Web Scraping | Data Engineering | Dashboard | Data Analysis | Data Pipeline | بناء مسار بيانات ETL وتصميم لوحة تحكم تفاعلية Power BI
تفاصيل العمل
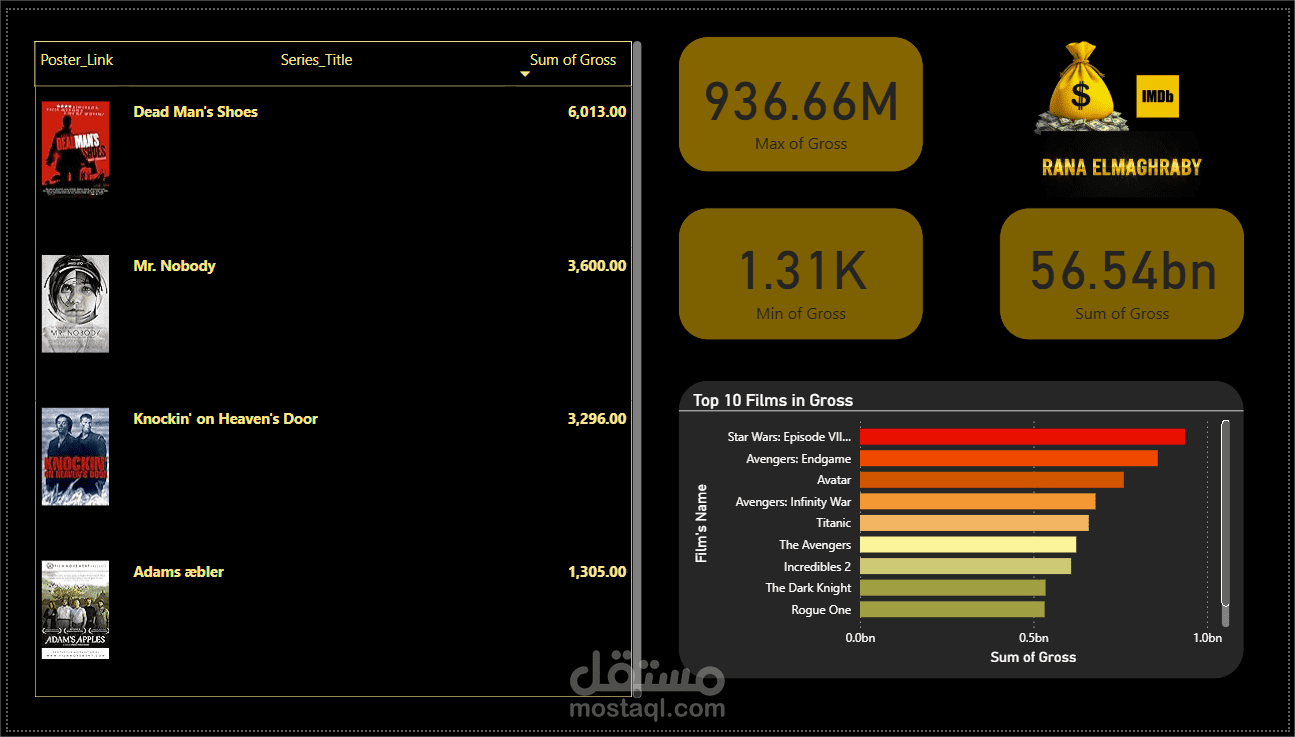
هذا المشروع يمثل تطبيقاً شاملاً لمسار بيانات (Data Pipeline) من نوع End-to-End ETL، ويتضمن تحليلاً استكشافياً لبيانات الأفلام والمشاهير مجمّعة من مصادر متعددة.
مصادر البيانات:
Web Scraping من موقع IMDb: تم استخلاص بيانات المشاهير، الأدوار، الأعمال، السنوات/المواسم، والأفلام الأعلى تقييماً وشهرة.
Supplementary Dataset من Kaggle: لتزويد البيانات بصور Posters URLs وميتا داتا إضافية للأفلام.
تم تنظيف البيانات وإجراء Pre-processing لتصحيح الأنواع (Types) ومعالجة Missing Values، ثم تحميلها (Load) إلى قاعدة بيانات لغرض التحليل وإعداد التقارير.
️ What I Built (ما قمت ببنائه):
Web Scraper فعّال لاستخراج معلومات الأفلام والمشاهير من IMDb.
Python Scripts لتنظيف (Clean)، تحويل (Transform)، وإثراء (Enrich) البيانات.
تصميم Relational Database Schema لتخزين الجداول المعالجة.
إجراء تحليلات Python و SQL Queries لاستخلاص الرؤى القابلة للتطبيق (Actionable Insights).
طبقة Visualization (Dashboard) تعرض أهم النتائج بوضوح وسهولة استخدام.
Key Findings & Insights (النتائج والرؤى الرئيسية):
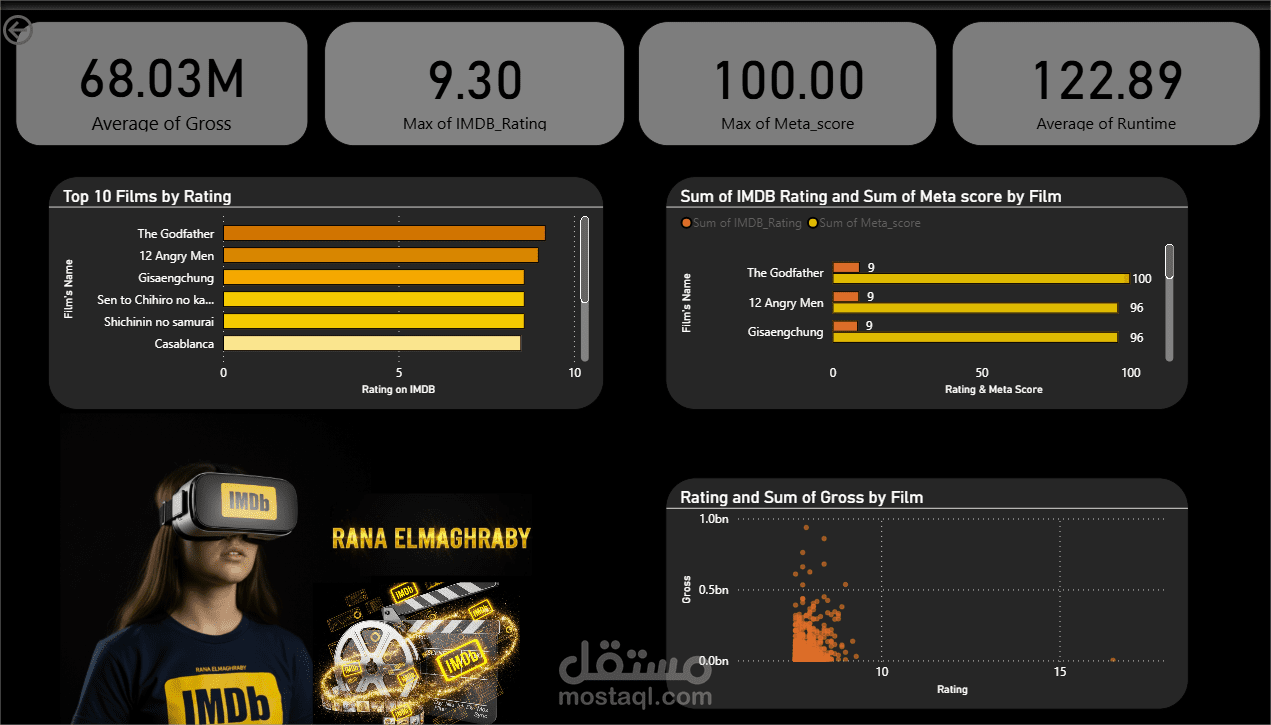
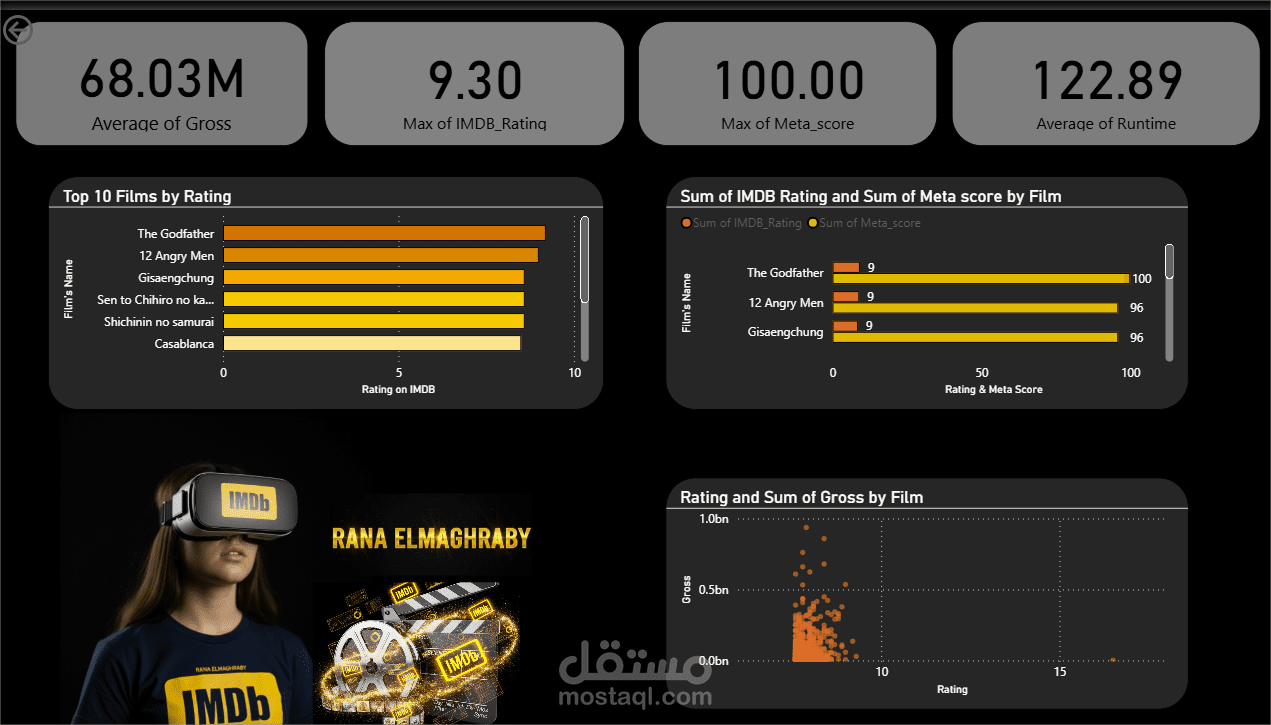
Top Films & Series: تحديد الأفلام الأعلى تقييماً من قبل النقاد (Meta score) والجمهور (IMDb rating)، وتقديم قائمة مصغرة بالعناوين التي حققت أداءً قوياً في كلتا الفئتين.
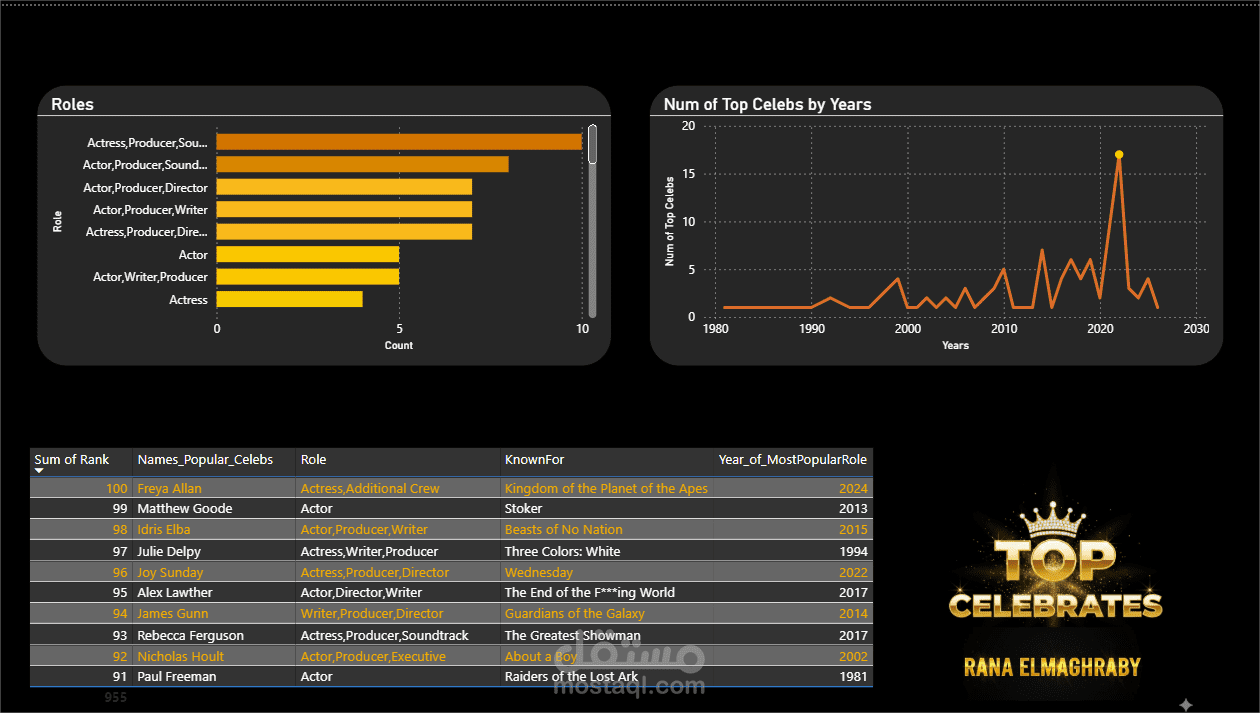
Celebrity & Crew Trends: تحليل النشاط في سنة 2022 (مثال)، وتحديد المهن الأكثر شيوعاً في قوائم المشاهير مثل: Writer، Sound، و Actor.
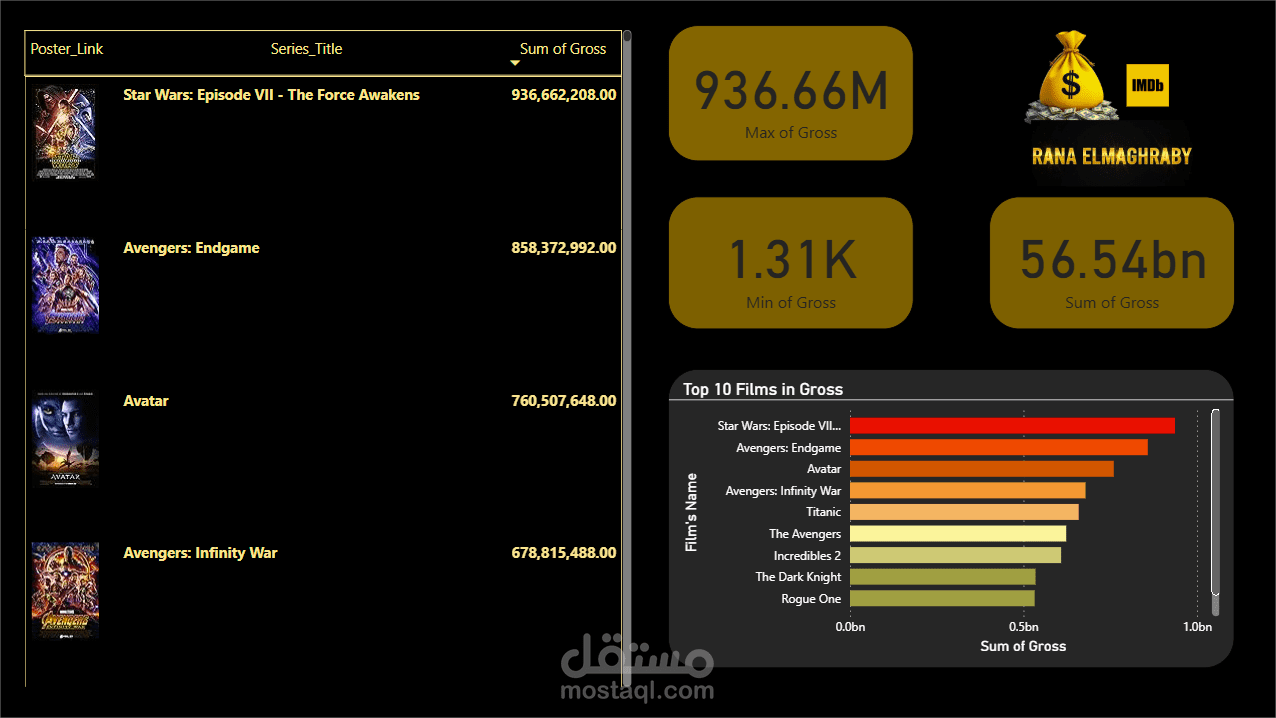
Financial vs. Critical Success: أوضحت التحليلات أن الأفلام التي تحقق أعلى إيرادات (Gross) ليست بالضرورة هي الأفلام ذات التقييم النقدي الأعلى، وللـ Genre (النوع الفني) دور مهم في كل من الإيرادات والتقييمات.