Diabetes EDA & Prediction
تفاصيل العمل
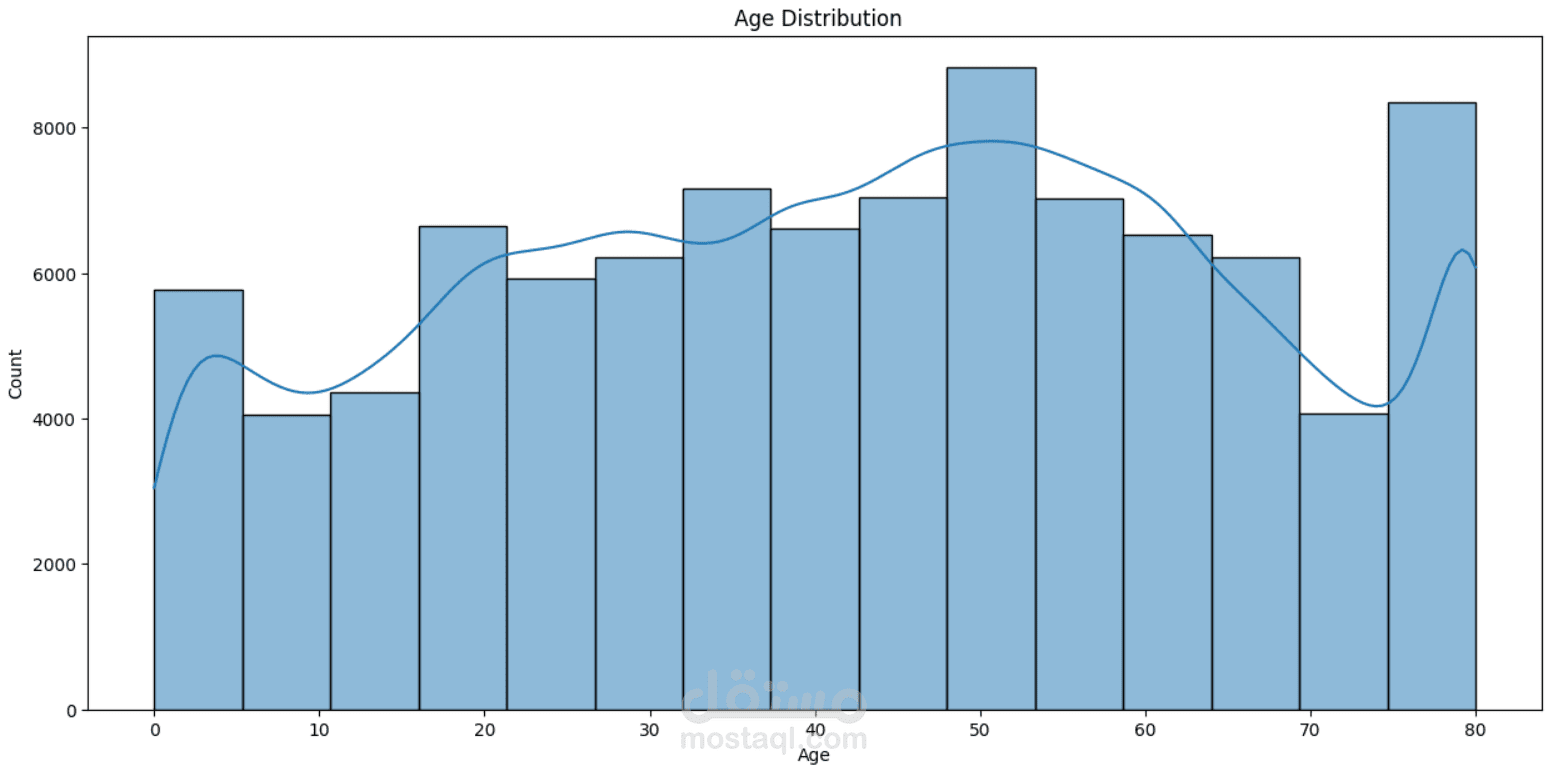
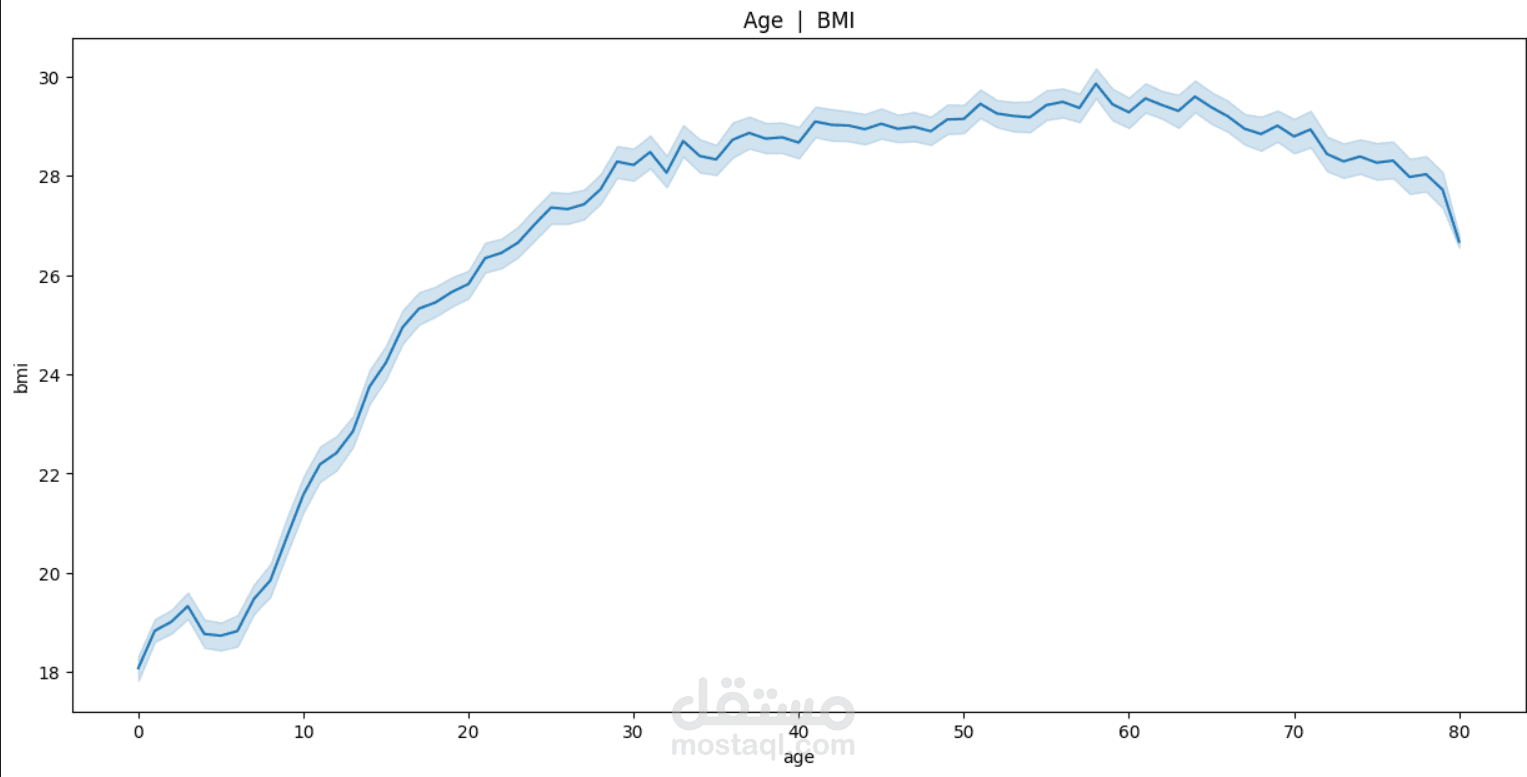
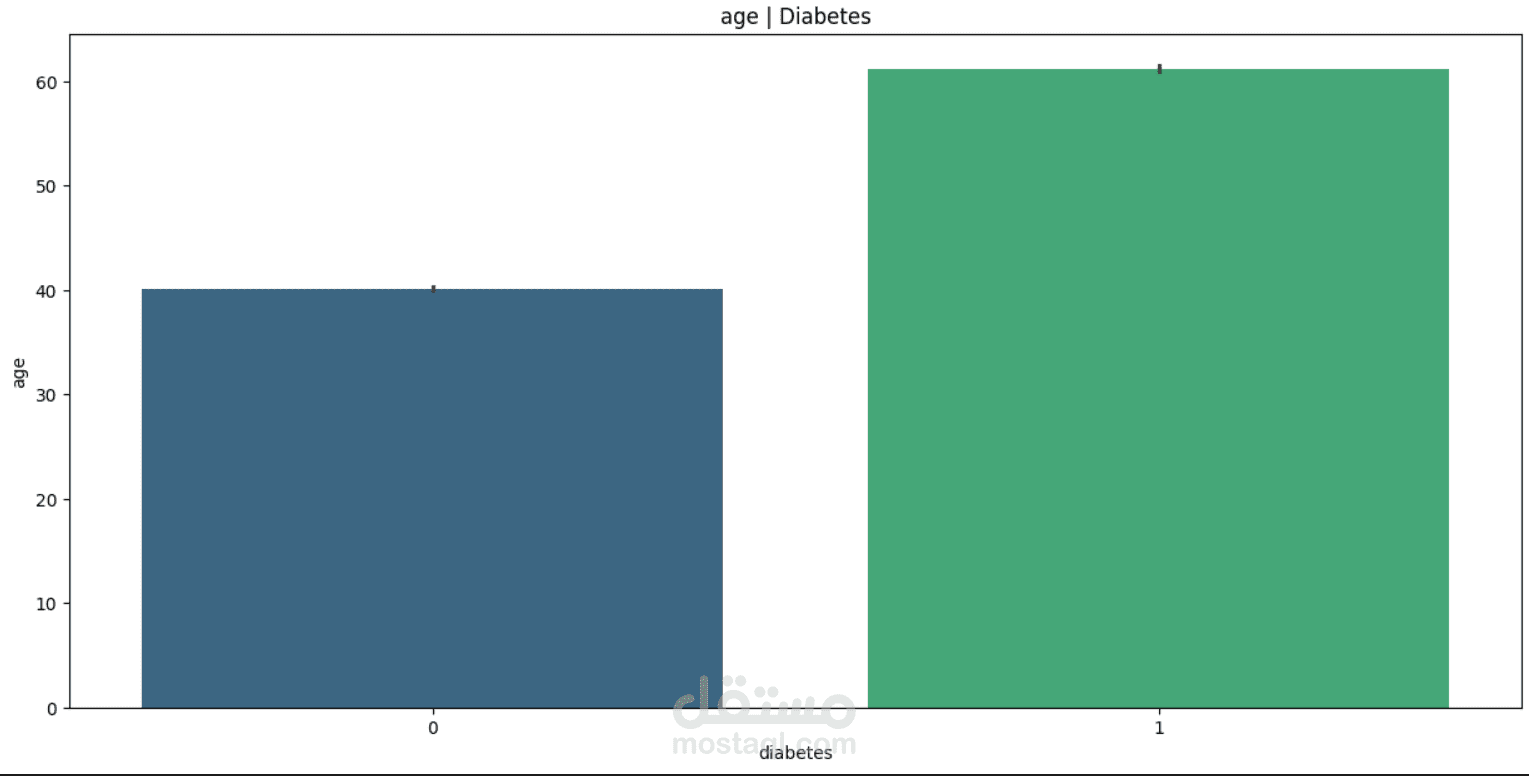
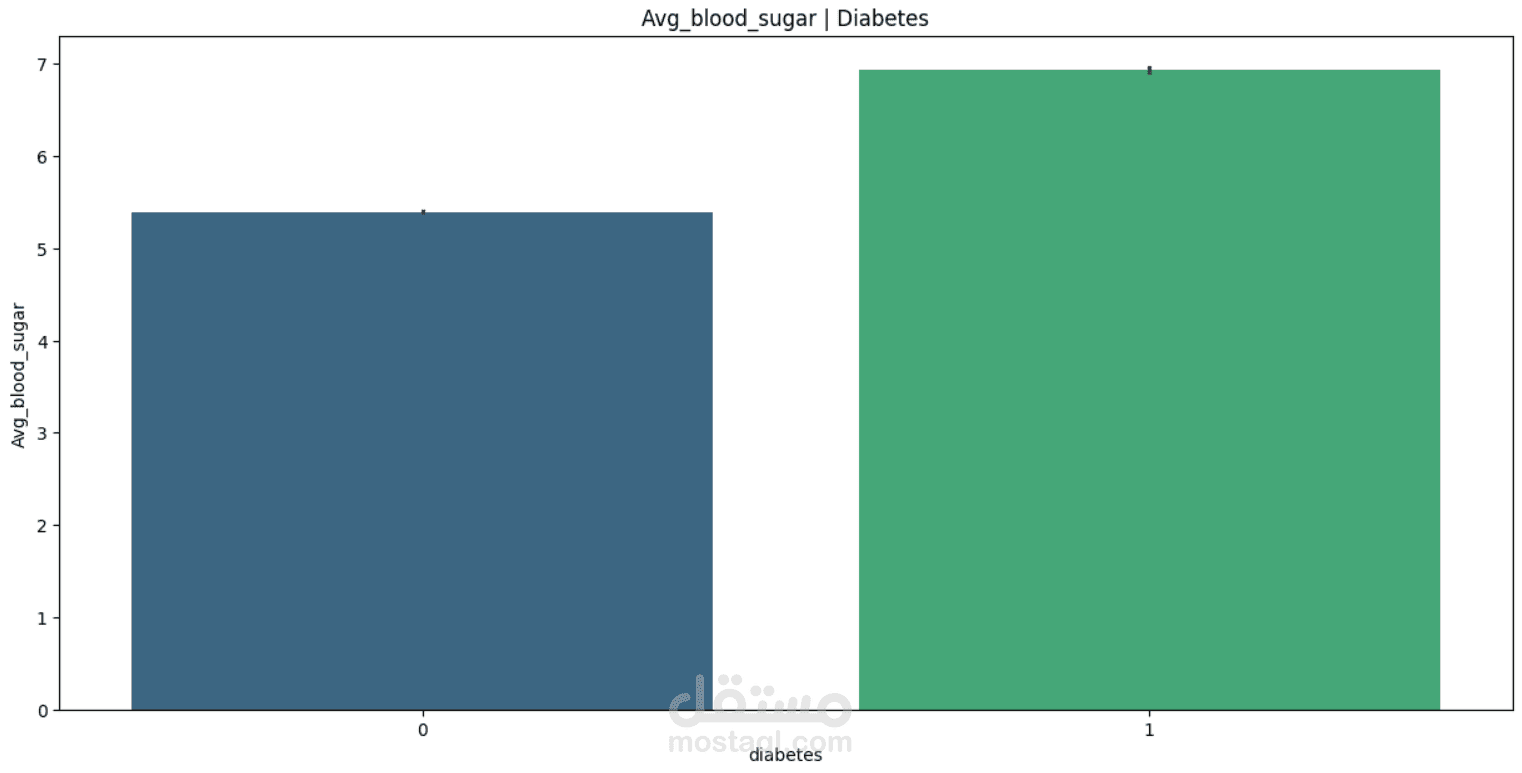
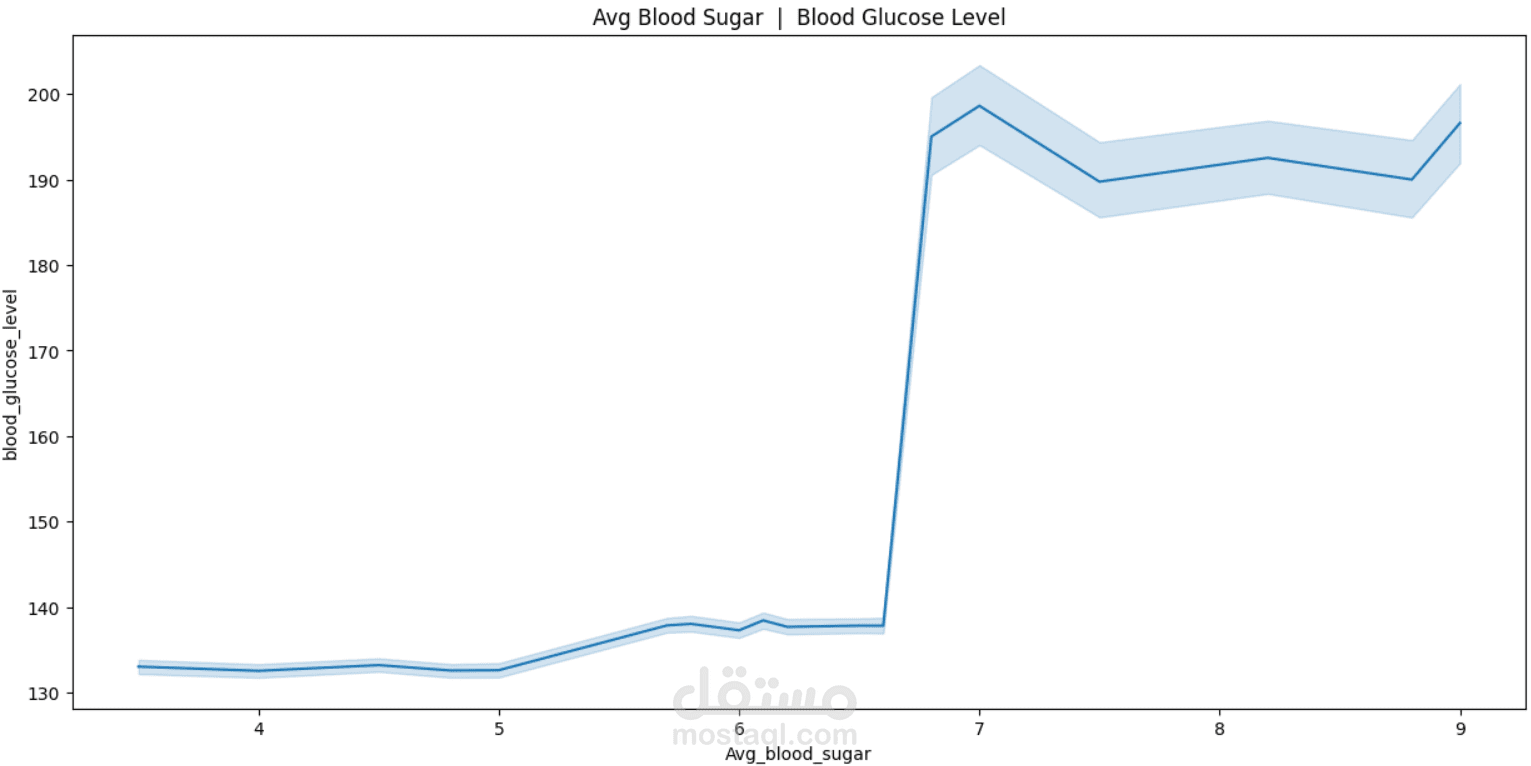
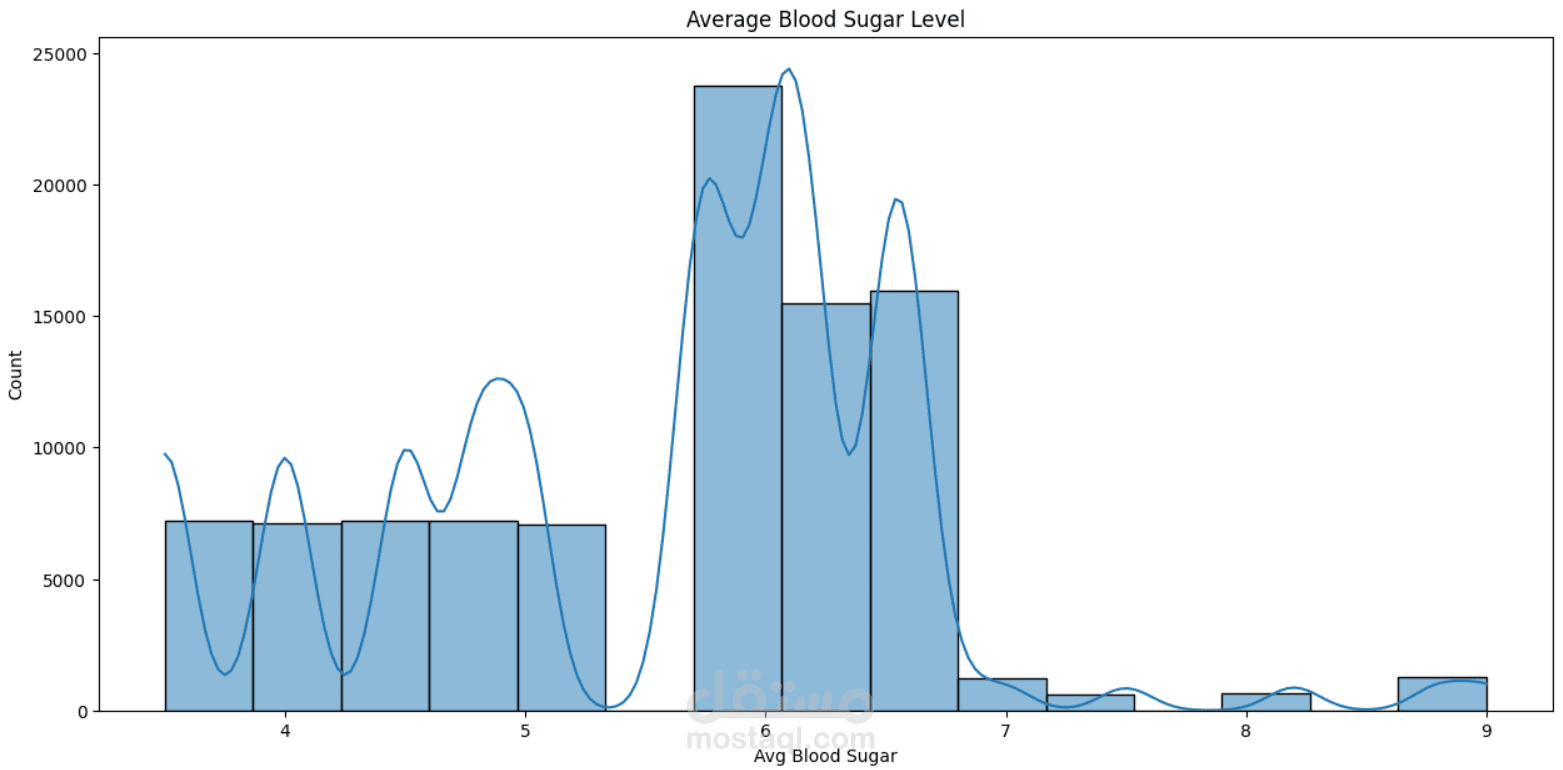
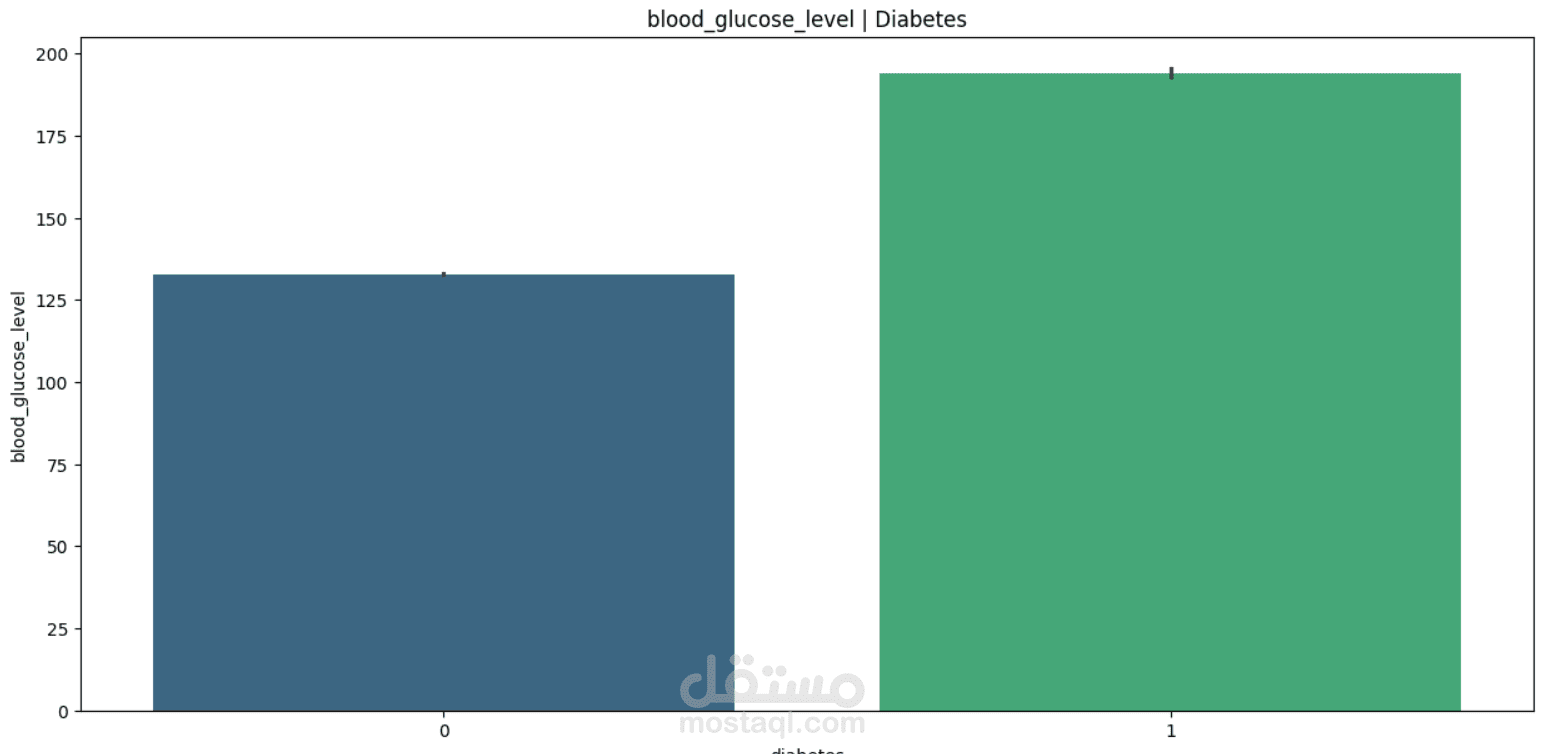
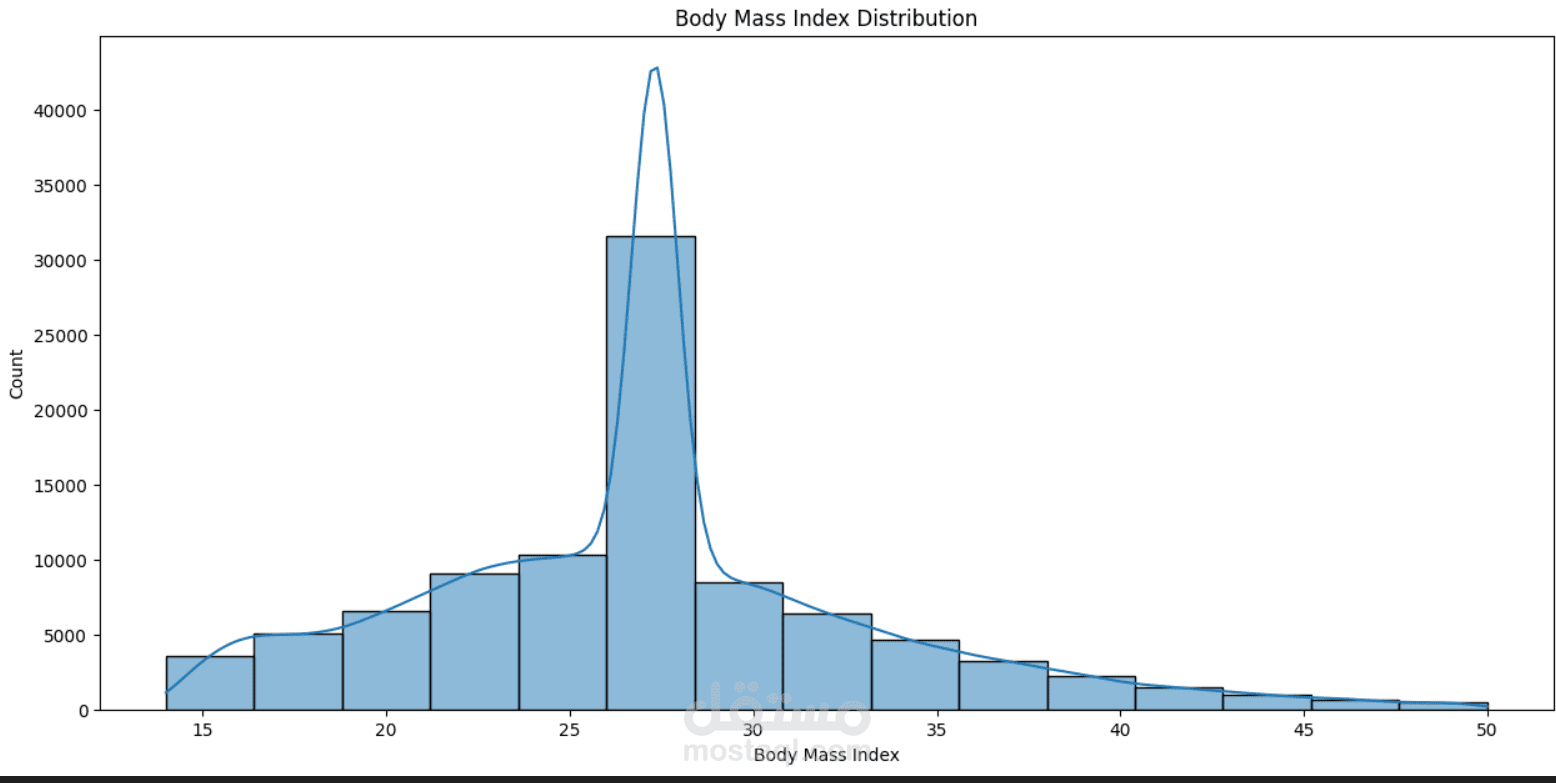
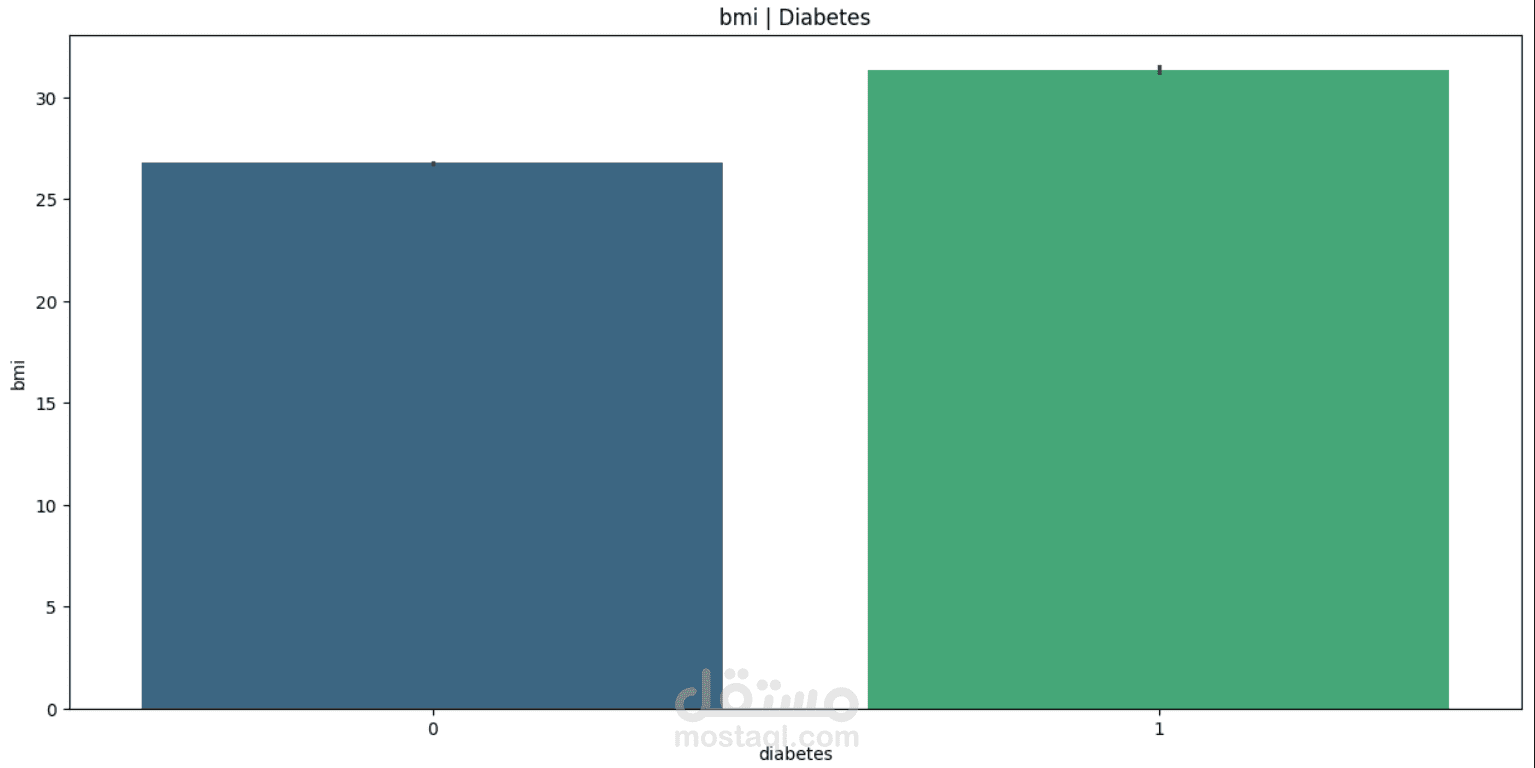
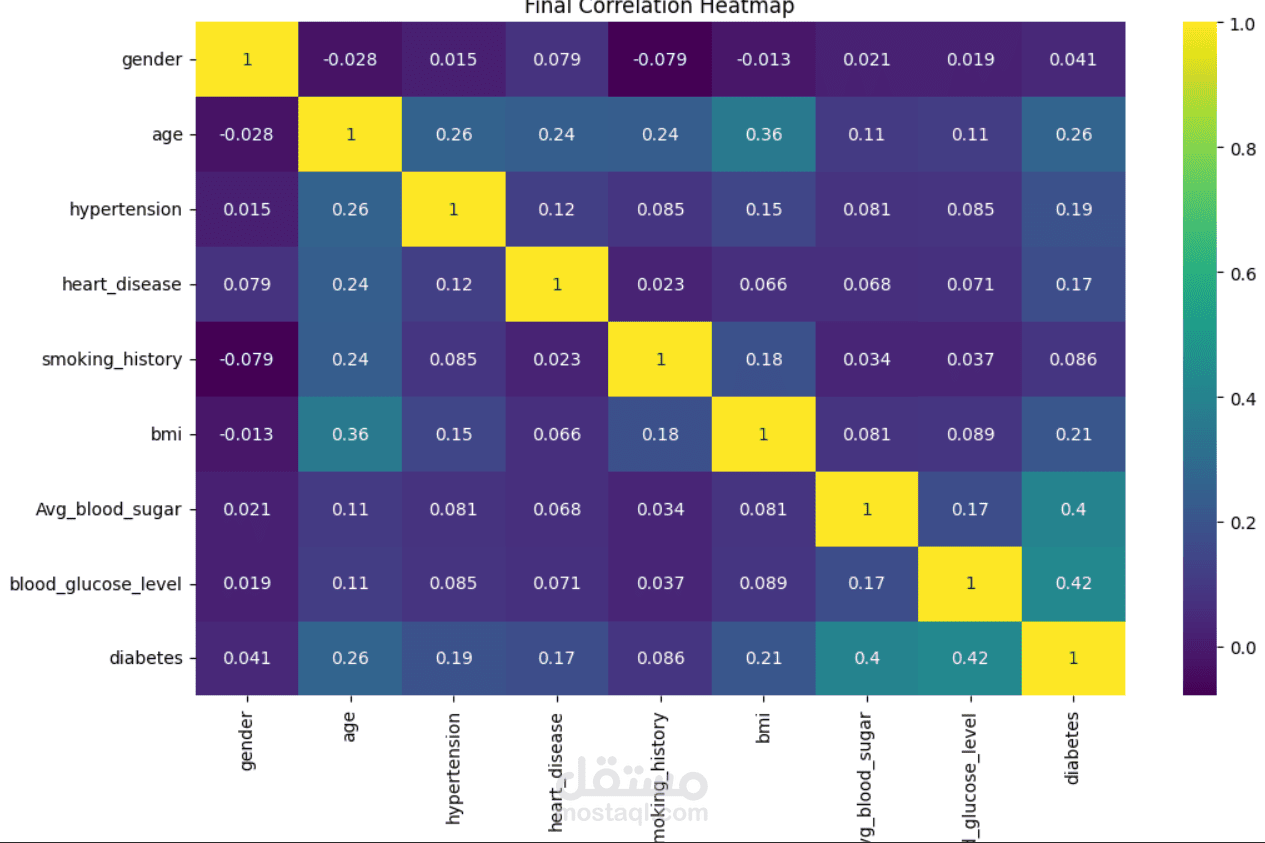
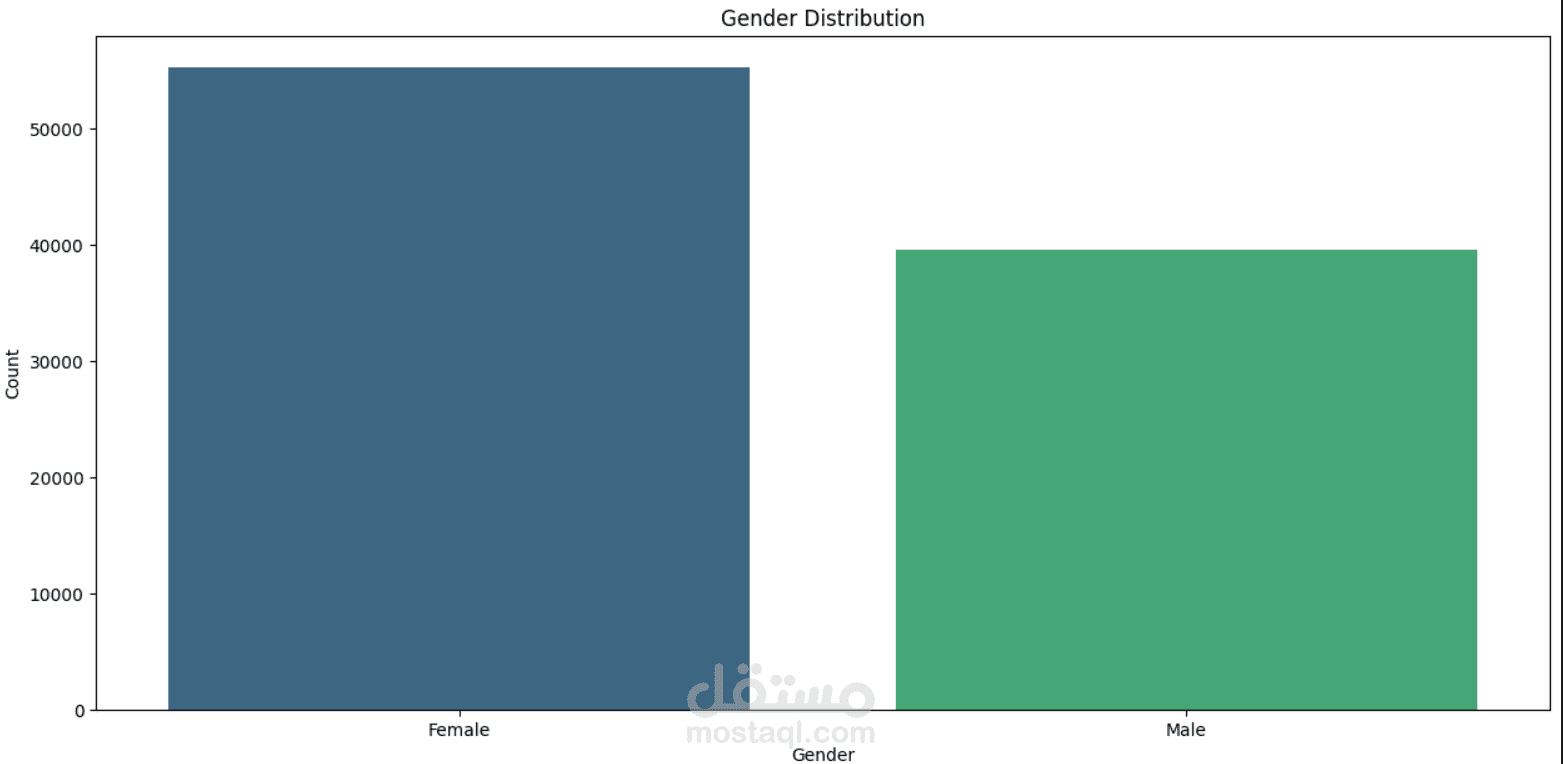
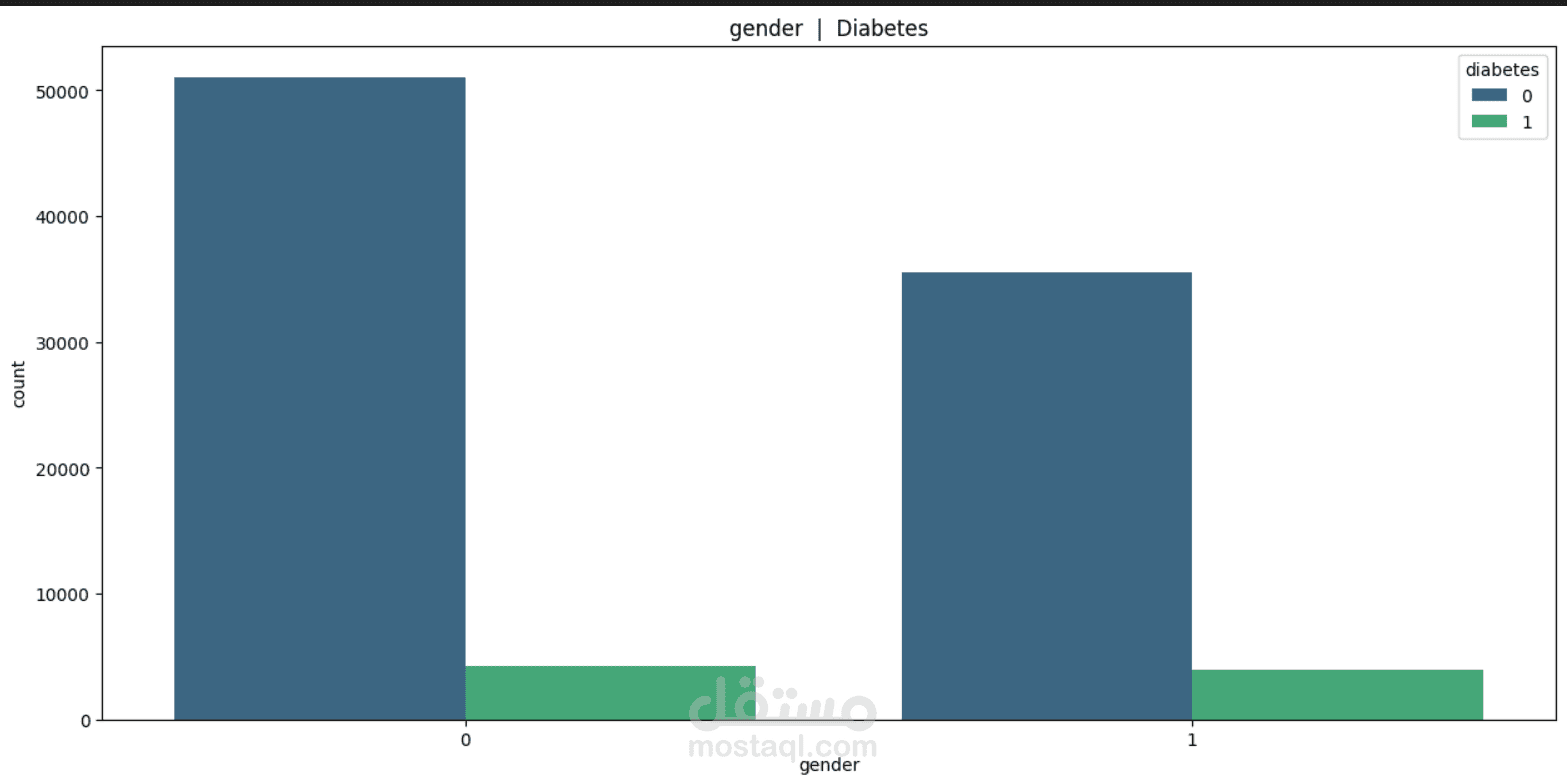
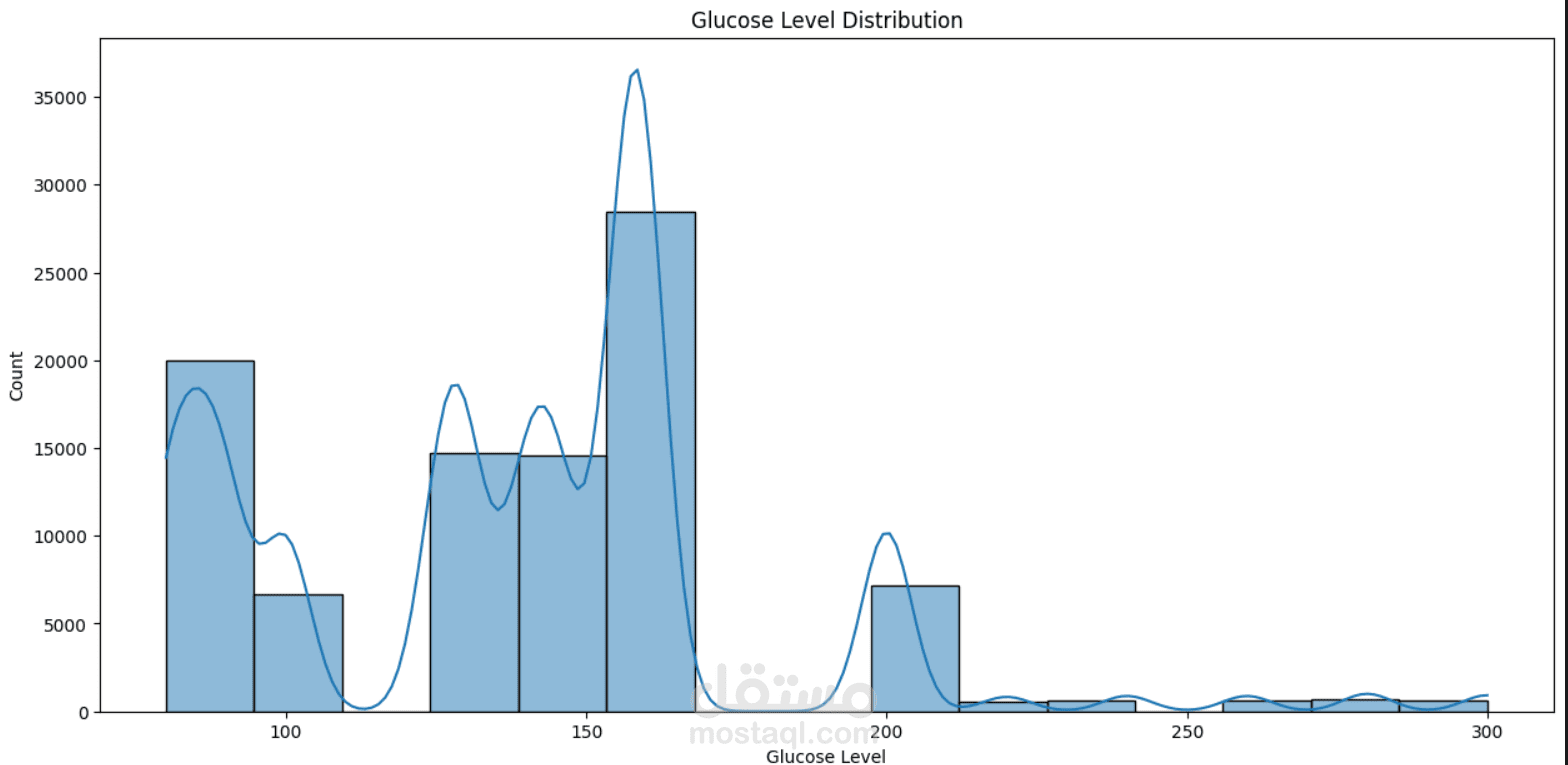
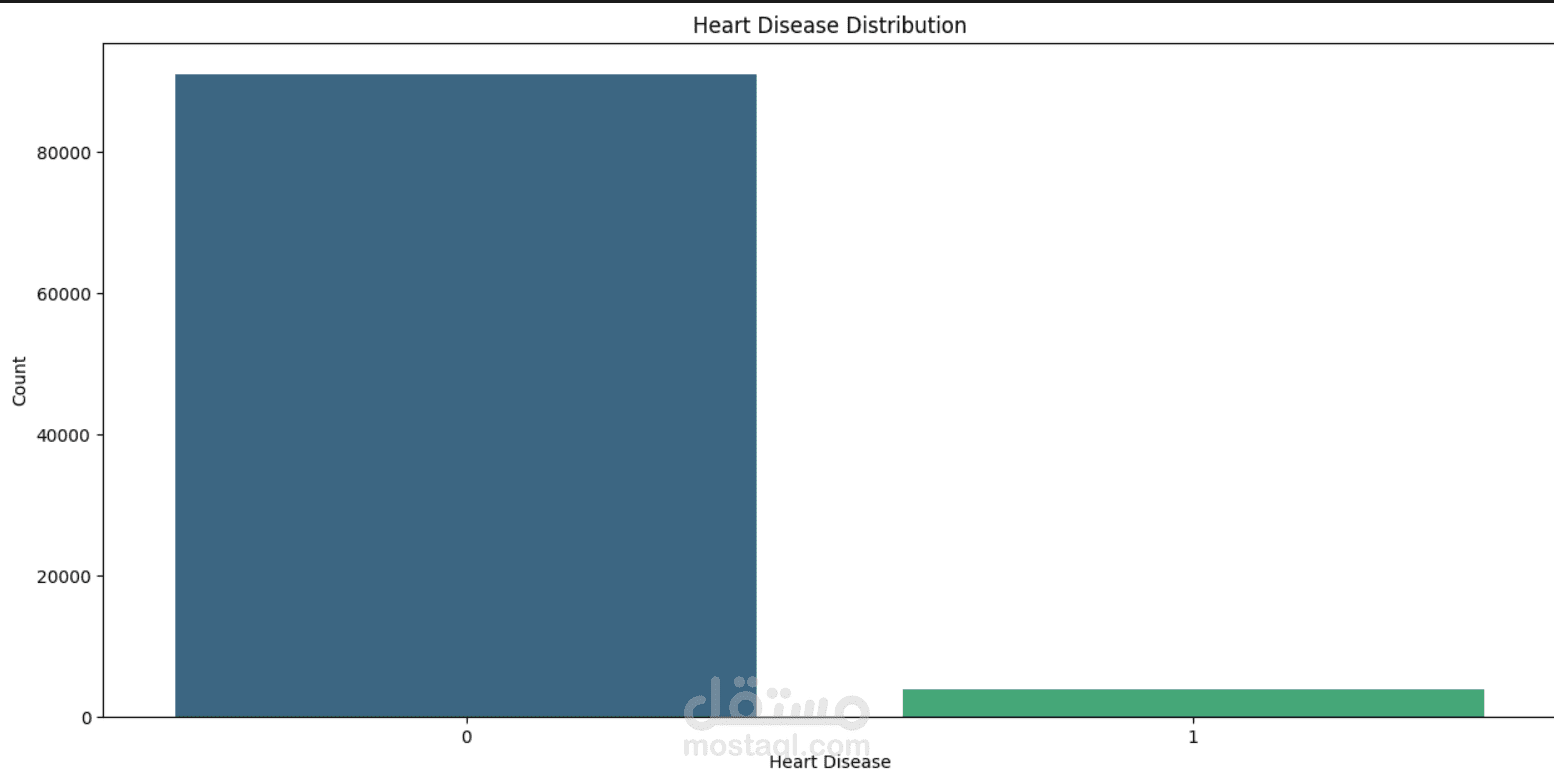
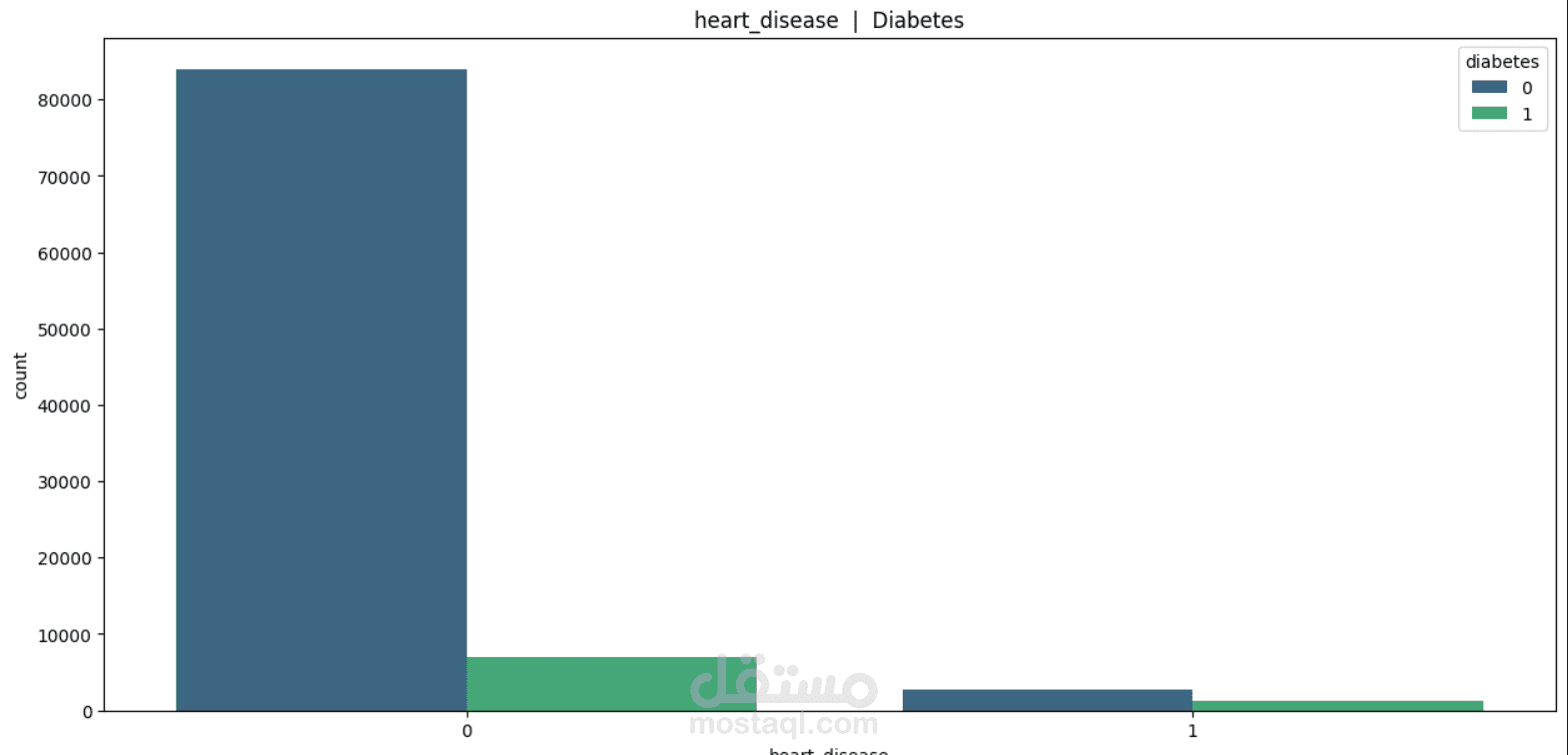
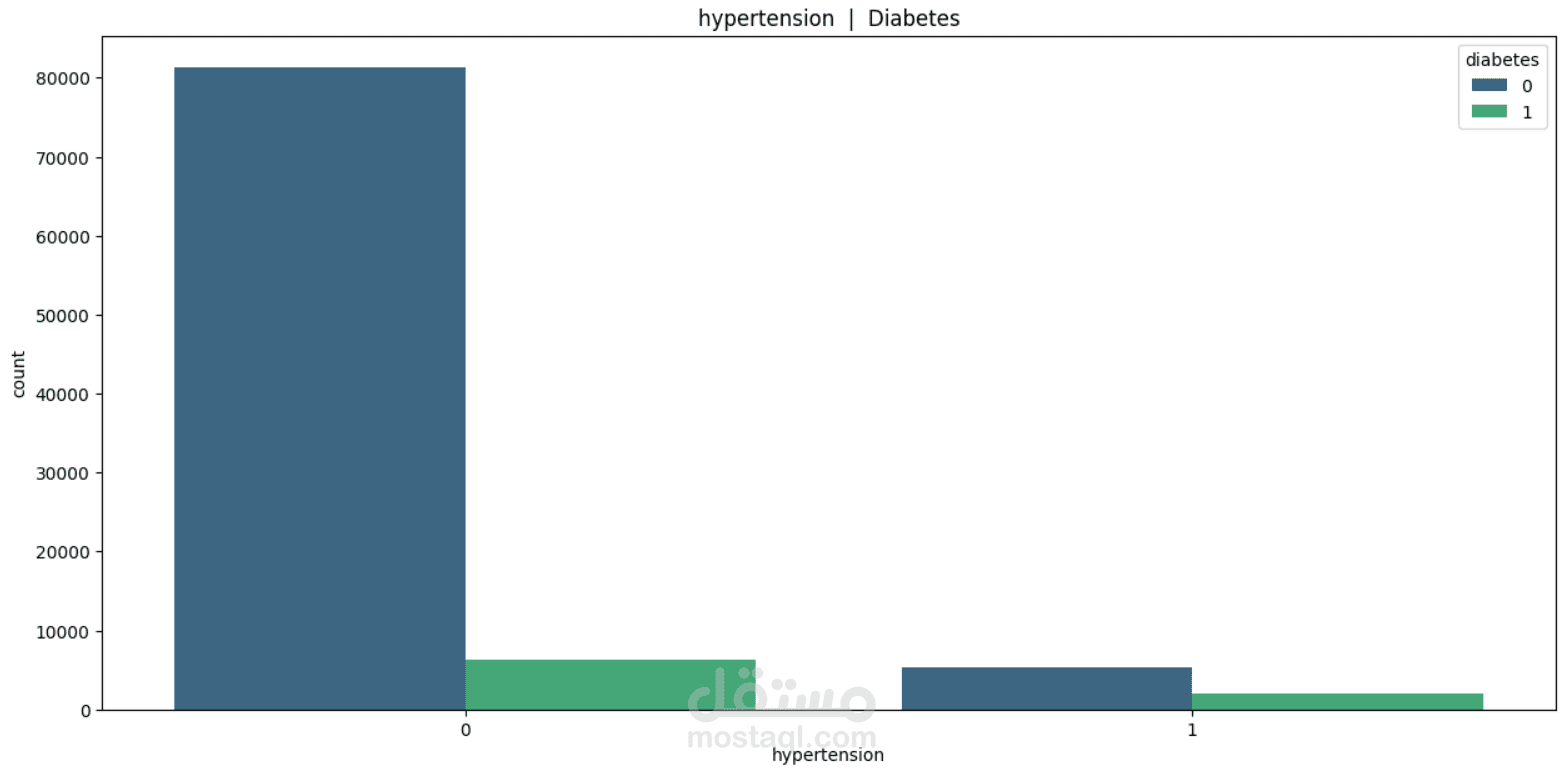
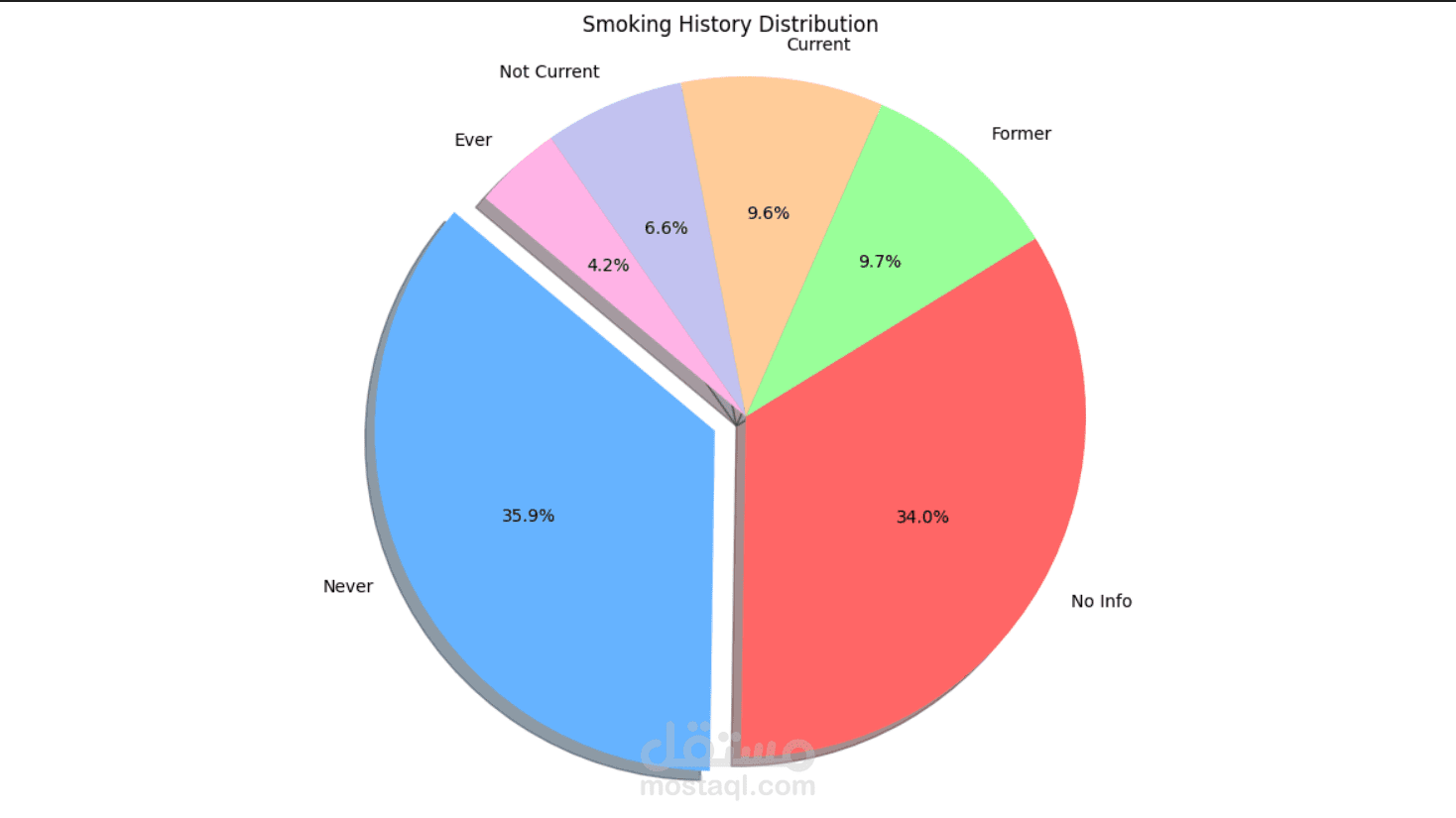
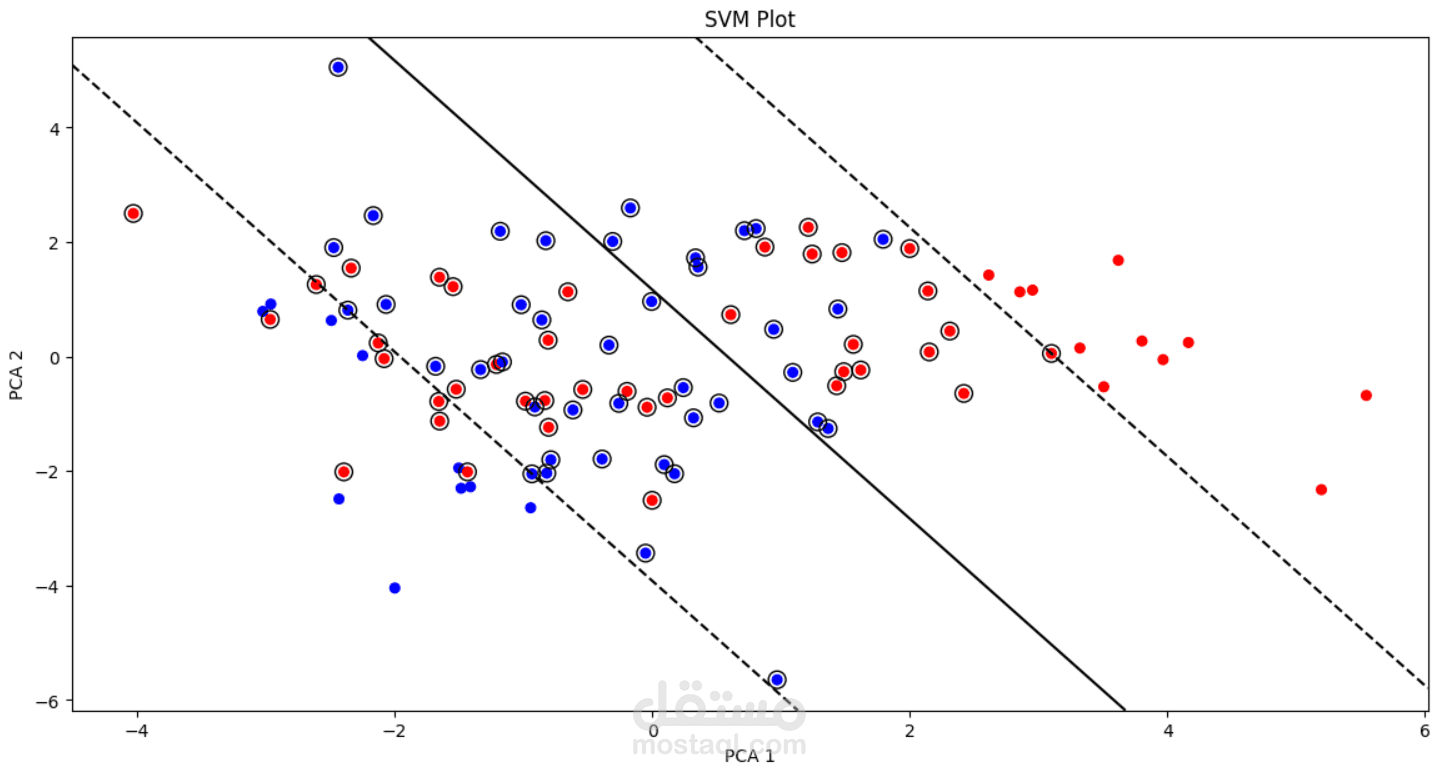
This project focuses on understanding and predicting diabetes using machine learning techniques. The process begins with Exploratory Data Analysis (EDA) to uncover patterns, relationships, and anomalies in the dataset—such as the impact of features like glucose level, BMI, age, and insulin on the likelihood of diabetes.
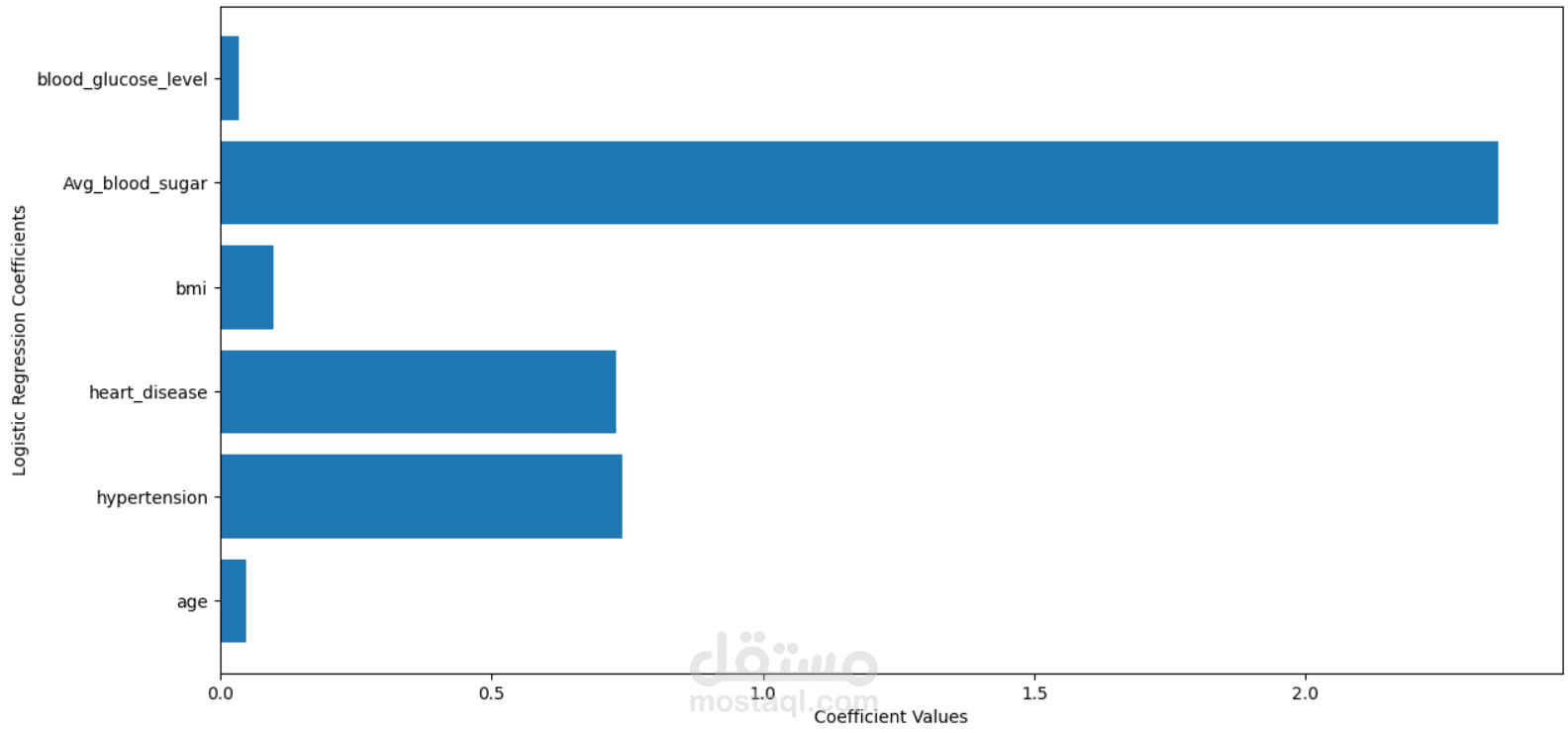
After cleaning and preprocessing the data (handling missing values, scaling, and encoding), multiple classification models were trained to predict whether an individual is diabetic or not. These included algorithms like Logistic Regression, Decision Trees, Random Forest, and Support Vector Machines. Model performance was evaluated using accuracy, precision, recall, F1-score, and ROC-AUC.
The project demonstrates how data science can be leveraged to support early diagnosis and risk assessment of diabetes, aiding in proactive healthcare management.
Evaluation:
Logistic regression: 95%
Support Vector Machine: 94%
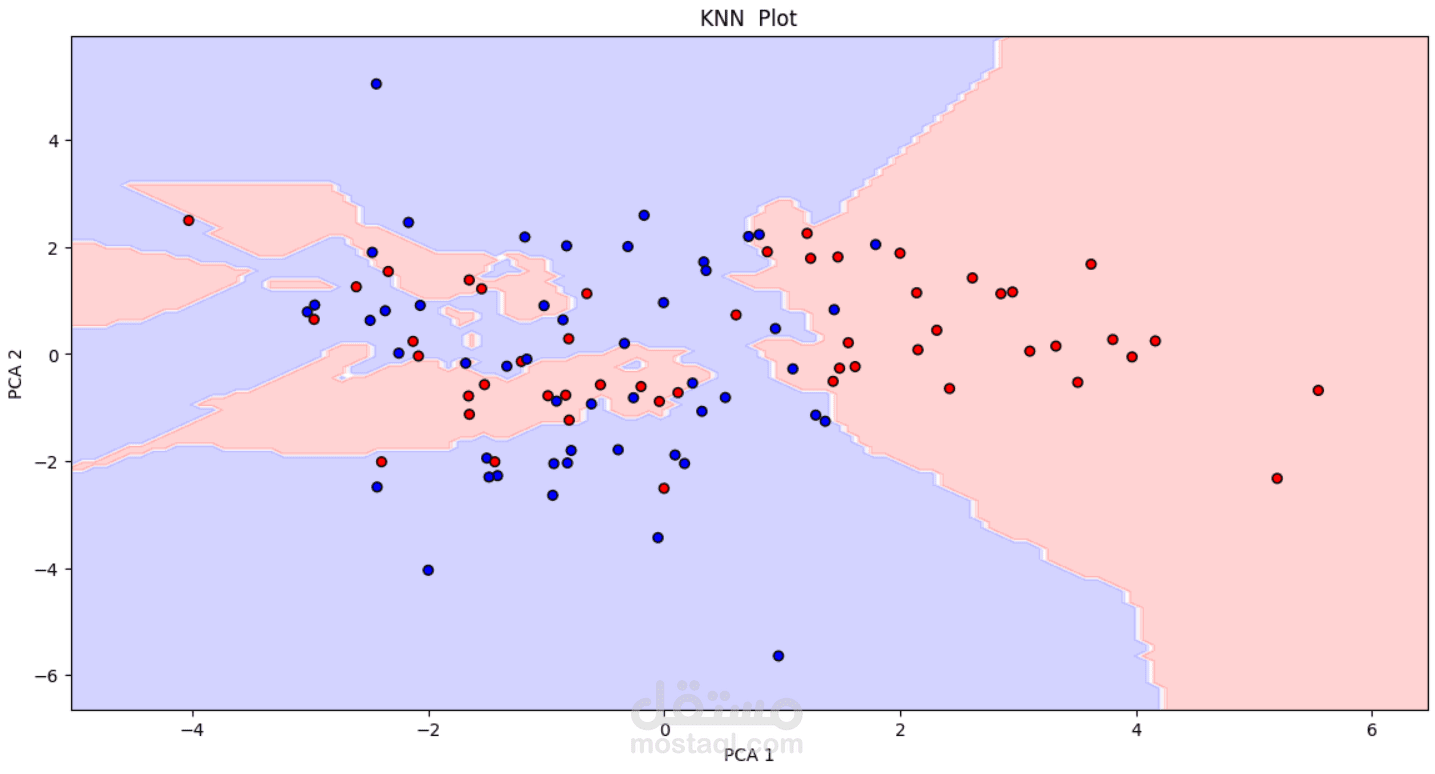
K-Nearest Neighbors: 95%
Random Forest Classifier: 96%