كشف المنتجات المزيفة – Counterfeit Products Detection
تفاصيل العمل






في المشروع ده استخدمت Python مع مكتبات:
pandas, numpy لمعالجة البيانات وتجهيزها للنماذج.
scikit-learn لتطبيق خوارزميات التصنيف.
matplotlib, seaborn لعرض النتائج بشكل بصري.
️ قمت بـ:
ترميز البيانات (Encoding) وتحويل القيم النصية لأرقام.
توحيد القيم (Scaling) لتجهيزها للنماذج.
تطبيق وتجربة أكثر من خوارزمية تصنيف:
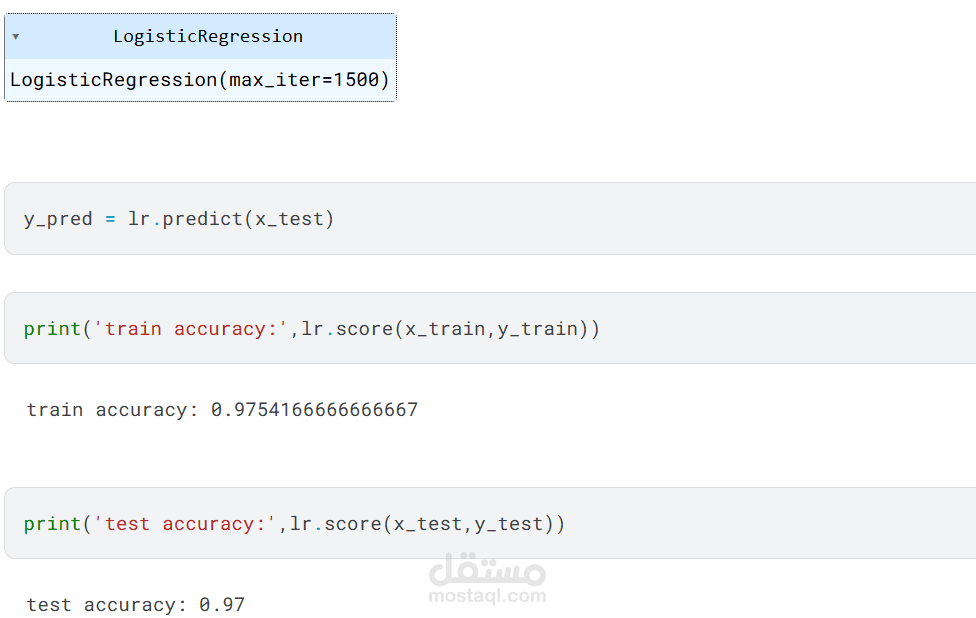
Logistic Regression
Decision Tree
KNN
SVM
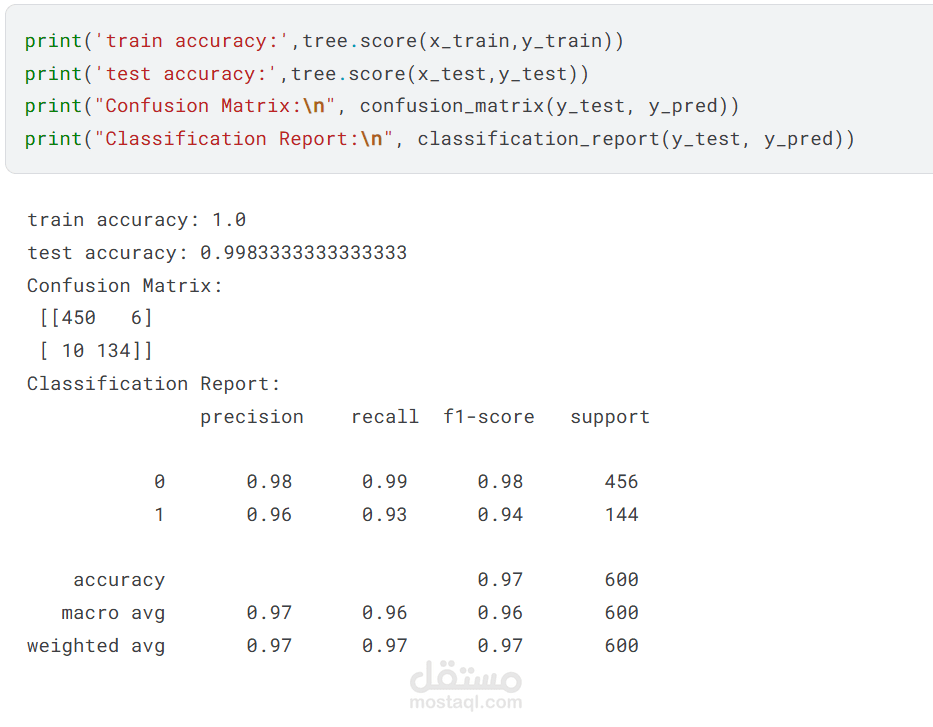
ثم عملت تقييم ومقارنة بين النماذج باستخدام:
دقة التصنيف (Accuracy)
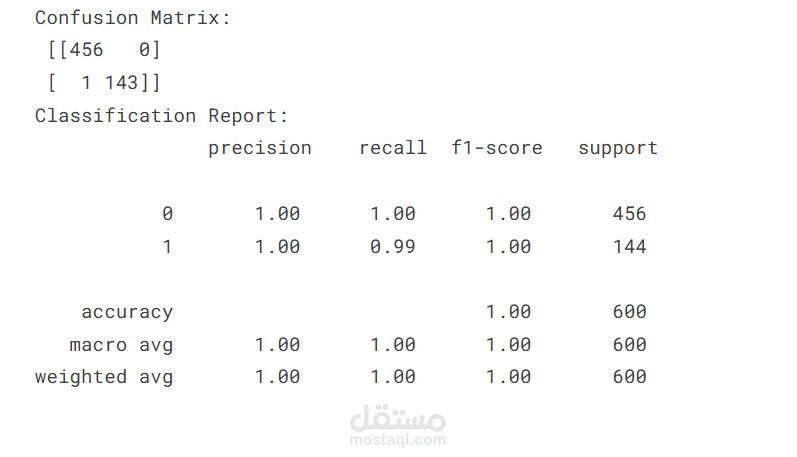
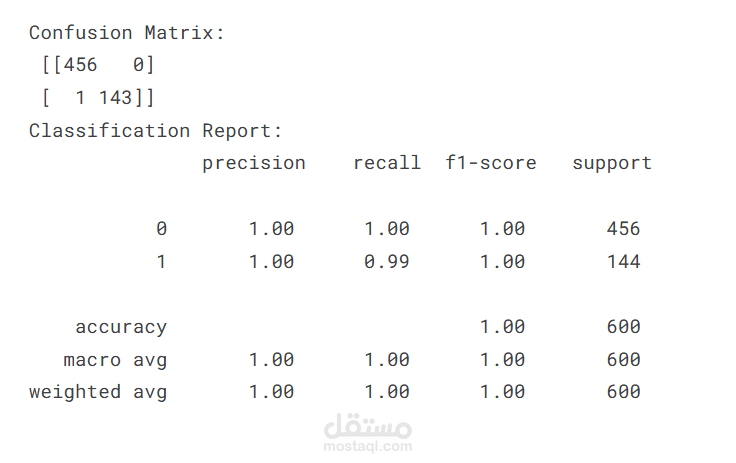
Confusion Matrix
Classification Report
أفضل نموذج وصل لدقة حوالي 99% في التفريق بين المنتج الأصلي والمقلد.
النتيجة: المشروع بيوضح قدرتي على تجهيز البيانات – تجربة خوارزميات مختلفة – وتقييم أدائها لاختيار الأفضل.