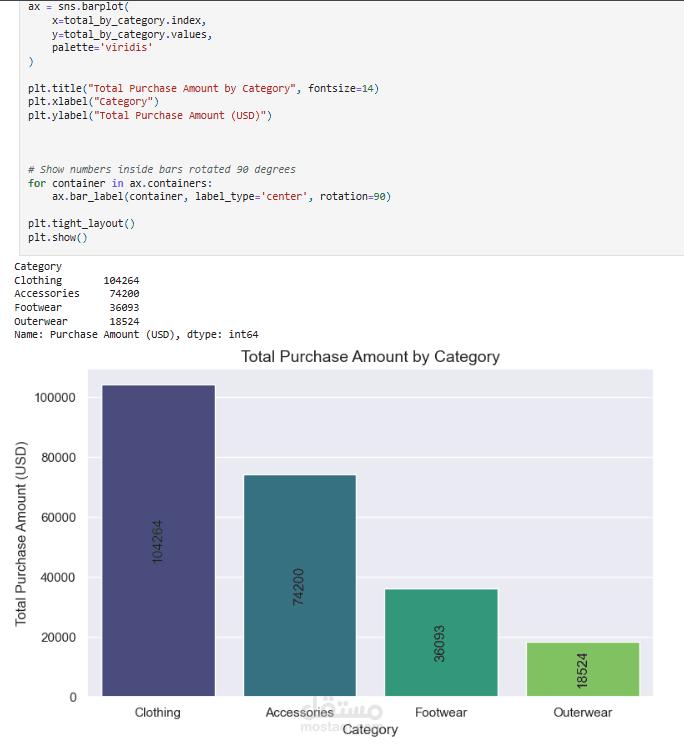
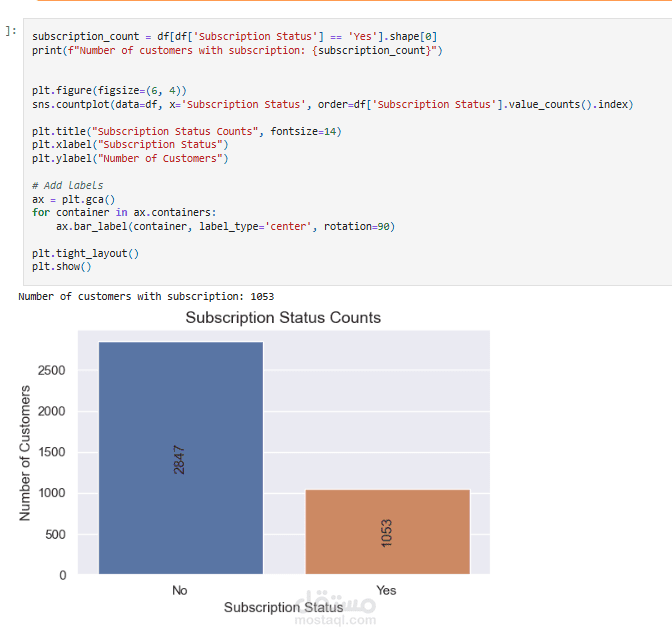
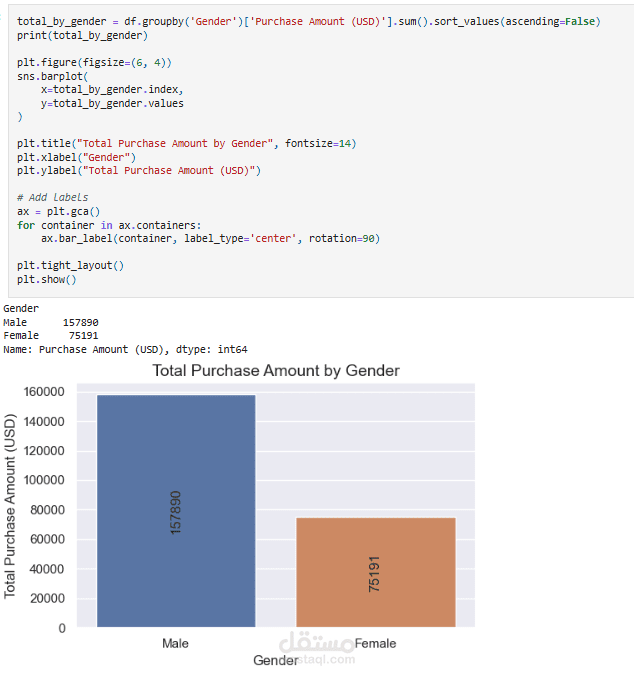
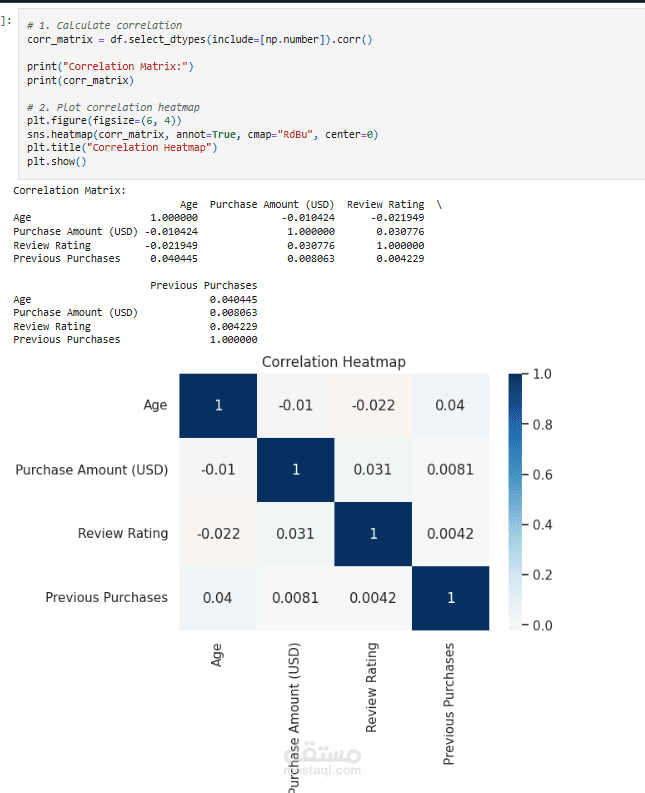
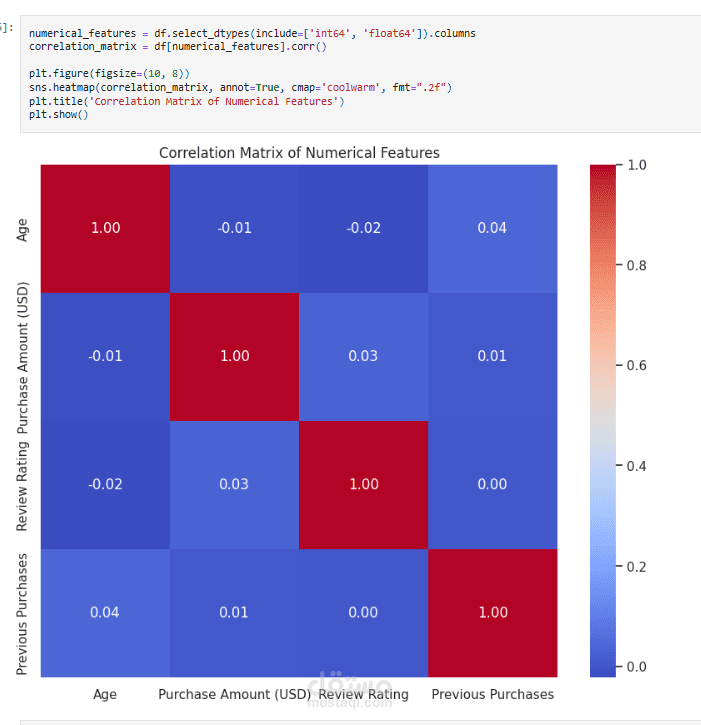
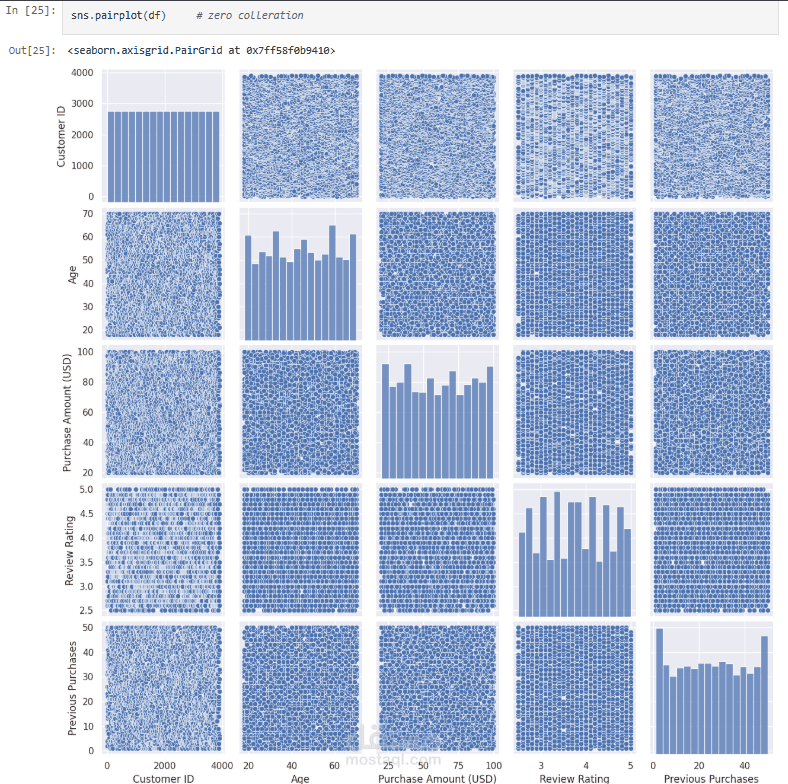
عملت على تحليل Customer Shopping Preferences Dataset (3900 سجل) وهو قاعدة بيانات تركيبية مُعدة لتعليم أساسيات تحليل البيانات وتعلم الآلة. الهدف من المشروع هو استخراج أنماط سلوك المستهلكين وفهم تفضيلاتهم الشرائية لمساعدة الشركات على اتخاذ قرارات أفضل وتطوير استراتيجيات تسويقية أكثر فاعلية.
مراحل العمل (Pipeline):
Data Loading & Inspection: تحميل البيانات باستخدام Pandas وفحص البنية، الأعمدة، والأنواع (categorical & numerical).
Data Cleaning: معالجة القيم المفقودة وإزالة التكرارات.
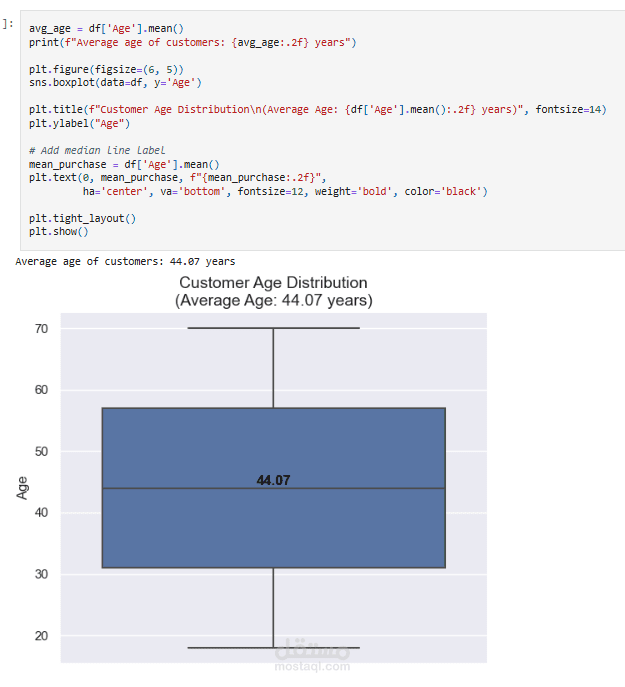
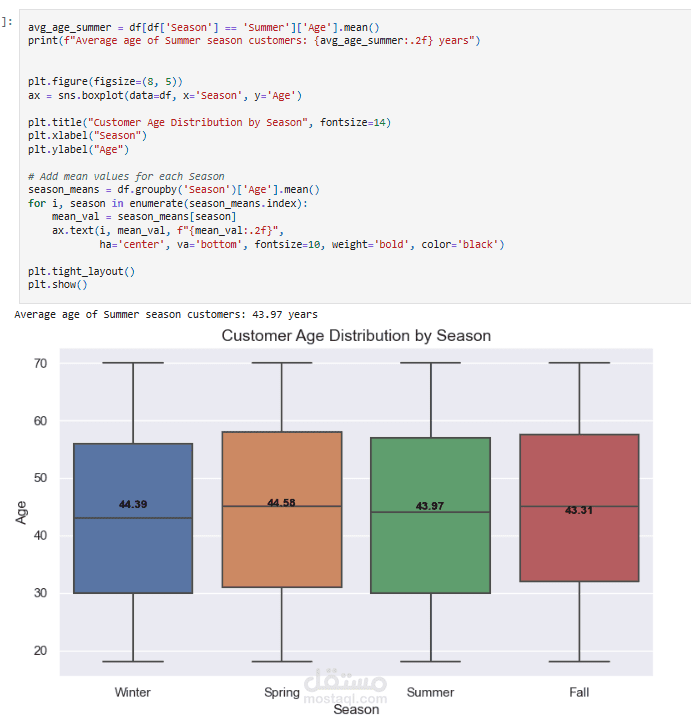
Descriptive Statistics: حساب الإحصاءات الأساسية مثل متوسط العمر، أكثر المنتجات شراءً، إجمالي المبيعات حسب الفئات.
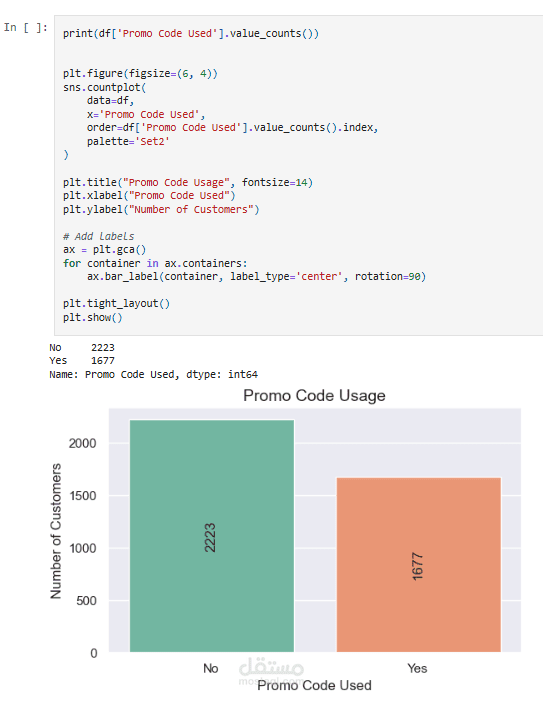
Exploratory Analysis: استخدام المخططات (bar plots, pie charts) و word cloud لاكتشاف الأنماط في العمر، النوع، الموقع، وفئات المنتجات.
In-depth Analysis: الإجابة عن أسئلة محددة مثل:
متوسط التقييمات بين الذكور والإناث.
أكثر طرق الدفع شيوعًا.
متوسط قيمة الشراء للعملاء المشتركين مقابل غير المشتركين.
Correlation Analysis: حساب معاملات الارتباط (مثل Pearson) بين العمر وعدد المشتريات السابقة.
السمات المدروسة:
الخصائص الديموغرافية: العمر، الجنس.
أنماط الشراء: المبلغ، الأصناف، الفئات، المواسم.
سلوك المستهلك: طرق الدفع، معدل الشراء، الاشتراكات، الأكواد الترويجية.
مؤشرات الجودة: تقييمات العملاء، الخصومات، نوع الشحن.
الأدوات والتقنيات:
Python (Pandas, NumPy, Matplotlib, Seaborn, WordCloud, Missingno)
Data Cleaning, Visualization, Correlation Analysis
القيمة المضافة:
هذا المشروع أظهر كيف يمكن للبيانات أن تساعد في:
فهم تفضيلات العملاء.
تحسين المنتجات والعروض التسويقية.
تطوير استراتيجيات مبيعات قائمة على البيانات.