Data Breast Cancer
تفاصيل العمل
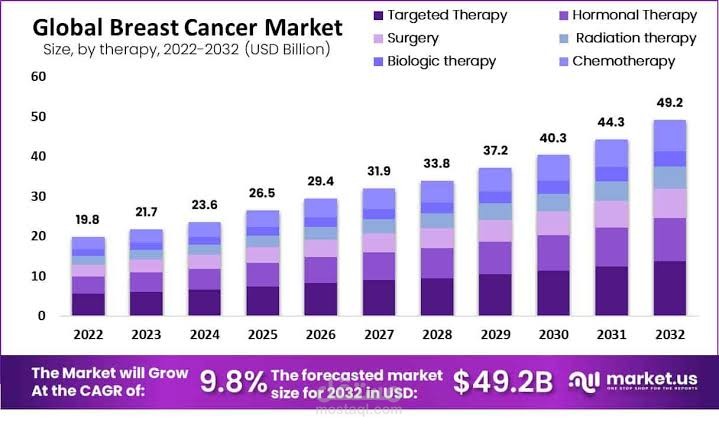
مشروع تحليل بيانات سرطان الثدي يهدف إلى بناء نموذج تنبؤي ذكي يساعد في التمييز بين الأورام الحميدة والخبيثة اعتمادًا على بيانات طبية فعلية.
الخطوات التي قمت بها:
1. جمع البيانات وتنظيفها (Data Cleaning):
معالجة القيم المفقودة.
إزالة التكرار والتأكد من دقة البيانات.
تحويل البيانات لتكون جاهزة للتحليل والنمذجة.
2. التحليل الاستكشافي للبيانات (EDA):
دراسة توزيع المتغيرات.
اكتشاف العلاقات بين الخصائص (features).
استخدام الرسوم البيانية لفهم الأنماط.
3. معالجة البيانات (Preprocessing):
تطبيق التطبيع (Normalization/Standardization) على الخصائص.
ترميز القيم الفئوية (Label Encoding).
تقسيم البيانات إلى بيانات تدريب واختبار.
4. بناء النماذج (Model Building):
تجربة عدة خوارزميات مثل: Logistic Regression, Random Forest, XGBoost.
ضبط المعاملات (Hyperparameter Tuning) للحصول على أفضل أداء.
5. تقييم النموذج (Evaluation):
استخدام مقاييس مثل: الدقة (Accuracy)، الاستدعاء (Recall)، F1-score.
حصل النموذج الأفضل على دقة 90%+ في التنبؤ.
6. النتائج والاستفادة:
المشروع أظهر كيف يمكن استخدام تقنيات الذكاء الاصطناعي والتعلم الآلي لمساعدة الأطباء في التشخيص المبكر لسرطان الثدي.
ساعد في تحويل البيانات الطبية المعقدة إلى رؤية واضحة وقرارات دقيقة.