Spam Email Detection
تفاصيل العمل
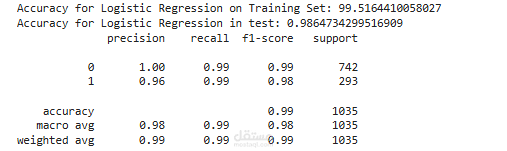

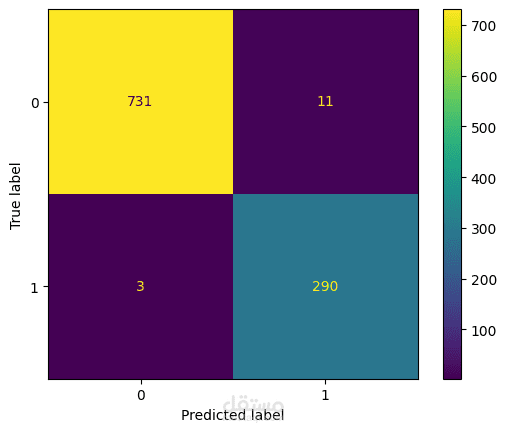
التحليل الاستكشافي ومعالجة البيانات (EDA & Preprocessing):
استيراد المكتبات:
تم استخدام مكتبات NumPy و Pandas لمعالجة البيانات، بالإضافة إلى مكتبة Matplotlib و Seaborn لعرض الرسوم البيانية وتحليل البيانات. كما تم الاعتماد على مكتبة NLTK لمعالجة اللغة الطبيعية (تنقية النصوص، إزالة الكلمات الشائعة، واستخدام خوارزمية Stemming).
تنظيف البيانات ومعالجة النصوص:
إزالة علامات الترقيم والأحرف غير المهمة.
تحويل النصوص إلى أحرف صغيرة لتوحيد الشكل.
إزالة الكلمات الشائعة (Stopwords) التي لا تضيف معنى مهم.
تطبيق خوارزمية Porter Stemmer لاستخراج جذر الكلمات.
الهدف من المعالجة:
تجهيز النصوص لتصبح قابلة للاستخدام في خوارزميات التعلم الآلي بحيث يسهل على النموذج التمييز بين الرسائل العشوائية (Spam) والرسائل السليمة (Ham).
آلية عمل المشروع:
يتم إدخال الرسالة النصية إلى النظام.
يقوم النظام بتحليل محتوى الرسالة بعد المعالجة المسبقة.
إذا احتوت الرسالة على مؤشرات لبريد عشوائي (مثل كلمات ترويجية أو روابط مشبوهة)، يتم تصنيفها على أنها Spam.
إذا كانت طبيعية وخالية من هذه المؤشرات، يتم تصنيفها على أنها Ham (رسالة سليمة).
النتيجة المتوقعة:
الرسائل العشوائية (Spam): يتم اكتشافها وتصنيفها تلقائيًا كرسائل غير مرغوبة.
الرسائل السليمة (Ham): يتم تسليمها بشكل طبيعي إلى صندوق الوارد.