Developing a Generative AI Model for Image Captioning using Visual Attention
تفاصيل العمل
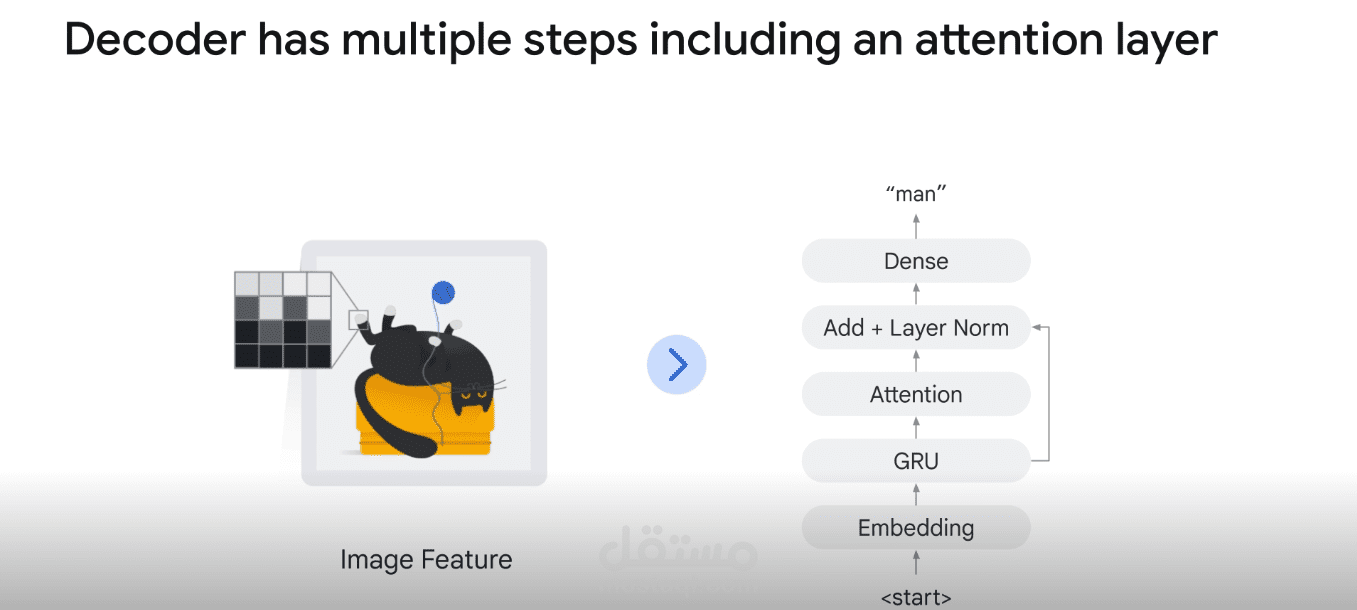
This project focuses on developing a Generative AI model capable of automatically generating meaningful and context-aware captions for images. The system leverages deep learning techniques, combining Convolutional Neural Networks (CNNs) for image feature extraction and Recurrent Neural Networks (RNNs) or Transformers for natural language generation.
To enhance the accuracy and fluency of captions, the project integrates a Visual Attention Mechanism, allowing the model to focus on the most relevant regions of an image when forming each word in the caption. This mimics how humans selectively pay attention to specific details in a scene before describing it.
The workflow includes:
Image Feature Extraction – using pretrained vision models (e.g., ResNet, VGG, or Vision Transformers).
Sequence Modeling – generating descriptive text via LSTM/GRU or Transformer-based decoders.
Visual Attention – dynamically highlighting key image regions during caption generation.
Training & Evaluation – leveraging datasets such as Flickr8k, MS-COCO, or Flickr30k, with evaluation metrics like BLEU, METEOR, and CIDEr.
The final outcome is an intelligent captioning system that canThis project focuses on developing a Generative AI model capable of automatically generating meaningful and context-aware captions for images. The system leverages deep learning techniques, combining Convolutional Neural Networks (CNNs) for image feature extraction and Recurrent Neural Networks (RNNs) or Transformers for natural language generation.
To enhance the accuracy and fluency of captions, the project integrates a Visual Attention Mechanism, allowing the model to focus on the most relevant regions of an image when forming each word in the caption. This mimics how humans selectively pay attention to specific details in a scene before describing it.
The workflow includes:
Image Feature Extraction – using pretrained vision models (e.g., ResNet, VGG, or Vision Transformers).
Sequence Modeling – generating descriptive text via LSTM/GRU or Transformer-based decoders.
Visual Attention – dynamically highlighting key image regions during caption generation.
Training & Evaluation – leveraging datasets such as Flickr8k, MS-COCO, or Flickr30k, with evaluation metrics like BLEU, METEOR, and CIDEr.
The final outcome is an intelligent captioning system that can interpret visual content and express it in natural language, making it applicable in areas such as accessibility for the visually impaired, image retrieval, digital asset management, and smart assistants. interpret visual content and express it in natural language, making it applicable in areas such as accessibility for the visually impaired, image retrieval, digital asset management, and smart assistants.