تحليل بيانات باستخدام بايثون
تفاصيل العمل

خطوات تنفيذ المشروع:
1_الحصول على البيانات:
- قمت بتحميل الـ Dataset من موقع Kaggle.
2_قراءة البيانات:
- استخدمت مكتبة pandas لقراءة ملف CSV وتحويله إلى DataFrame لسهولة التعامل مع البيانات
3_استكشاف البيانات (Exploratory Data Analysis – EDA):
- عرض أول وأسطر وأعمدة من البيانات (df.head(), df.info(), df.describe()).
- تحديد الهدف الرئيسي من التحليل (مثلاً: تحليل المبيعات أو النجاة في Titanic) علشان أوصل لإجابات واضحة من الداتا.
4_تنظيف البيانات (Data Cleaning):
- تعديل الأعمدة لو في أي مشكلة (زي تحويل الأعمدة لتواريخ باستخدام pd.to_datetime).
- تغيير أنواع البيانات غير الصحيحة (Strings → Numeric أو Date).
5_ معالجة القيم المفقودة (Handling Null Values):
- فحص القيم المفقودة باستخدام: df.isnull().sum()
6_التعامل مع القيم المكررة (Handling Duplicates):
- التحقق من وجود صفوف مكررة: df.duplicated().sum()
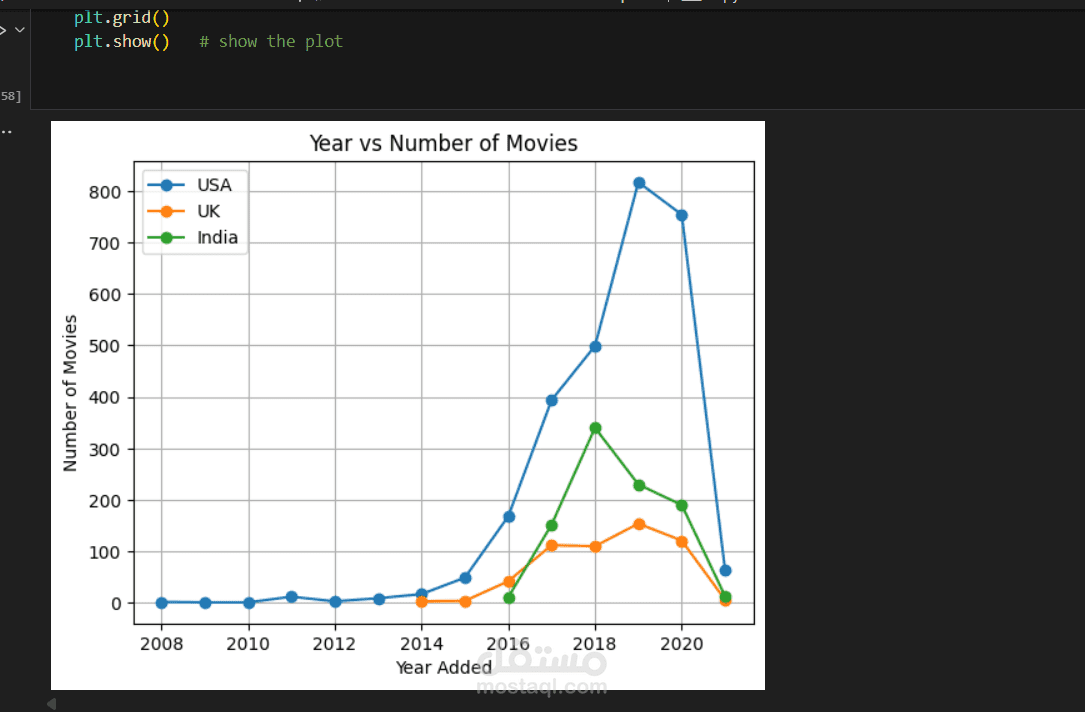
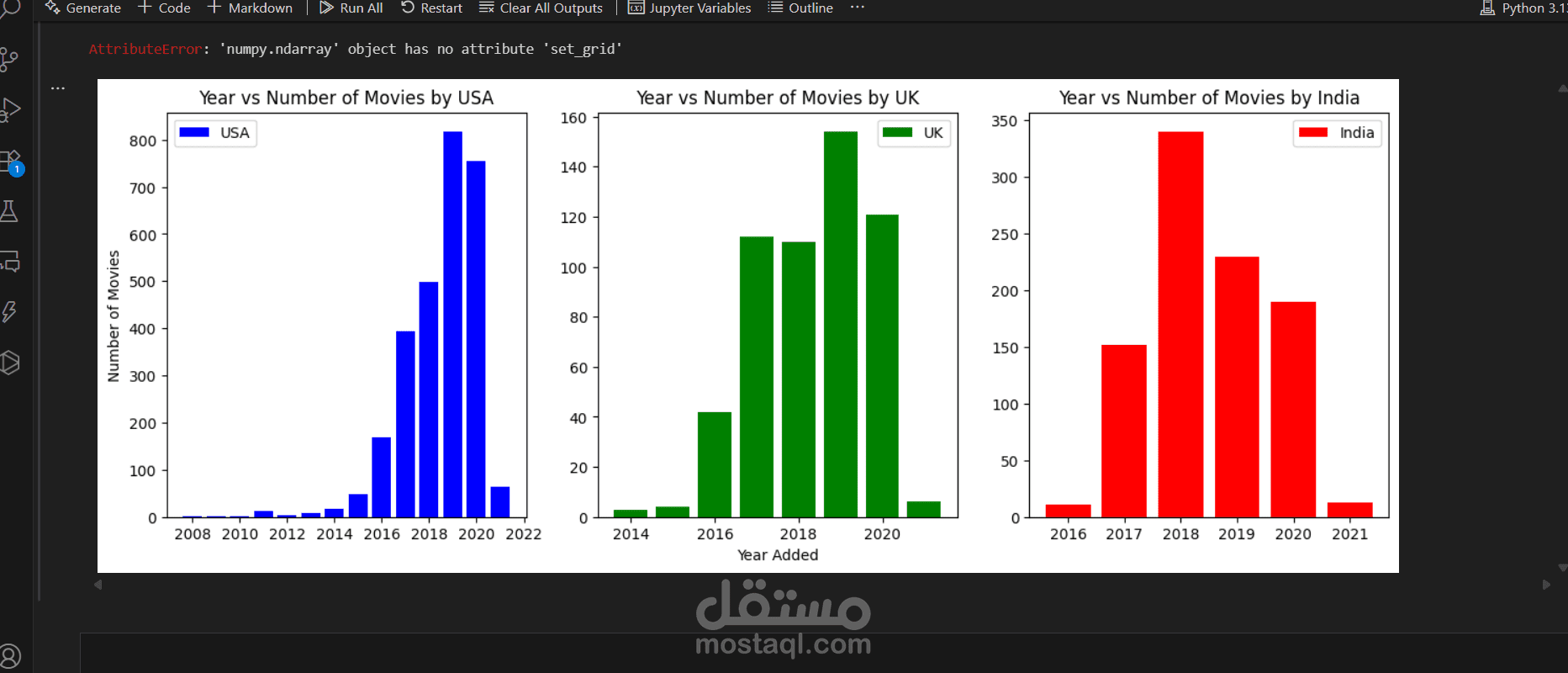
7_التحليل البصري (Data Visualization):
**استخدمت مكتبات زي:
- matplotlib و seaborn للرسوم البيانية.
- plotly للتفاعلية (لو حبيت).
- رسم المخططات (Bar charts, Pie charts, Line charts) لعرض:
- التوزيع حسب الفئات.
- الاتجاهات الزمنية.
- النسب المئوية.
النتيجة:
وصلت لداشبورد/رسوم بصرية بتوضح أهم المؤشرات (KPIs).
التحليل ساعد في استخراج Insights