الفيوم
تفاصيل العمل
نوع العمل
تصنيف البيانات باستخدام خوارزمية SVM (Support Vector Machine).
يعني الهدف هو تدريب نموذج قادر يميز بين فئتين (binary classification) بناءً على البيانات المدخلة.
مميزات العمل
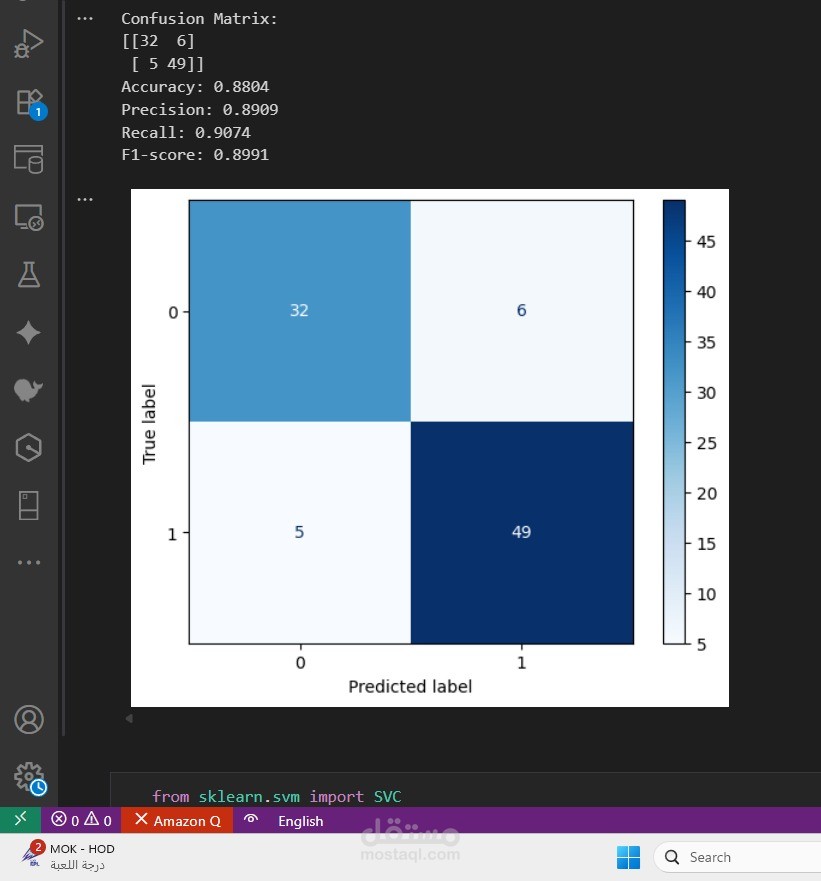
دقة عالية: النموذج حقق Accuracy ≈ 88% و Recall ≈ 90%، وده يدل إنه بيقدر يتعرف كويس على الأنماط.
توازن في الأداء: الـ Precision والـ Recall متقاربين جدًا، والـ F1-score ≈ 0.89، يعني النموذج متوازن بين تقليل الأخطاء الإيجابية والسلبية.
وضوح التقييم: استخدام Confusion Matrix بيوضح بالضبط عدد الحالات اللي اتصنفت صح وغلط.
قابلية التطبيق: SVM بيشتغل بكفاءة مع البيانات الصغيرة والمتوسطة ومناسب في بداية المشاريع.
طرق التنفيذ
تحضير البيانات: تنظيف البيانات وتقسيمها إلى بيانات تدريب واختبار.
اختيار الخوارزمية: استدعاء مكتبة sklearn.svm واستخدام SVC لبناء النموذج.
تدريب النموذج: إدخال بيانات التدريب للنموذج ليتعلم الأنماط.
التنبؤ: استخدام بيانات الاختبار للحصول على التوقعات.
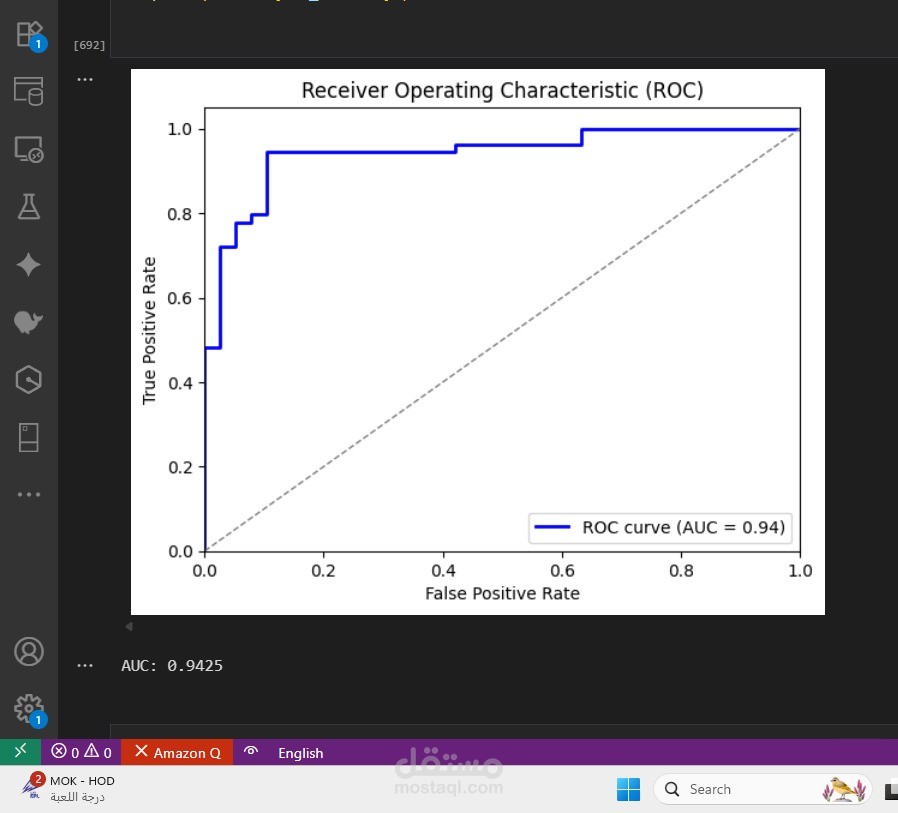
التقييم: إنشاء Confusion Matrix وحساب المؤشرات (Accuracy, Precision, Recall, F1).