Handwritten Character Recognition
تفاصيل العمل
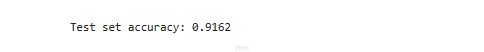



- تحميل وتجهيز البيانات:
جلب البيانات: تم استدعاء مجموعة بيانات MNIST وتحويلها إلى مصفوفات NumPy.
تجهيز التصنيفات: تم تحويل التسميات (Labels) إلى أعداد صحيحة لاستخدامها في التصنيف متعدد الفئات.
2- عرض عينة من الأرقام:
تعريف دالة العرض: أنشأنا دالة plot_digit لإعادة تشكيل المصفوفة المكونة من 784 عنصرًا إلى صورة بحجم 28x28 بكسل.
عرض مثال: تم عرض الرقم رقم 36,001 من البيانات للتأكد من سلامة البيانات.
3- تقسيم البيانات:
تجزئة البيانات: تم تقسيم مجموعة البيانات إلى بيانات تدريب وبيانات اختبار، مع تخصيص 10,000 عينة للاختبار.
4- تدريب النموذج:
تهيئة النموذج: تم تدريب نموذج الانحدار اللوجستي (Logistic Regression) على كامل بيانات التدريب لتصنيف الأرقام (0–9).
5- التنبؤ برقم واحد:
توقع النموذج: تنبأ النموذج بالتصنيف الصحيح للرقم رقم 36,001 وعرض النتيجة.
6- التحقق المتقاطع (Cross-Validation):
تقييم الأداء: تم قياس دقة النموذج باستخدام Cross-Validation على بيانات التدريب، وحساب متوسط الدقة.
7- التنبؤ بعدة عينات:
اختبار عينات عشوائية: تم اختيار عدة أمثلة عشوائية من بيانات الاختبار، والتنبؤ بالنتائج.
المقارنة: تم عرض القيم الحقيقية مقابل القيم المتوقعة مع إظهار الصور.
8- التقييم على مجموعة الاختبار:
دقة النموذج: تم اختبار النموذج على مجموعة الاختبار الكاملة وعرضت نسبة الدقة النهائية.