https://github.com/jasserHasni/Automated-AWS-Data-Engineering-Pipeline-with-Flask-Integration.git
تفاصيل العمل
اسم المشروع:
Data Engineering Pipeline with AWS & Flask
رابط المشروع:
GitHub Repository
تاريخ الإنجاز:
2024
وصف العمل:
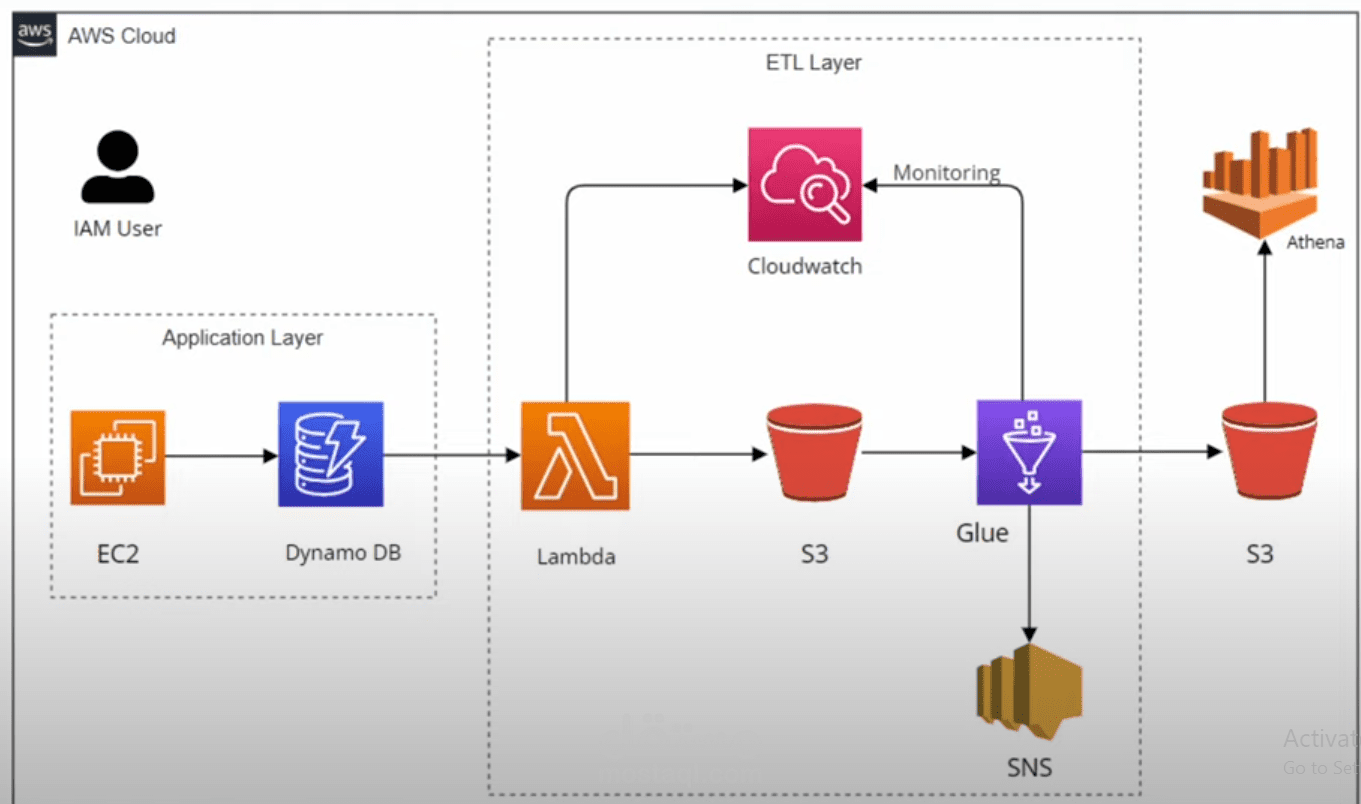
مشروع لبناء Data Engineering Pipeline متكامل باستخدام AWS، يتم تشغيله عبر تطبيق Flask مستضاف على EC2. التطبيق يحتوي على نموذج لجمع بيانات المستخدمين ويبدأ سلسلة من خطوات معالجة البيانات ضمن خدمات AWS المختلفة.
المهام المنجزة:
إنشاء IAM User مع صلاحيات كاملة لخدمات S3, Athena, CloudWatch, Lambda, DynamoDB, Glue, Glue Crawler.
استضافة تطبيق Flask على EC2 باستخدام NGINX & Gunicorn، مع نموذج لجمع بيانات المستخدمين.
إنشاء قاعدة بيانات DynamoDB مع جدولين لتخزين البيانات المجمعة من النموذج.
إنشاء DynamoDB Stream Endpoint لمراقبة التحديثات.
تفعيل AWS Lambda لكل تحديث في الجداول، واستخدام Apache Spark لتحويل البيانات وتحميلها إلى S3 Staging Bucket.
إنشاء Lambda Layers باستخدام pandas وboto3 لدعم سكربتات Apache.
مراقبة البيانات والوظائف باستخدام CloudWatch Logs.
استخدام AWS Glue لتحويل ودمج البيانات وحفظها في S3 Data Warehouse Bucket.
استخدام AWS Glue Crawler لاستخراج Schema وحفظه في قاعدة بيانات Crawler Database.
تحليل البيانات باستخدام Amazon Athena لتشغيل استعلامات SQL واستخراج رؤى دقيقة.
️ المهارات والأدوات:
Programming & Data Processing: Python, Pandas, Boto3, Spark
Web App: Flask, NGINX, Gunicorn
AWS Services: EC2, S3, DynamoDB, Lambda, Glue, Glue Crawler, Athena, CloudWatch
Data Engineering: ETL, Data Pipeline, Data Transformation, SQL