Stroke Data 30 Insights Visualized with ML Model
تفاصيل العمل
Overview:
Welcome to the Stroke Data & Predictions project! This repository features a comprehensive analysis of a stroke prediction dataset, conducted as part of my NTI Data Analysis Training. The project includes detailed visualizations and a predictive model using Random Forest.
Project Highlights:
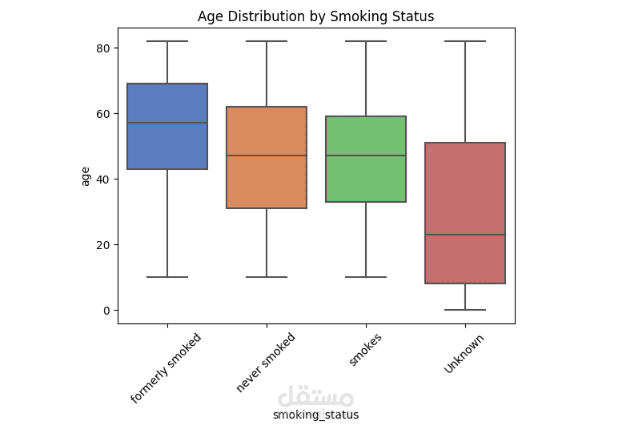
30 Key Insights: In-depth analysis with 30 visualizations revealing significant patterns related to stroke occurrences.
Predictive Modeling: Development of a Random Forest model to predict stroke likelihood based on various factors.
Key Findings: Insights into variables such as age, hypertension, glucose levels, and more.
Dataset
The dataset used in this project includes the following columns:
id
gender
age
hypertension
heart_disease
ever_married
work_type
Residence_type
avg_glucose_level
bmi
smoking_status
stroke
Analysis and Modeling
The notebook covers:
Data Preprocessing: Handling missing values, encoding categorical variables, and feature scaling.
Exploratory Data Analysis (EDA): Visualizing key insights and trends related to stroke occurrences.
Predictive Modeling: Implementing and evaluating a Random Forest model to predict stroke likelihood.