Heart Disease Prediction
تفاصيل العمل
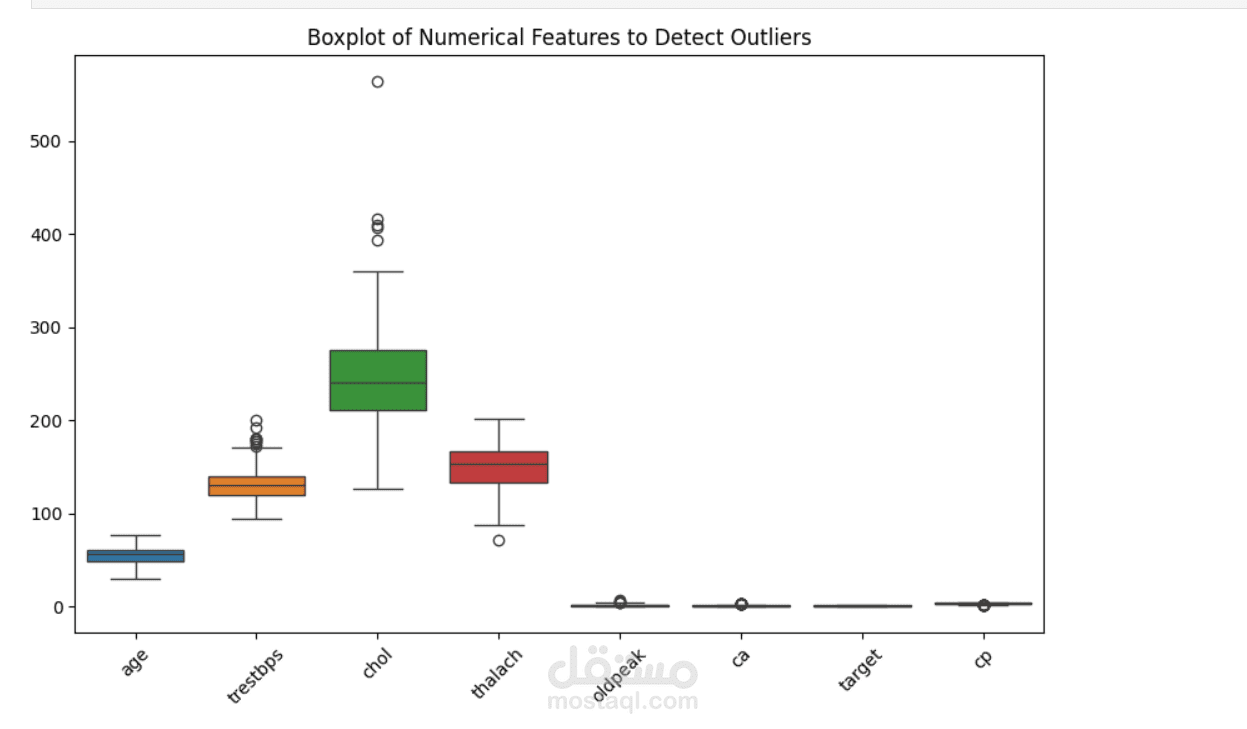
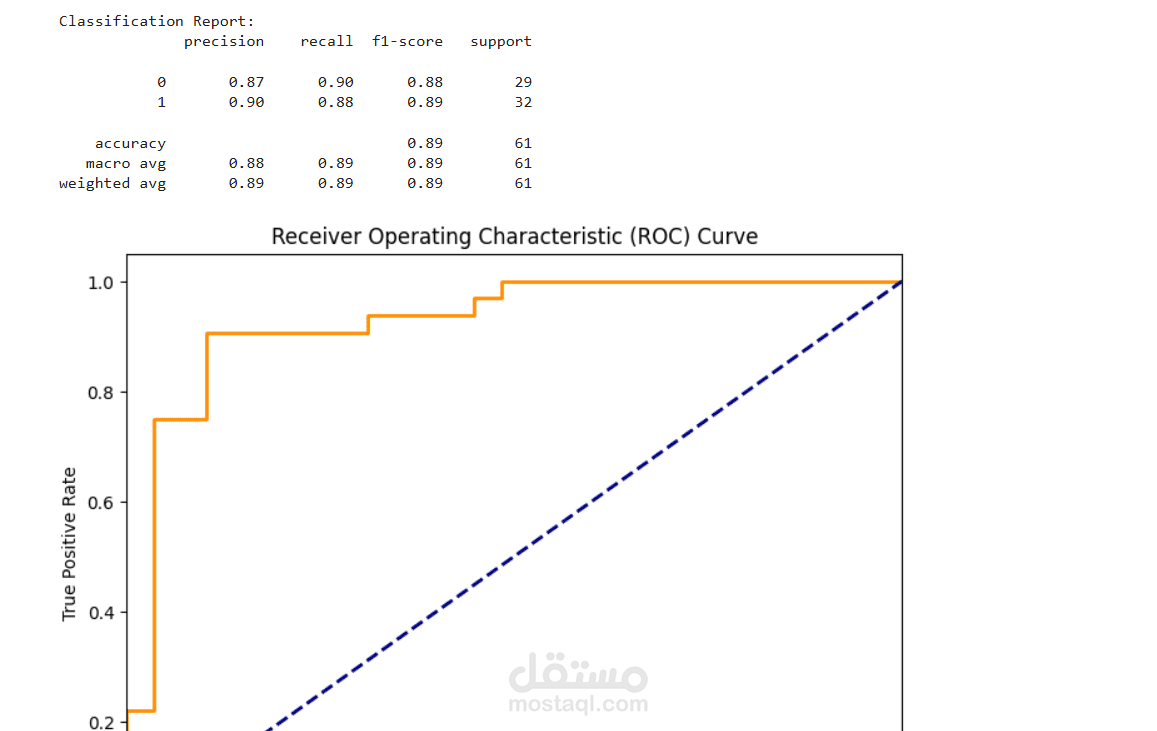
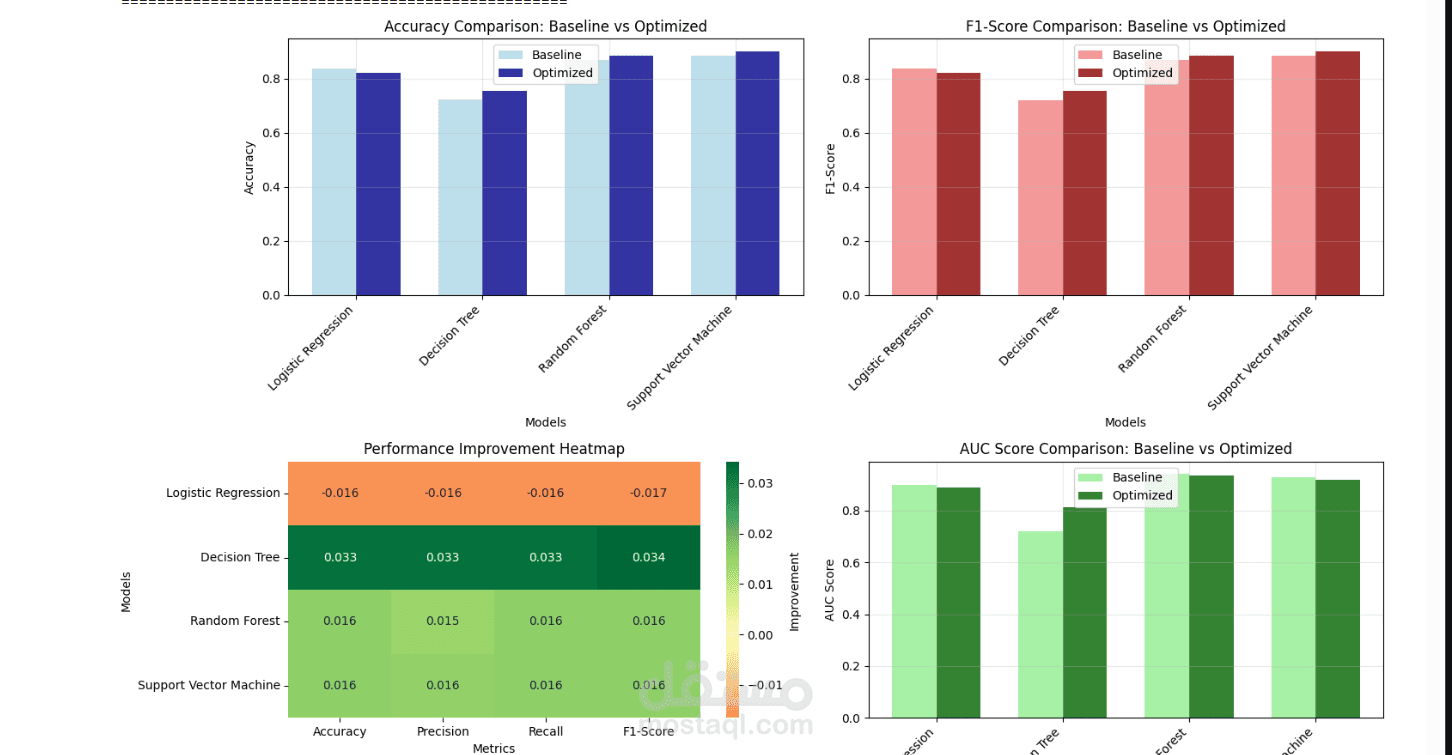
Data preprocessing & cleaning – making the dataset ready for analysis
Dimensionality reduction with PCA – simplifying data while keeping critical information
Feature selection – identifying the most important predictors for heart disease
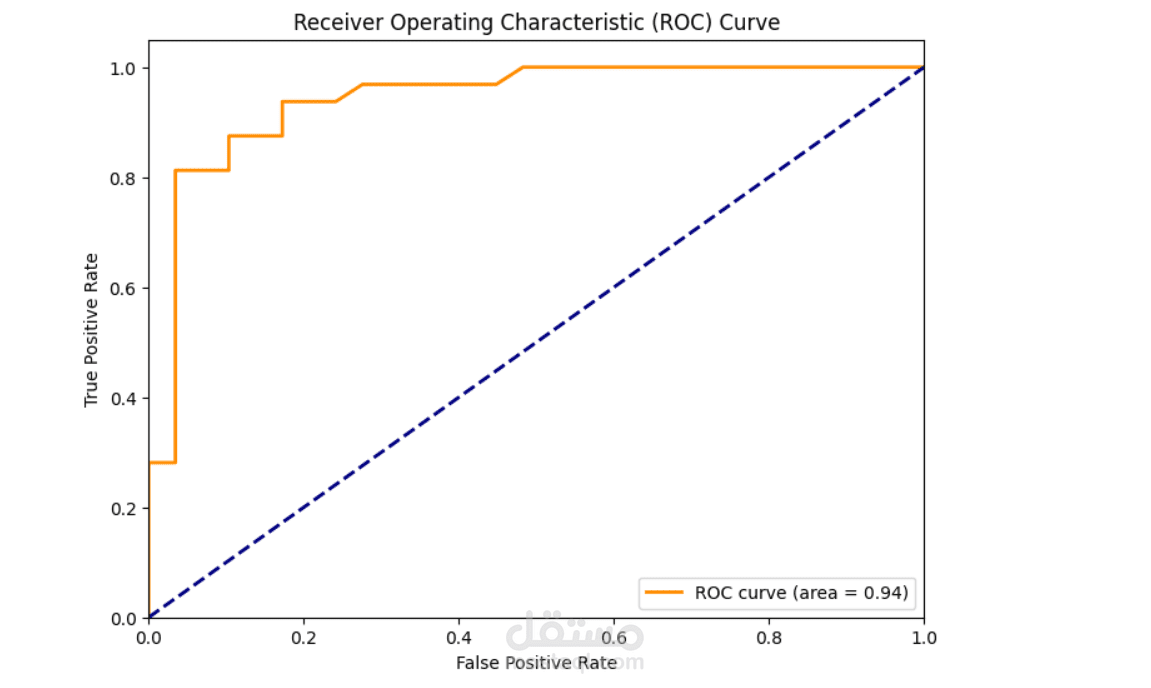
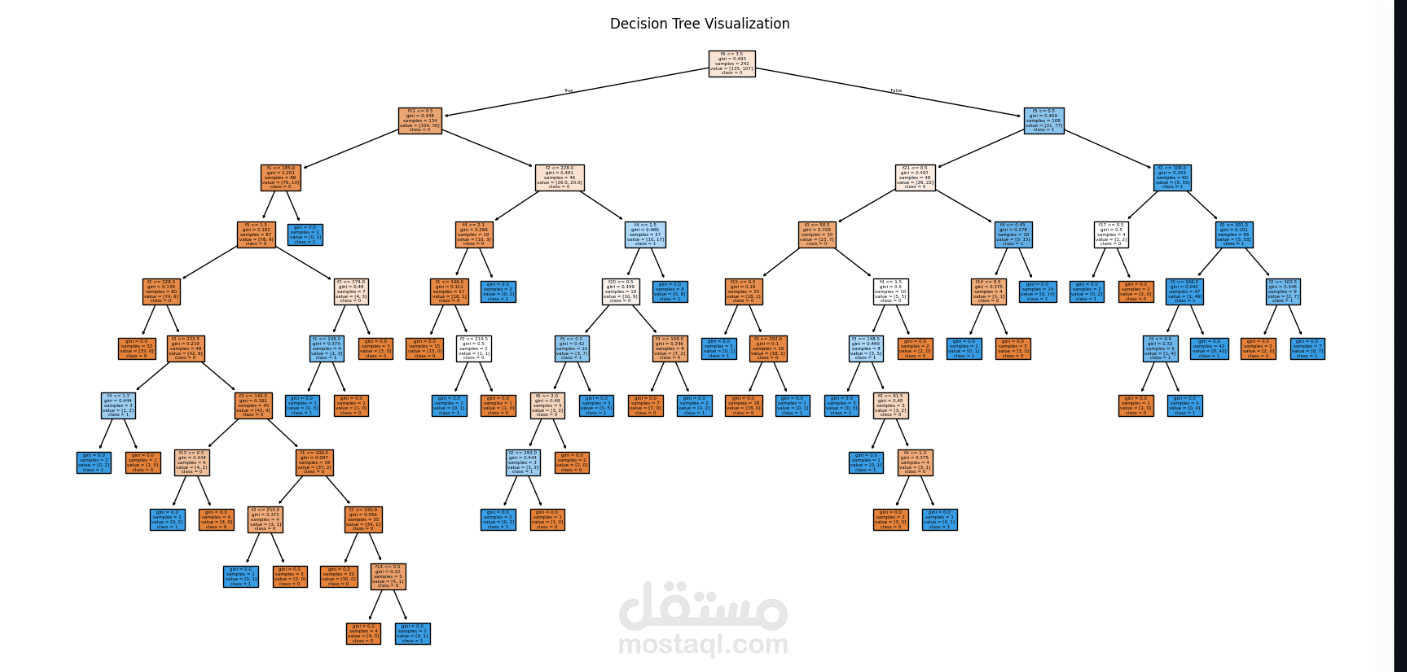
Supervised learning models – building and testing classification models
Unsupervised learning techniques – exploring patterns and hidden structures in the data
Hyperparameter tuning – fine-tuning models for better accuracy
Interactive UI with Streamlit – creating a user-friendly interface to interact with predictions
Deployment – taking the model from local development to a live environment