مجموعة بيانات KDD – نماذج التعزيز (Boosting Models)
تفاصيل العمل
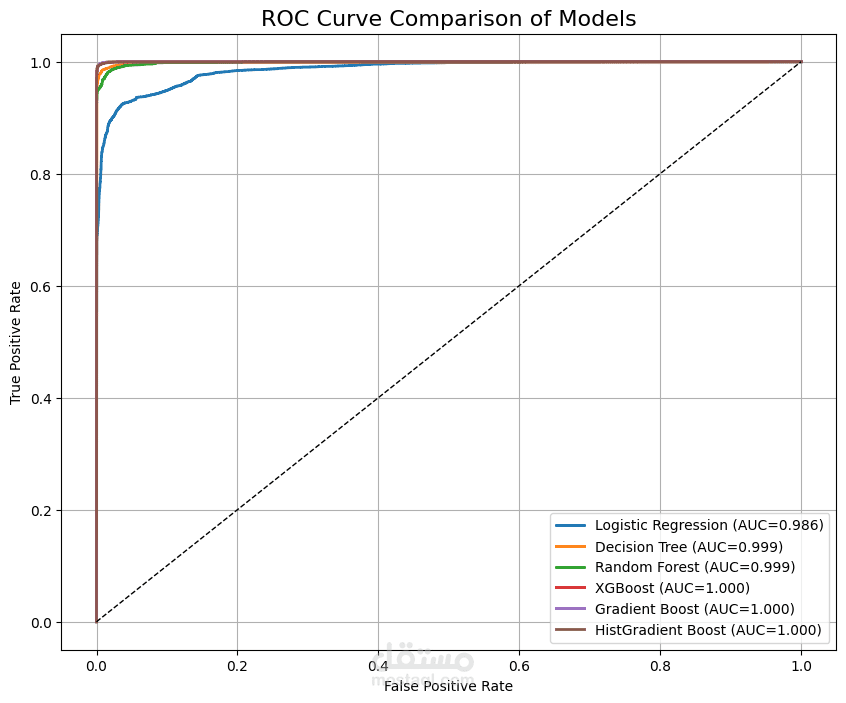
تم تطوير عدة نماذج تجميعية (XGBoost، Gradient Boosting، وHistogram Gradient Boosting) لتصنيف الأنماط داخل مجموعة بيانات KDD. ركّز المشروع على معالجة مشكلة عدم توازن البيانات، وهندسة الخصائص (Feature Engineering)، وتحسين معاملات النماذج (Hyperparameter Optimization) لزيادة الأداء. حققت جميع النماذج دقة تقارب 99.5%، مما يبرز قوة تقنيات التعزيز في مهام التصنيف واسعة النطاق.