تحليل بيانات افلام موقع IMDB
تفاصيل العمل
ببدأ بتحميل مكتبتين numpy و pandas و matplotlib
بعد كده بيتم تحميل ملفين بيانات من نوع csv، الأول خاص ببيانات الطاقم، والتاني خاص بالأفلام
بيتم عرض أول 10 صفوف من بيانات الطاقم، وأول 5 صفوف من بيانات الأفلام
بعد كده بيتم طباعة عدد الصفوف والأعمدة في كل جدول
بيتم فحص القيم المفقودة في كل جدول، وبيظهر إن فيه أعمدة ناقصة بيانات زي homepage و tagline و overview و release_date و runtime
اللي ناقص بيتم تعويضه بكلمات بديلة أو يتم حذف الصفوف اللي فيها بيانات ناقصة
بيتم التأكد من عدم وجود صفوف مكررة
بعد كده بيتم تحويل عمود genres من نص إلى قائمة باستخدام ast
الهدف من ده هو استخراج أسماء التصنيفات بدل ما تكون مخزنة كنصوص فيها JSON
بعد كده بيتم دمج الجدولين مع بعض عن طريق عمود id، وبيتم إعادة تسمية الأعمدة الناتجة عن الدمج
بيتم حساب تقييم مرجّح لكل فيلم باستخدام معادلة IMDB
بيتم استخدام عدد الأصوات والتقييم المتوسط لكل فيلم والتقييم المتوسط العام لحساب التقييم الجديد WR
بيتم ترتيب الأفلام حسب التقييم الجديد وعرض أعلى 10 أفلام
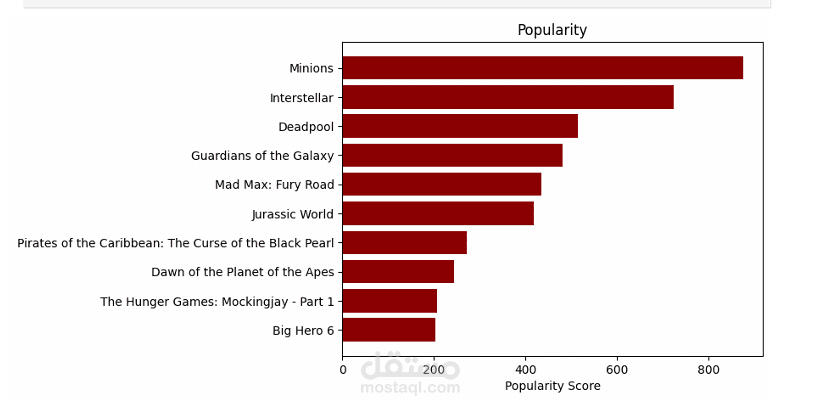
بعد كده بيتم عرض أكثر 10 أفلام شعبية بناءً على عمود popularity باستخدام رسم بياني أفقي
بيتم تحويل تاريخ إصدار الفيلم إلى نوع datetime واستخراج السنة منه
بيتم حساب أكثر السنوات اللي تم فيها إصدار أفلام، وعرضهم في رسم بياني
في النهاية بيتم تحليل العلاقة بين ميزانية الفيلم والتقييم المرجّح
بيتم رسم Scatter Plot للعلاقة دي باستخدام مقياس لوجاريتمي للمحور الأفقي الخاص بالميزانية
وبيتم تفعيل الشبكة على الرسم البياني
الدفتر كله بيهدف لتحليل بيانات الأفلام من ناحية التقييم والشعبية والتواريخ والتصنيفات والميزانية باستخدام البايثون والرسوم البيانية