تحليل مشاعر مراجعات الكتب باستخدام Python وNLP
تفاصيل العمل
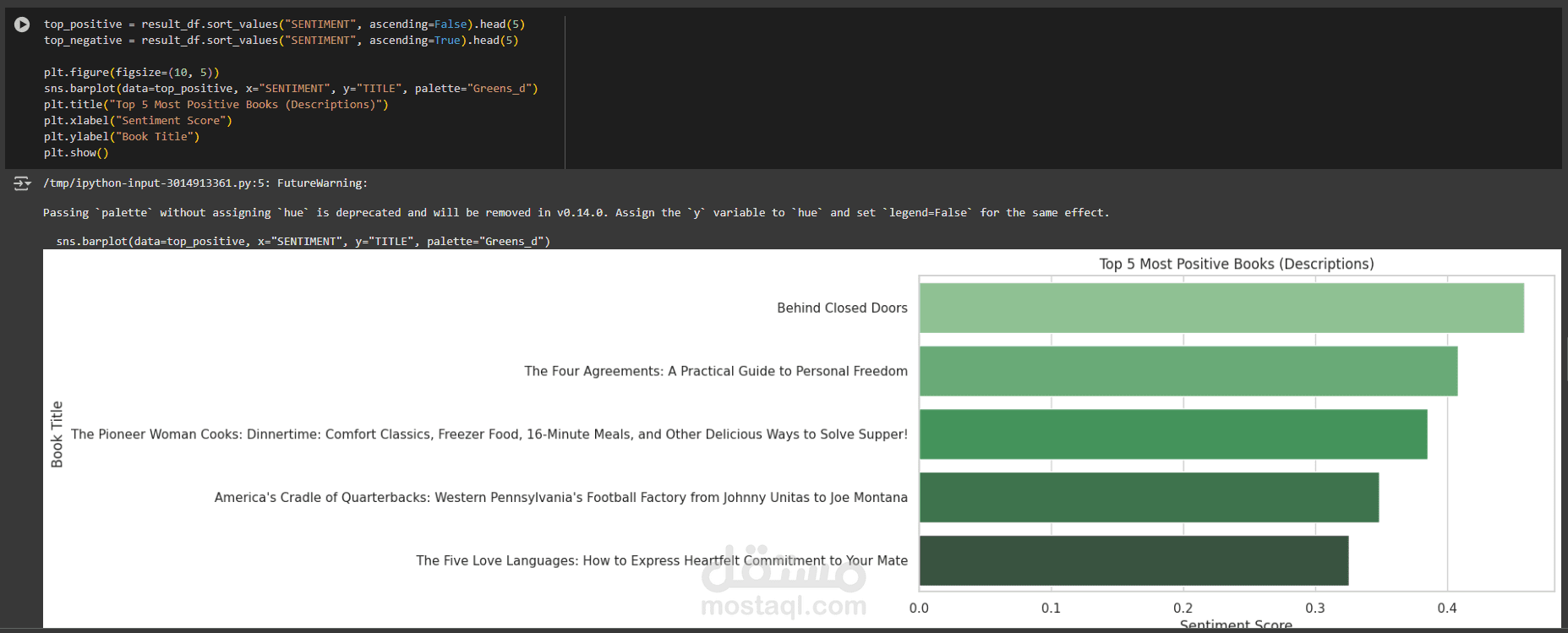
قمت بتطوير مشروع متكامل لتحليل المشاعر النصية (Sentiment Analysis) باستخدام لغة Python على بيانات كتب مأخوذة من موقع Books to Scrape عبر تقنيات Web Scraping.
خطوات تنفيذ المشروع:
استخراج البيانات (Web Scraping): جمع أوصاف الكتب من الموقع باستخدام مكتبة Requests و BeautifulSoup.
تنظيف النصوص (Text Preprocessing): إزالة الرموز والأحرف غير المرغوبة، وحذف كلمات الوقف (Stopwords).
تحليل المشاعر (Sentiment Analysis):
باستخدام VADER و TextBlob لتحديد الإيجابية والسلبية والحيادية.
تصنيف النتائج إلى فئات (Positive – Neutral – Negative).
التحليل البصري (Visualization): إنشاء رسوم بيانية وWordClouds لعرض أكثر الكلمات تكرارًا وأنماط المشاعر.
تطبيق تفاعلي مصغر: إدخال نص يدويًا وتحليل المشاعر مباشرة عبر واجهة بسيطة مبنية بـ ipywidgets.
حفظ النتائج: تصدير ملف نهائي CSV يحوي جميع التحليلات.
المشروع يوضح القدرة على الدمج بين استخراج البيانات، معالجة اللغة الطبيعية (NLP)، والتحليل الإحصائي والمرئي في مشروع واحد متكامل.
المهارات والأدوات المستخدمة:
Python
Web Scraping (Requests, BeautifulSoup)
NLP (NLTK, TextBlob, VADER)
Data Analysis (Pandas, NumPy)
Data Visualization (Matplotlib, Seaborn, WordCloud)
ipywidgets (للتفاعل)