Books web scrapping using python
تفاصيل العمل
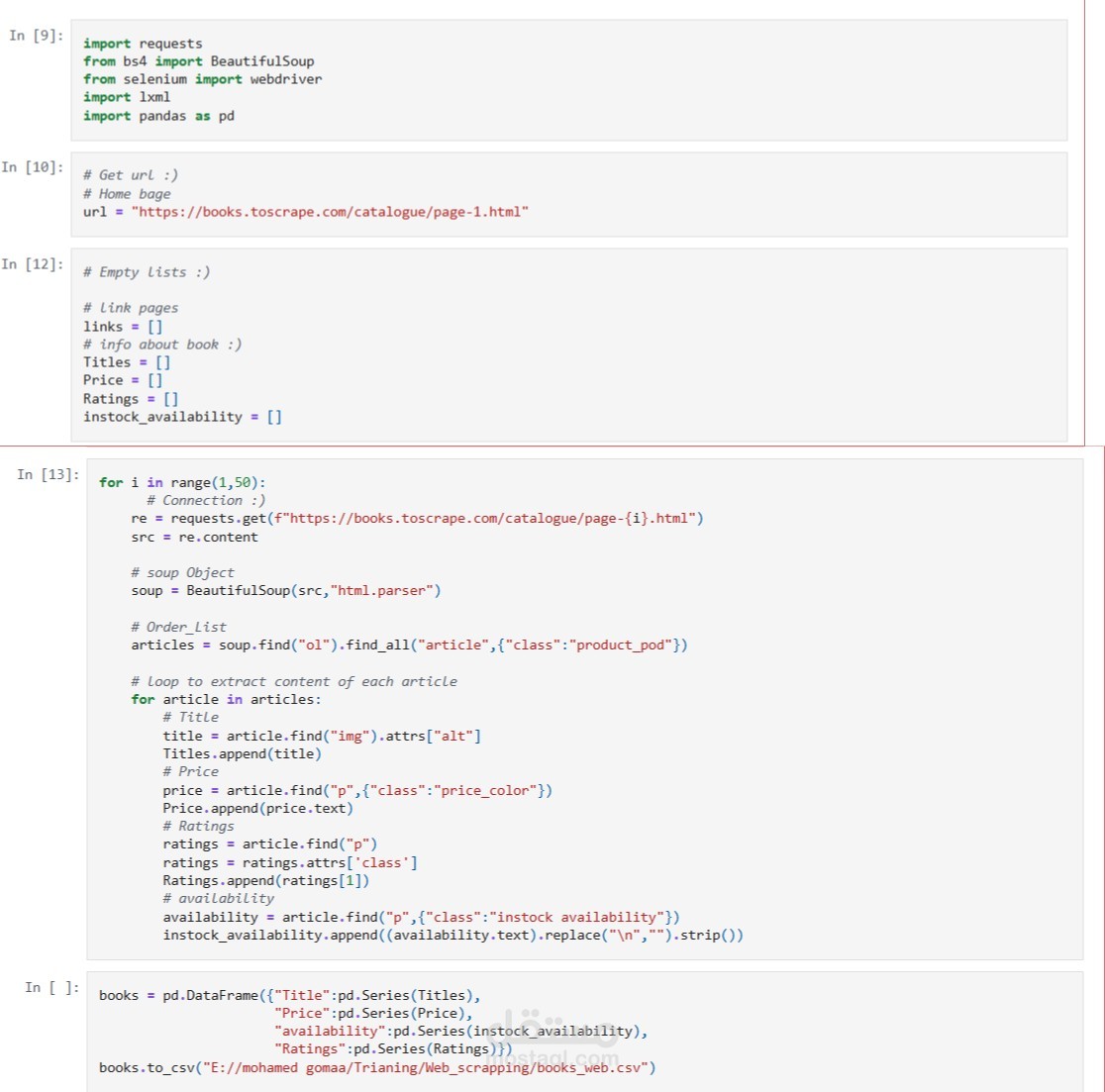
عملية Web Scraping لجمع بيانات من موقع "Books to Scrape" الذي يحتوي على قائمة كتب مع أسعارها وتقييماتها وحالة توفرها، ثم حفظ هذه البيانات في ملف CSV لاستخدامها لاحقًا في التحليل أو عرضها. تم تنفيذ المشروع بلغة Python باستخدام مكتبات requests وBeautifulSoup وpandas.
ميزاته:
1. استخراج بيانات الكتب بشكل آلي بدلًا من جمعها يدويًا.
2. جمع معلومات متعددة لكل كتاب مثل العنوان، السعر، التقييم، وحالة التوفر.
3. المرور على عدة صفحات (من الصفحة 1 إلى الصفحة 49) للحصول على بيانات شاملة.
4. تنظيم البيانات في شكل جدول (DataFrame) يسهل تحليله أو تصديره.
5. حفظ البيانات في ملف CSV للاستخدام المستقبلي في التحليل أو العرض.
طريقة التنفيذ:
1. استدعاء المكتبات اللازمة: requests لجلب صفحات الويب، BeautifulSoup لتحليل HTML، pandas لتخزين البيانات.
2. تجهيز قوائم فارغة لتخزين بيانات كل خاصية (العنوان، السعر، التقييم، حالة التوفر).
3. استخدام حلقة تمر على صفحات الموقع من 1 إلى 49.
4. في كل صفحة:
* جلب محتوى الصفحة باستخدام requests.
* تحليل الصفحة باستخدام BeautifulSoup.
* البحث عن عناصر الكتب واستخراج المعلومات المطلوبة.
5. إضافة البيانات المستخرجة إلى القوائم المخصصة لها.
6. إنشاء DataFrame من القوائم.
7. حفظ البيانات في ملف CSV في المسار المحدد.