Heart disease detection using Tree_based model
تفاصيل العمل
في هذا المشروع، قمت بتحليل مجموعة بيانات طبية لتصنيف احتمالية الإصابة بأمراض القلب باستخدام نماذج تعلم آلي.
الخطوات المنفذة:
تنظيف البيانات ومعالجة القيم المفقودة
تحليل استكشافي لفهم العلاقات بين المتغيرات
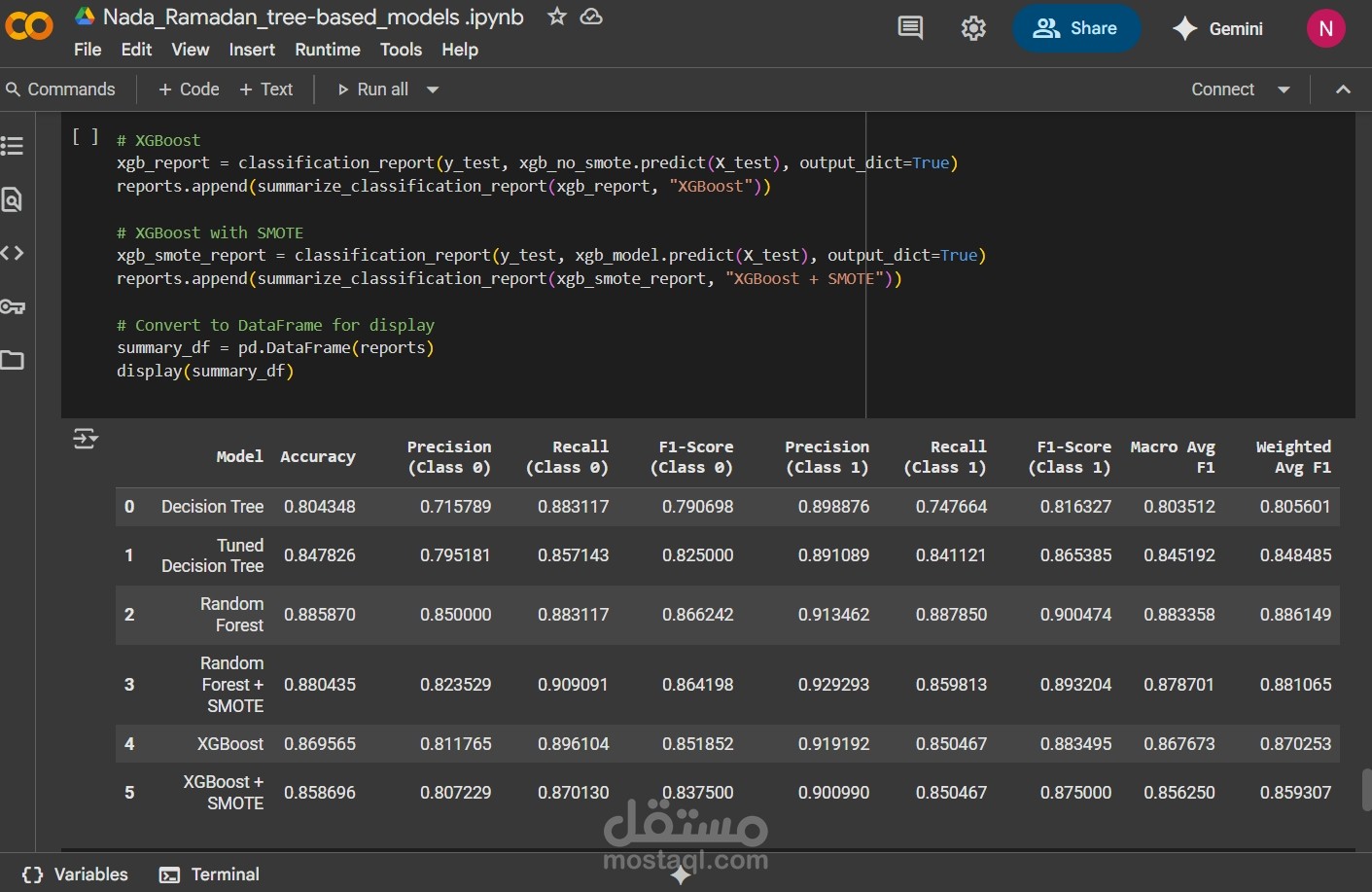
تطبيق نماذج شجرية: Decision Tree، Random Forest، XGBoost
تحسين الأداء باستخدام SMOTE وGridSearchCV
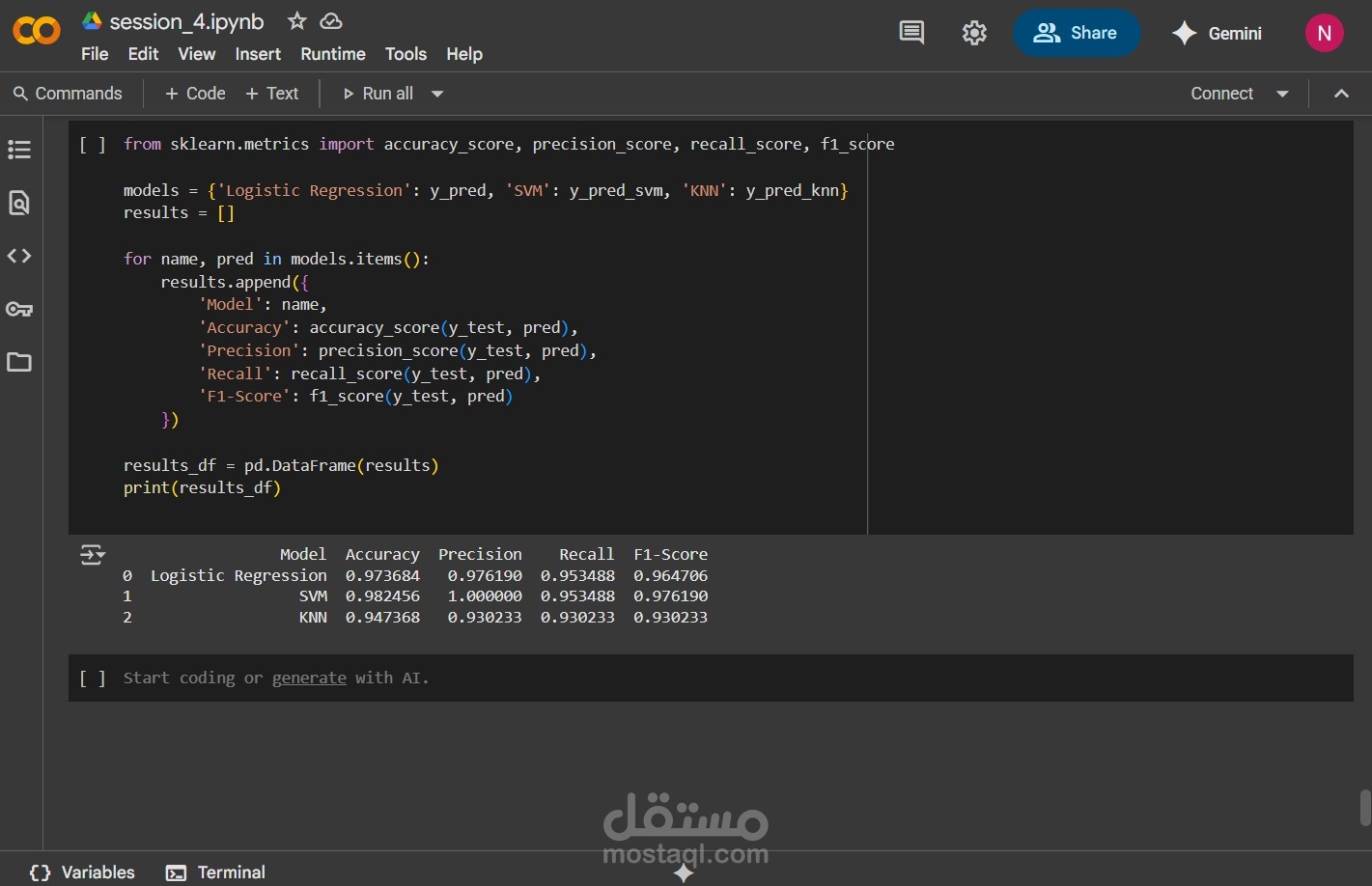
تقييم النموذج باستخدام Confusion Matrix، ROC Curve، وF1-score
استخراج أهمية الميزات لتحديد العوامل المؤثرة
الأدوات المستخدمة:
Python, Pandas, Scikit-learn, Matplotlib, Seaborn, XGBoost
النتيجة:
تم الوصول إلى دقة نموذج عالية (تجاوزت 88%) مع تفسير واضح للعوامل المؤثرة، مما يدعم اتخاذ قرارات طبية مبنية على البيانات.