Fake_News_Detection
تفاصيل العمل
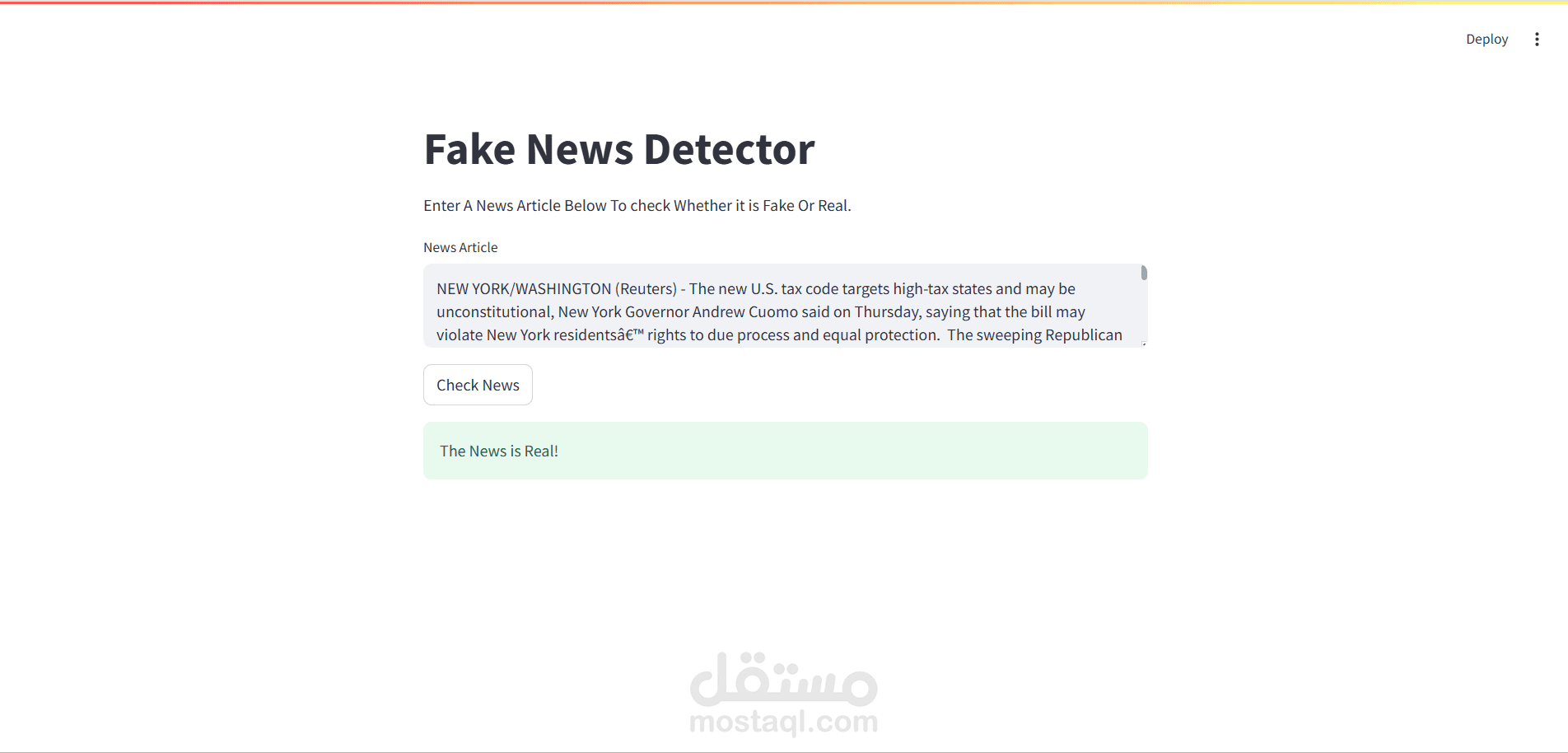
Fake News Detection Project
The Fake News Detection Project focuses on building a machine learning model that can classify whether a news article is real or fake, helping to combat misinformation in digital media.
Objective
To apply Natural Language Processing (NLP) and machine learning techniques to text data.
To automatically detect misleading or false news content.
Tools & Skills Used
Python: for data analysis and model building.
Libraries: Pandas, NumPy, Scikit-learn, NLTK/Spacy, TensorFlow or Keras (if deep learning was used).
Data Cleaning: text preprocessing (tokenization, stop-word removal, stemming/lemmatization).
Feature Engineering: TF-IDF, Bag of Words, or word embeddings (Word2Vec, GloVe).
Modeling: Logistic Regression, Naive Bayes, Random Forest, or CNN/LSTM for advanced NLP.
Evaluation Metrics: Accuracy, Precision, Recall, F1-score, Confusion Matrix.
Key Insights
Preprocessing significantly improves accuracy by reducing noise in the text.
Models like Logistic Regression and Naive Bayes work well on TF-IDF features for fake news detection.
Deep learning models (LSTM/CNN) can capture more context and improve results with large datasets.
Outcome
Achieved high classification accuracy in distinguishing between real and fake news.
Built a reproducible workflow that can be applied to new datasets.
Demonstrated skills in NLP, text classification, and machine learning.
Potential real-world impact: supporting fact-checking organizations and improving media literacy.