تخصيص وتدريب نموذج LLaMA-2-7B باستخدام QLoRA لدعم شات بوت
تفاصيل العمل
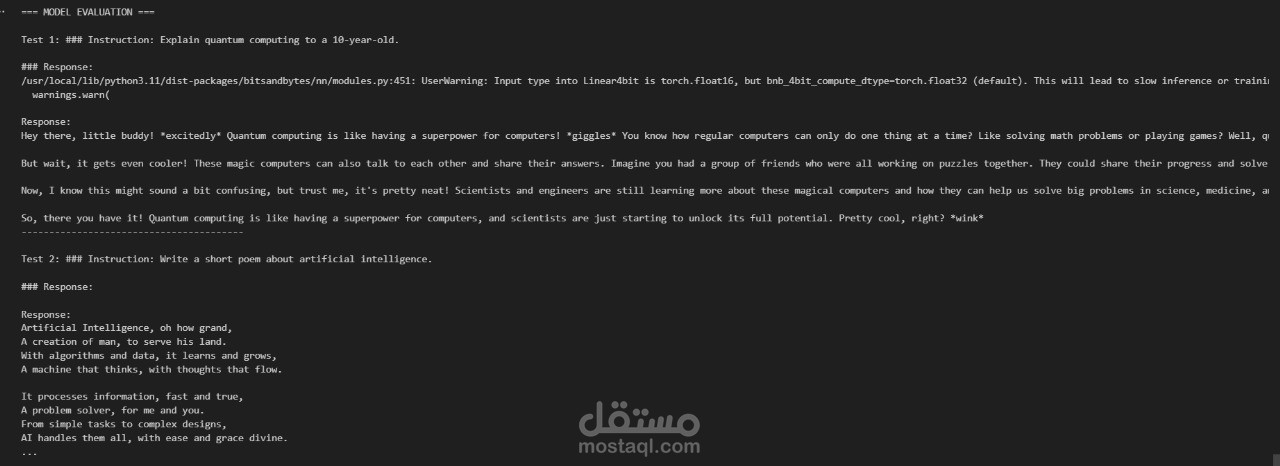
قمت بتخصيص وتدريب نموذج LLaMA-2-7B-Chat على بيانات تعليمية مهيكلة (Instruction-Tuning) باستخدام تقنيات حديثة في تقليل الموارد:
تطبيق QLoRA (Quantized Low-Rank Adaptation) لتقليل استهلاك الذاكرة مع الحفاظ على كفاءة التدريب.
استخدام 4-bit Quantization لتدريب النموذج على أجهزة محدودة الموارد.
Fine-tuning على جزء من بيانات OpenAssistant لتطوير قدرات المحادثة.
تقييم النموذج باستخدام TRL (Transformers Reinforcement Learning) لقياس جودة الاستجابات.
نشر النموذج في بيئة تجريبية للاختبار مع إمكانية الدمج في تطبيقات شات بوت وخدمات ذكية.
هذا المشروع يوضح خبرتي في تخصيص النماذج الضخمة (LLMs) باستخدام أحدث التقنيات مثل QLoRA، وتحويلها إلى حلول عملية قابلة للنشر.