Big data analysis
تفاصيل العمل
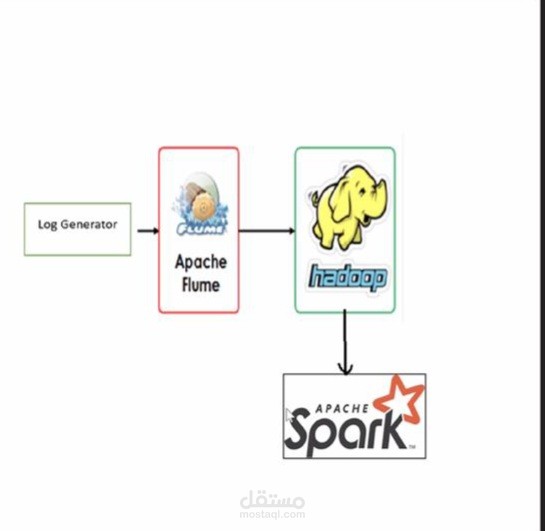
Mini Big Data Pipeline Project
Built a simple pipeline to collect and process log data. Used Apache Flume to ingest logs into HDFS, then analyzed them using Apache Spark. The project introduced me to real-time data collection and distributed processing in the Hadoop ecosystem