Arabic Sentiment using Bert and classification
تفاصيل العمل
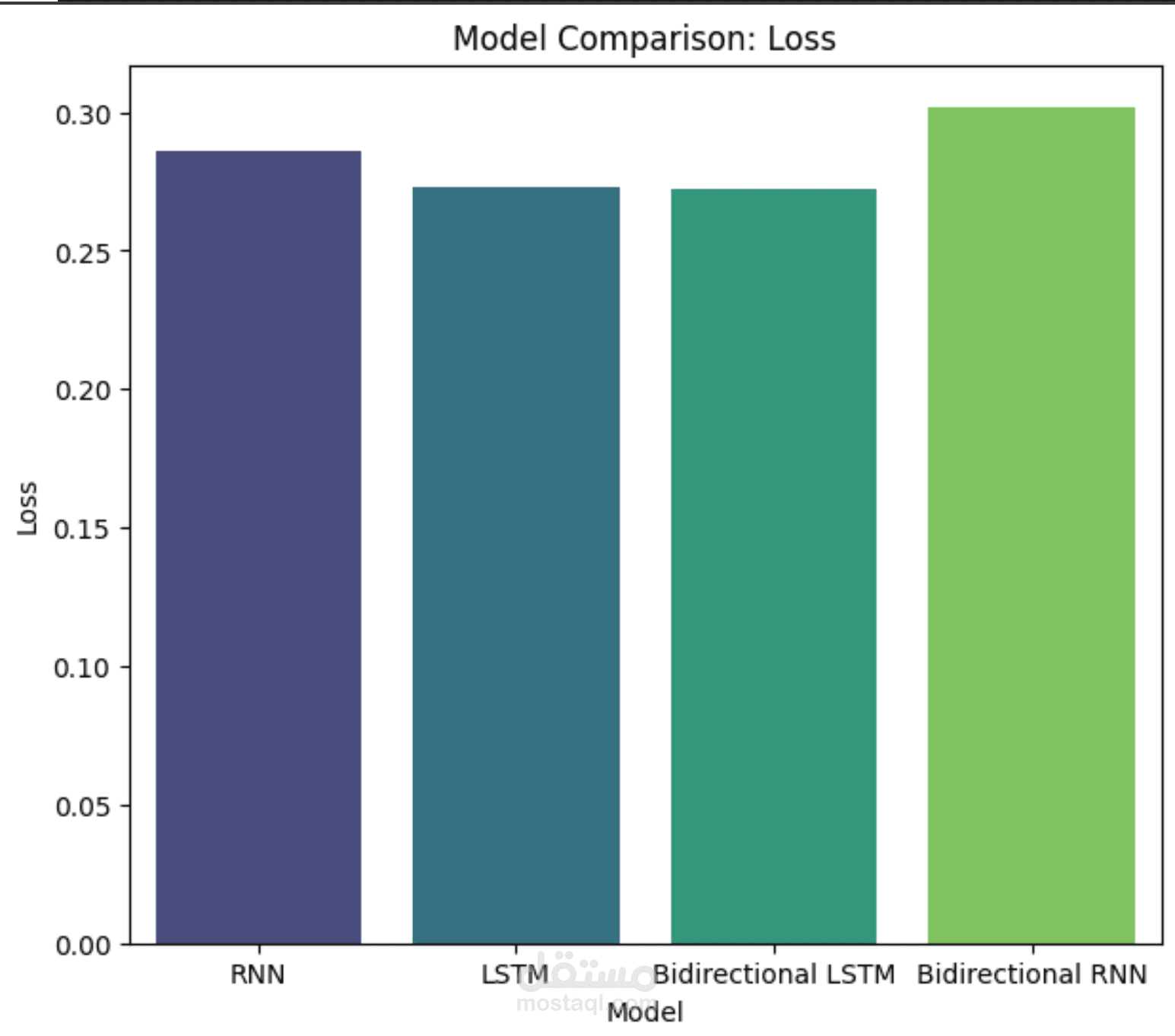
"قمت بتطوير نموذج لمعالجة اللغة الطبيعية يختص بـ تحليل المشاعر في النصوص العربية (إيجابي – سلبي).
بدأت بـ تنظيف ومعالجة البيانات النصية (إزالة التكرارات، التشكيل، الرموز…)، ثم قمت بتوليد تمثيلات نصية (Embeddings) باستخدام نموذج BERT المخصص للعربية.
تم توصيل المخرجات بنماذج تصنيف مثل Logistic Regression, LSTM, BiLSTM لمقارنة الأداء.
تم تقييم النماذج باستخدام Accuracy, Confusion Matrix, F1-score، وحقق نموذج BERT + BiLSTM أفضل النتائج.
المشروع يُظهر قدرة النماذج العميقة على فهم اللغة العربية وتحديد المشاعر بدقة عالية."