تحليل البيانات | Data Analysis | استخراج البيانات من المواقع | ETL | Dashboard
تفاصيل العمل
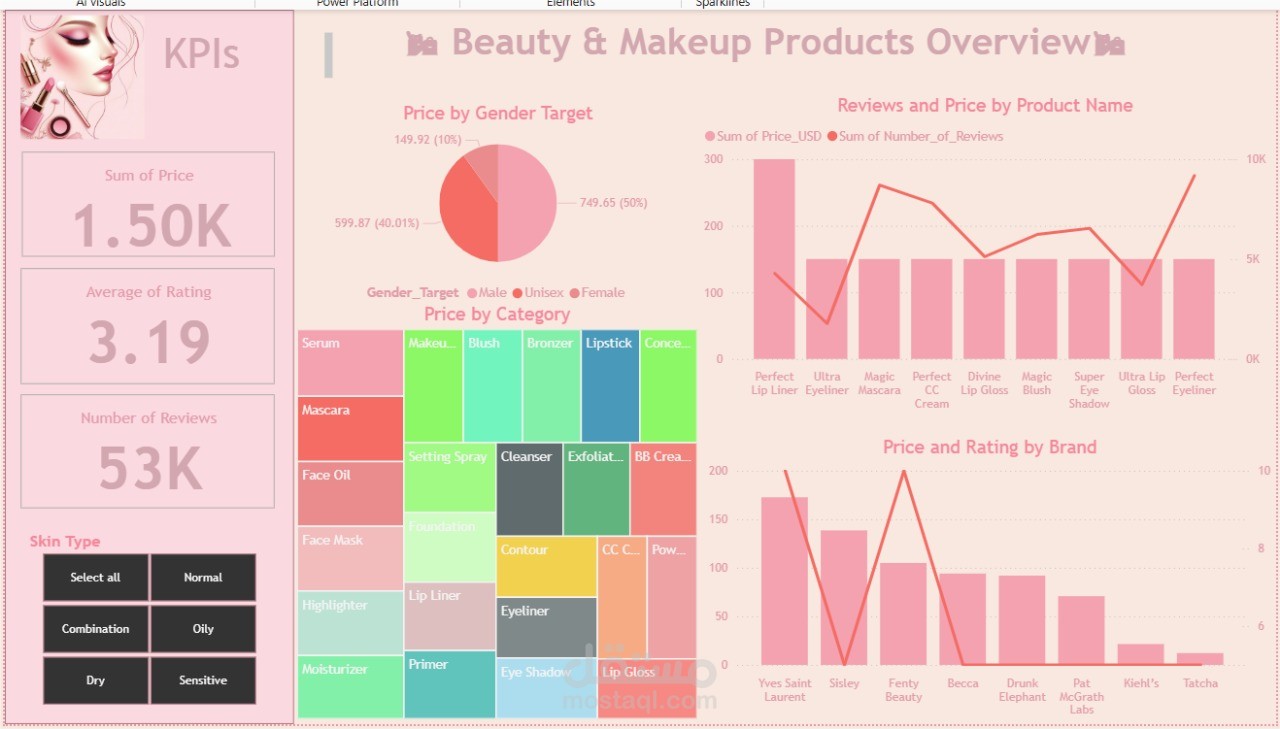
هذا المشروع يركز على بناء مسار بيانات (Data Pipeline) متكامل من نوع End-to-End ETL بهدف توفير رؤى عميقة حول سوق المكياج ومستحضرات التجميل. لقد قمت بتحويل البيانات الأولية إلى أداة تحليل قوية للمساعدة في اتخاذ القرارات التسويقية والشرائية.
مصادر البيانات (Data Sources):
استخلاص الويب (Web Scraping) من منصة Amazon: لجمع البيانات عن منتجات المكياج
مجموعات بيانات تكميلية (Kaggle Dataset): لإثراء البيانات بالميتا داتا (Metadata) المتخصصة مثل مكونات المنتج، الفئات اللونية (Shades)، وخصائص المنتج.
تم تطبيق مراحل Pre-processing متقدمة لتصحيح الأخطاء، ومعالجة القيم المفقودة (Missing Values)، وضمان جودة البيانات (Data Quality) قبل تحميلها (Load) في قاعدة بيانات علائقية (Relational Database) جاهزة للتحليل.
️ الأجزاء التقنية (What I Developed):
تصميم وتنفيذ Web Scraper مخصص وفعّال لبيانات التجارة الإلكترونية.
تطوير Python Scripts لعمليات التحويل المعقدة (Transformation) وإثراء البيانات.
إنشاء Relational Database Schema مهيكل لضمان تخزين البيانات بكفاءة وقابلية للاستعلام.
استخدام SQL Queries و تحليلات Python المتقدمة لاستخراج Actionable Insights.
بناء طبقة Visualization (Dashboard) ديناميكية تعرض مؤشرات الأداء الرئيسية (KPIs) الخاصة بالقطاع بوضوح تام.
أبرز الرؤى والنتائج (Key Findings & Insights):
الأداء والتصنيف: تحديد الـ Bestsellers (الأكثر مبيعاً) والماركات المسيطرة على فئات معينة (مثل أحمر الشفاه أو كريم الأساس)، وتصنيف المنتجات حسب أفضل تقييم (Top Rated) بناءً على الخصائص.
تحليل المشاعر (Sentiment Analysis): استخلاص توجهات العملاء من المراجعات لتحديد نقاط القوة والضعف (مثلاً: الثناء على التغطية أو الشكوى من الثبات)، مما يكشف عن الاحتياجات السوقية غير الملباة.
ديناميكيات التسعير: تحليل مقارن بين الأسعار (Pricing) ومتوسط التقييمات عبر مختلف شرائح المنتجات (الفاخرة مقابل الاقتصادية)، لتحديد القيمة المدركة للمنتج.